8.1存储过程
8.1.1基本概念
使用 T-SQL 语言编写代码时,可以用两种方法存储和执行代码。
①在客户端存储代码,通过客户端的程序或 SQL 命令向数据库管理系统发出对数据库的操作请求,由数据库管理系统将操作结果返回给用户程序;
②以子程序的形式将程序模块存储在数据库中,供有权限的用户通过调用反复执行。
所谓存储过程,实际上是存储在数据库中供所有用户程序调用的子程序。存储过程与其他程序设计语言中的子程序很类似,因为存储过程可以:
●接收输入参数并以输出参数的形式将多个值返回给调用过程。
●包含执行数据库操作(包括调用其他存储过程)的编程语句。
●向调用过程返回状态值,以表明执行成功或失败(以及失败原因)。
使用存储过程的好处有:
(1)允许模块化程序设计。
(2)改善性能。
(3)减少网络流量。
(4)增强应用程序的安全性。
8.1.2创建、执行和删除存储过程
1.创建存储过程
创建存储过程的 SQL 语句为 CREATE PROCEDURE。其语法格式为:
CREATE { PROC | PROCEDURE } [ schema_name. ] procedure_name
[ { @ parameter [ type_schema_name. ] data_type }
[=default ] [OUT | OUTPUT ]
] [,…n] [ WITH RECOMPILE]
AS { <sql_statement> [;][…n ] }
[;]
<sql_statement>::= { [ BEGIN ] statements [ END ] } 其中各参数说明如下:
⚫ schema_name:过程所属的架构名。
⚫ procedure_name :存储过程名,该名称在架构中必须唯一。
⚫ @ parameter:存储过程的参数。在创建存储过程时可以声明一个或多个参数。除非定义了参数的默认值或者将参数设置为等于另一个参数,否则用户在调用存储过程时必须为每个声明的参数提供值。一个存储过程最多可以有 2100 个参数。
⚫ [ type_schema_name. ] data_type:参数以及所属架构的数据类型。所有数据类型都可以用作
存储过程的参数。
⚫ Default:参数的默认值。如果定义了 default 值,则在调用存储过程时可以不指定此参数的值
而执行过程。默认值必须是常量或 NULL。如果存储过程使用带 LIKE 关键字的参数,则可包含通配符%、_、[ ]和[^]。
⚫ OUTPUT:指示参数是输出参数。使用 OUTPUT 参数将值返回给过程的调用方。
⚫ RECOMPILE :指示数据库引擎不缓存该存储过程的计划,该存储过程在运行时将被重新编译。
⚫ <sql_statement>:将要包含在存储过程中的一个或多个 T-SQL 语句。
【例 1】设在 SQL Server 2008 某数据库中有汽车表和销售表,表的定义如下:
CREATE TABLE 汽车表(
汽车型号 char(10) PRIMARY KEY,
汽车名称 char(20),
颜色 char(10),
价格 int )
CREATE TABLE 销售表(
汽车型号 char(10),
销售时间 datetime,
销售数量 int,
PRIMARY KEY(汽车型号,销售时间),
FOREIGN KEY(汽车型号) REFERENCES 汽车表(汽车型号) ) 现要创建一个具有如下功能的存储过程:查询指定日期范围内汽车的销售情况,列出汽车型号和销售总数量,包括没有被销售过的汽车。请补全空白处代码。
CREATE PROC p1
@start_date date, @end_date date
AS
SELECT 汽车表 汽车型号, sum(销售数量)
FROM 汽车表 left join 销售表 ON 汽车表.汽车型号 = 销售表.汽车型号
WHERE 销售时间 BETWEEN @start_date AND @end_date
GROUP BY 汽车表.汽车型号 2.执行存储过程
执行存储过程可以使用 T-SQL 的 EXECUTE 语句。如果存储过程是批处理中的第一条语句,那么不使用EXECUTE 关键字也可以执行存储过程。execute 语句的语法格式为:
[ { EXEC | EXECUTE } ]
{
[@ return_status =]
{ proc_name }
[ [@ parameter_name = ] { value
| @ variable [ OUTPUT ]
| [DEFAULT ]
}
]
[,…n ]
[ WITH RECOMPILE ]
}
[;] 各参数说明如下:
⚫ @ return_status:可选的整型变量,存储过程的返回状态。这个变量在用于 EXECUTE 语句前必须被声明过。
⚫ proc_name:要调用的存储过程名。
⚫ @ parameter:存储过程的参数,必须与存储过程中定义的相同。参数名前必须加上符号(@)。在与@parameter_name = value 格式一起使用时,不要求参数名和常量的顺序与存储过程中定义的顺序一致。
如果对任何参数使用了@parameter_name = value 格式,则对所有后续参数都必须使用此格式。(默认情况下,参数可为空值)
⚫ @ variable:是用来存储参数或返回参数的变量。
⚫ DEFAULT:使用定义存储过程时为参数指定的默认值。如果存储过程没有为参数指定默认值,而在执行存储过程时又使用了 DEFAULT 关键字,则会出现错误。
【例 2】带有输入参数的存储过程。
建立查询地址在指定地区的顾客的购买情况的存储过程,列出顾客姓名、购买的商品名、单价、购买日期、会员积分数。
CREATE PROCEDURE p_CustBuy2
@areaasvarchar(20)
AS
SELECT C Name,GoodsName,SaleUnitPrice,SaleDate,b.Score
FROM Table_Customer a JOIN Table_Card b ON a.CardID=b.CardID
JOIN Table_SaleBill c ON c.CardID=b.CardID
JOIN Table_SaleBillDetail d ON d.SaleBilllD=c.SaleBilllD
JOIN Table_Goods e ON e.GoodsID=d.GoodsID
WHERE Address=@area 当存储过程有输入参数并且没有为输入参数指定默认值时,在调用此存储过程时必须为输入参数指定一个常量值。
执行例 2 定义的存储过程,查询“北京市海淀区”的顾客的购买情况:
EXEC p_CustBuy2‘北京市海淀区’
【例 3】带有多个输入参数并有默认值的存储过程。
建立查询某个指定地区购买了单价高于指定价格的商品的顾客的购买信息,列出顾客姓名、购买的商品名、单价、购买日期、会员积分 t,:其中默认地区为“北京市海淀区”。
CREATE PROCEDURE p_CustBuy3
@areavarchar(20)=‘北京市海淀区’,@PricemoneyAS
SELECT CName,GoodsName,SaleUnitPrice,SaleDate,b.Score
FROM Table_Customer a JOIN Table_Card b ON a.CardID=b.CardID
JOIN Table_SaleBill c ON c.CardID=b.CardID
JOIN Table_SaleBillDetail d ON d.SaleBilllD=c.SaleBilllD
JOIN Table_Goods e ON e.GoodsID=d.GoodsID
WHERE Address=@area AND SaleUnitPrice>@Price 执行有多个输入参数的存储过程时,参数的传递方式有两种:
【例 4】带输入参数和一个输出参数的存储过程。
建立统计指定类型的商品的种类数的存储过程,并将统计的结果作为输出参数返回。
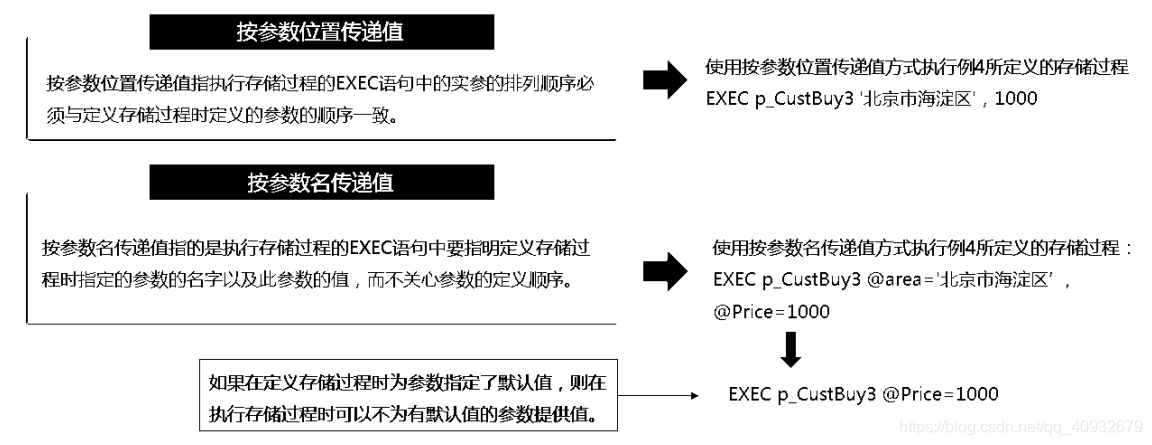
CREATE PROCEDURE p_GoodsCount@classvarchar(20),@countintoutputAS
SELECT @count=count(*)FROM Table_Goodsa
JOIN Table_Goods Class b ON a.GoodsClassID=b.GoodsClassID
WHERE GoodsClassName=@class
执行此存储过程:
DECLARE@cint
EXECp_GoodsCount‘服装’,@coutputPRINT@c 【例 5】带有多个输入参数和多个输出参数的存储过程。
建立统计指定地区和指定性别的顾客人数和平均年龄的存储过程,并将统计的结果作为输出参数返回。
CREATE PROCEDURE p.CustCount@areavarchar(20),@sexchar(2),
@countintoutput,@avg—ageintoutput
AS
SELECT@count=COUNT(*),
@avg_age=AVG(YEAR(GETDATE())-YEAR(BIRTHDATE))
FROM Table_Customer
WHERE Address=@area and Sex=@sex 执行此存储过程:
DECLARE@xint,@yint
EXEC p_CustCount‘北京市海淀区’,‘F’,@xoutput,@youtputSELECT@xAS 人数,@yAS 平均年龄 利用存储过程不但可以实现对数据的查询,而且还可以实现对数据的删除、更改和增加。
3.删除存储过程
删除存储过程使用 DROPprocedure 语句,该语句可从当前数据库中删除一个或多个存锗过程。其语法
格式为:
DROP|PROCIPROCEDURE|{[schema_name.]procedure|[,…n]
【例 6】删除 p_CustBuyl 存储过程。
DROP PROC p_CustBuyl
8.2用户定义函数
SQL Server2008 支持两类用户定义函数:标量函数和表值函数,标量函数只返回单个数据值,表值函数将返回一个表。表值函数又分为内联表值函数和语句表值函数。
8.2.1创建和调用标量函数
标量函数是返回单个数据值的函数。
1.定义标量函数
定义标量函数的语法格式为:
CREATE FUNCTION [ schema_name. ] function_name
( [ { @ parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[=default ]}
[,…n ]
]
)
RETURNS return_data_type
[AS]
BEGIN
function_body
RETURN scalar_expression
END
[;] 各参数说明如下:
⚫ schema_name:用户定义函数所属架构的名称。
⚫ Function_name:用户定义函数的名称,该名称必须符合有关标识符的规则,并且在数据库中以及对其架构来说是唯一的。
⚫ @parameter_name:用户定义函数中的参数。可声明一个或多个参数。一个函数最多可以有 2100个参数。执行函数时,如果未定义参数的默认值,则用户必须为每个已声明参数提供值。
⚫ [type_schema_name.]parameter_data_type:参数的数据类型及其所属的架构,后者为可选项。对于 T-SQL 函数,允许使用除 timestamp 数据类型之外的所有数据类型。如果未指定 type_schema_name,则数据库引擎将按以下顺序查找 parameter_data_type:
包含 SQL Server 系统数据类型名称的架构。
当前数据库中当前用户的默认架构。
当前数据库中的 dbo 架构。
⚫ [=default]:参数的默认值。如果定义了 default 值,则在执行函数时可不指定此参数的值。如
果希望在调用函数时使用参数的默认值,则必须指定关键字 DEFAULT。
⚫ return_data_type:用户定义函数的返回值类型。可以是除 timestamp类型之外的所有数据类型。
⚫ function_body:定义函数值的一系列 T-SQL 语句。
⚫ scalar_expression:指定标量函数返回的标量值。
【例 7】创建计算立方体体积的标量函数,此函数有 3 个输入参数,分别为立方体的长、宽和高,类型均为整型,函数的返回值的类型也为整型。
CREATE FUNCTION dbo.CubicVolume
(@ CubeLength int,@ CubeWidth int,@ CubeHeight int)
RETURNS int
AS
BEGIN
RETURN(@CubeLength * @ CubeWidth * @ CubeHeight)
END 2.调用标量函数
当调用标量函数时,必须提供至少由两部分组成的名称:函数拥有者名和函数名。可在任何弋许出现表达式的 SQL 语句中调用标量函数,只要类型一致。
调用【例 7】定义的函数,计算长、宽、高分别为 6、8、10 的立方体的体积的 SQL 语句为:
SELECT dbo.CubicVolume(6,8,10)
8.2.2创建和调用内联表值函数
内联表值函数的返回值是一个表,该表的内容是一个查询语句的结果。
1.创建内联表值函数
定义内联表值函数的语法为:
CREATE FUNCTION [ schema_name. ] function_name
( [ { @ parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[=default ] }
[,…n ]
]
)
RETURNS TABLE
[AS ]
RETURN [ ( ] select_stmt [ ) ]
[;] 其中,select_stmt 是定义内联表值函数返回值的单个 SELECT 语句。其他各参数含义同标量函数。
在内联表值函数中,通过单个 SELECT 语句定义 TABLE 返回值。内联表值函数没有相关联的返回变量,也没有函数体。
【例 8】创建查询指定类别的商品名称和单价的内联表值函数。
CREATE FUNCTION f_GoodsInfo(@classchar(10))
RETURNS table
AS
RETURN(
SELECT GoodsName,SaleUnitPrice FROM Table_GoodsClass a
JOIN Table_Goods b ON a.GoodsClassID=b.GoodsClassID
WHERE GoodsClassName=@class) 2.调用内联表值函数
对内联表值函数的使用与视图非常类似,需要放置在查询语句的 FROM 子句部分,它的作用很像是带参数的视图。利用【例 8】定义的内联表值函数,查询“服装”类的商品信息的 SQL 语句为:
SELECT * FROM dbo.f_GoodsInfo(‘服装’)
8.2.3创建和调用多语句表值函数
多语句表值函数的功能是视图和存储过程的组合,可以利用多语句表值函数返回一个表,表中的内容可由复杂的逻辑和多条 SQL 语句构建(类似于存储过程),可以在 SELECT 语句的 FROM 子句中使用多语句表值函数(同视图)。
1.创建多语句表值函数定义多语句表值函数的语法:
CREATE FUNCTION [ schema_name. ] function_name
( [ { @ parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[=default ] |
[,…n]
]
)
RETURNS @ return_variable TABLE <table_type_definition>
[AS ]
BEGIN
function_body
RETURN
END
[;]
<table_type_definition> ::=
( { <column_definition> <column_constraint>
| <computed_column_definition> }
[<table_constraint> ] [,…n ]
) 各参数说明如下:
⚫ function_body:是一系列 T-SQL 语句,这些语句用于填充 TABLE 返回变量。
⚫ table_type_definition:定义返回的表的结构,该表结构的定义同创建表的语句。在表定义中,
可以包含列定义、列约束定义、计算列以及表约束定义。
【例 9】定义查询指定类别的商品的名称、单价生产日期和新旧商品的多语句表值函数,其中新旧商品的值为:如果到目前为止此商品的生产月数超过 12 个月,则为“旧商品”;若生产月过在 6~12 个月之间,则为“一般商品”;若生产月数小于 6 个月,则为“新商品”。
CREATE FUNCTION f_GoodsType( @ class varchar(20))
RETURNS @ f_GoodsType table(
商品名 varchar(50),单价 money,生产日期 datetime,类型 varchar(10))
AS
BEGIN
INSERT INTO @ f_GoodsType
SELECT GoodsName,SaleUnitPrice,ProductionDate,CASE
WHEN datediff( month,ProductionDate ,‘2007/2/10’) > 12 THEN‘旧商品’
WHEN datediff( month,ProductionDate ,‘2007/2/10’) BETWEEN 6 AND 12 THEN‘一般商品’
WHEN datediff( month,ProductionDate,‘2007/2/10’) < 6 THEN ‘新商品’
END
FROM Table_GoodsClass a JOIN Table_Goods b
ON a. GoodsClassID = b. GoodsClassID
WHERE GoodsClassName = @ class
RETURN
END 2.调用多语句表值函数
多语句表值函数的返回值是一个表,因此对多语句表值函数的使用也是放在 SELECT 语句的 FROM 子句部分。
调用【例 9】定义的函数,查询“家用电器”类商品信息的 SQL 语句为:
SELECT*FROMdbo.f.GoodsType(‘家用电器’)
8.2.4删除用户自定义函数
删除函数使用 DROP function 语句实现,它从当前数据库中删除一个或多个用户定义函数。其语法格式为:
DROP FUNCTION|[schema_name.]function_name|[,…n]
【例 10】删除 f_GoodsType 函数。
DROP FUNCTION f_GoodsType
8.3触发器
8.3.1基本概念
触发器是一种特殊的存储过程,其特殊性在于它不需要由用户来直接调用,而是在对表中的数据进行UPDATE、INSERT 或 DELETE 操作时自动触发执行的。触发器通常用于保证业务规则和数据完整性,其主要优点是用户可以用编程的方法来实现复杂的处理逻辑和商业规则,增强了数据完整性约束的功能。
触发器通常用在下列场合:
●完成比 CHECK 约束更复杂的数据约束。
●为保证数据库性能而维护的非规范化数据
●可实现复杂的商业规则。
●触发器也可以评估数据修改前后的表状态,并根据其差异采取对策。
SQL Server2008支持三种类型的触发器:DML、DDL和登录触发器。如果用户要通过数据操作语言(DML)事件编辑数据,则执行 DML 触发器。DML 事件是针对表或视图的 INSERT、UPDATE 或 DELETE 语句。DDL 触发器用于响应各种数据定义语言(DDL)事件,这些事件主要对应 T-SQL 中的 CREATE、ALTER 和 DROP 语句,
以及执行类似 DDL 操作的某些系统存储过锃。登录触发器在遇到 LOGON 事件时触发,LOGON 事件是在建立用户会话时引发的。
这里只介绍最常用的 DML 触发器。
8.3.2创建触发器
建立 DML 触发器的 SQL 语句为 CREATE TRIGGER,其语法格式为:
CREATE TRIGGER [ schema_name . ] trigger_name
ON { table | view }
{ FOR | AFTER | INSTEAD OF}
{ [ INSERT ] [,] [ UPDATE ] [,] [ DELETE ] }
AS { sql_statement }
[;]
CREATETRIGGER[schema_name.]trigger—nameON|tableIview|tFORIAFTERIINSTEADOF}
I[INSERT][,][UPDATE][,][DELETE])
ASjsql_statement|
[;] 各参数说明如下:
⚫ schema_name:触发器所属架构的名称。
⚫ Trigger_name:触发器名称。该名称必须遵循标识符规则,而且不能以#或##开头。
⚫ table | view:与触发器相关联的表或视图,有时称为触发器表或触发器视图。可以根据需要指
定表或视图的完全限定名称。在视图上只能定义 INSTEAD OF 触发器。
⚫ FOR | AFTER:指定触发器只有在引发的 SQL 语句中指定的操作都已成功执行,并且所有的约束检查也成功完成后,才执行此触发器。如果仅指定 FOR 关键字,则 AFTER 为默认值。
不能在视图上定义 AFTER 触发器。
⚫ INSTEADOF:指定执行触发器而不是执行引发触发器执行的 SQL 语句,从而替代触发语句的操作。
⚫ INSERT,DELETE 和 UPDATE:引发触发器执行的操作,若同时指定多个操作,则各操作之间用逗号分隔。
创建触发器时,需要注意如下几点:
⚫ 在一个表上可以建立多个名称不同、类型各异的触发器,每个触发器可由所有三个操作来引发。对于 AFTER 型的触发器,可以在同一种操作上建立多个触发器;对于 INSTEADOF 型的触发器,在同一种操作上只能建立一个触发器。
⚫ 大部分 T-SQL 语句都可用在触发器中,但也有一些限制。例如,所有的建立和更改数据库以及数据库对象的语句、所有的 DROP 语句都不允许在触发器中使用。
⚫ 在触发器定义中,可以使用 UPDATE 子句来测试 INSERT 和 UPDATE 语句是否对指定字段有影响。如果将一个值赋给指定字段或更改了指定字段,则这个子句就为真。
⚫ 通常不要在触发器中返回任何结果。
在触发器语句中可以使用两个特殊的临时工作表:INSERTED 表和 DELETED 表。这两个表是在用户执行数据的更改操作时,SQL Server 自动创建和管理的。这两个表驻留在内存中,其结构同触发器所作用的基本表的结构,并且只可以被触发器使用,当触发器结束时系统自动释放两个表的空间。
DELETED 表用于存储 DELETE 和 UPDATE 语句所影响的行的复本。在执行 DELETE 操作时,被删除的数据被保存到 DELETED 表中。在执行 UPDATE 操作时,对被修改操作影晌的所有数据行,将更改前的数据(按行进行)保存到 DELETED 表中。DELETED 表和执行操作的基本表通常没有相同的数据行。
INSERTED 表用于存储 INSERT 和 WDATE 语句所影响的行的副本。在执行 INSERT 操作时,新插入的数据同时被保存到 INSERTED 表中。在执行 UPDATE 操作时,对被修改操作影响的所有数据行,将更改后的数据(按行进行)保存到 INSERTED 表中。INSERTED 表中的内容是执行操作的基本表中新数据行的副本。
UPDATE 操作类似于在删除之后执行插入:首先在执行操作的基本表中删除更新前的行,并将这些行复制到 DELETED 表中,然后将更新后的新行插入到执行操作的基本表和 INSERTED 表中。
1.创建后触发型触发器
使用 FOR 或 AFTER 选项定义的触发器为后触发型触发器,即只有在引发触发器执行的语句中的操作都已成功执行,并且所有的约束检查也成功完成后,才执行触发器。
【例 11】设在 SQL Server 某数据库中有房屋及租赁表,表的定义如下:
CREATE TABLE 房屋表(
房屋号 char(10) PRIMARY KEY,
房屋地址 char(20) not null,
面积 int, 月租金 int)
CREATE TABLE 租赁表( 房屋号 char(10),
租赁日期 datetime,
租赁月数 int not null,
本次总租金 int,
PRIMARY KEY(房屋号,租赁日期),
FOREIGN KEY(房屋号) REFERENCES 房屋表(房屋号) ) 现要创建一个具有如下功能的触发器:每当在租赁表中插入一行数据(房屋号,租赁日期,租赁月数)时,自动计算出该房屋的本次总租金。请补全下列代码。
CREATE TRIGGER tri ON 租赁表 FOR INSERT
AS
DECLARE @x int --声明保存月租金的变量
SET @x = (SELECT 月租金 FROM 房屋表 WHERE 房屋号 = (SELECT 房屋号 FROM inserted ))
UPDATE 租赁表 SET 本次总租金 = 租赁月数 * @x
FROM 租赁表 as a JOIN inserted as b
on a.房屋号 = b.房屋号
and a.租赁日期 = b.租赁日期 触发器与引发触发器执行的操作共同构成了一个事务,事务的开始是引发触发器执行序作,事务的结束是触发器的结束。由于 AFTER 型的触发器在执行时引发触发器执行的操作已执行完了,因此在触发器中应使用 ROLLBACK 撤销不正确的操作,这里的 ROLLBACK 实际渴滚到引发触发器执行的操作之前的状态。
如果不同表中的列之间存在取值约束关系,则只能用触发器实现,不能用 CHECK 约束实现,因为 CHECK约束只能实现同一个表中列之间的取值约束。
2.创建前触发型触发器
使用 INSTEAD OF 选项定义的触发器为前触发型触发器。在这种模式的触发器中,指定执行触发器而不是执行引发触发器执行的 SQL 语句,从而替代引发语句的操作。对于定义了前触发型触发器的操作,系统并不执行引发触发器执行的数据操作语句。因此,如果数据操作满足完整性约束的要求,则在触发器中必须重新执行这些数据操作语句。在表或视图上,每个 INSERT、UPDATE 或 DELETE 语句最多可以定义一个INSTEAD OF 触发器。
【例 12】创建保证销售单据表中使用的会员卡是有效日期内的会员卡的触发器。
CREATE TRIGGER CardValid
ON Table_SaleBill INSTEAD OF INSERT,UPDATE
AS
IF NOT EXISTS(SELECT * FROM inserted a
JOIN Table.Card b ON a.CardID=b.CardID
WHERE SaleDate NOT BETWEEN StartDate AND EndDate)
INSERT INTO Table_SaleBill SELECT * FROM inserted 8.3.3删除触发器
删除触发器使用 DROP TRIGGER 语句实现,它从当前数据库中删除一个或多个触发器。
语法格式为:
DROP TRIGGER schema_name.trigger_name[,…n][;]
【例 13】删除名为 CardValid 的触发器的 SQL 语句为:
DROP TRIGGER CardValid
8.4游标
8.4.1游标的组成
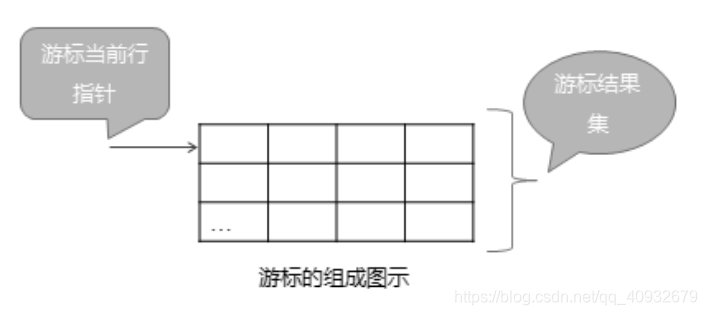
游标(Cursor)包括如下两部分内容:
⚫ 游标结果集:指定义游标的 SELECT 语句返回的结果的集合。
⚫ 游标当前行指针:指向该结果集中的某一行的指针。游标示意图如右图所示。
⚫ 游标具有如下特点:
⚫ 允许定位结果集中的特定行。
⚫ 允许从结果集的当前位置检索一行或多行。
⚫ 支持对结果集中当前行的数据进行修改。
⚫ 为由其他用户对显示在结果集中的数据所做的
更改提供不同级别的可见性支持。
8.4.2使用游标
使用游标的典型过程如下图所示。
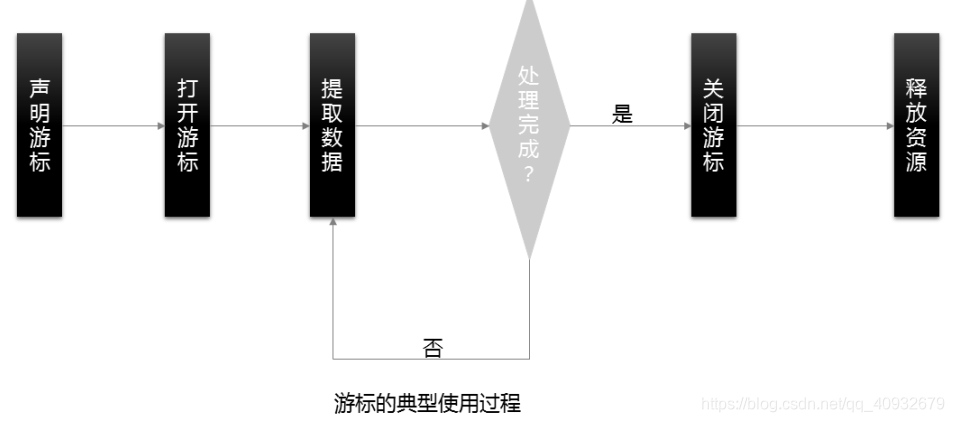
1.声明游标
声明游标实际是定义服务器端游标的特性,例如游标的滚动行为和用于生成游标结果集的查询语句。
SQL Server 支持两种格式的声明游标语句:一种是基于 iso 标准的语法,另一种是莹用 T-SQL 扩展的语法。这里只介绍 ISO 标准语法的声明游标的语句。
ISO 声明游标的简化语法格式如下:
DECLARE cursor_name [ INSENSITIVE ] [ SCROLL ] CURSOR
FOR select_statement
[FOR { READ ONLY | UPDATE [ OF column_name [,…n] ] } ] 各参数含义如下:
⚫ cursor_name:所定义的服务器游标名。
⚫ INSENSITIVE:定义一个游标,以创建将由该游标使用的数据的临时复本。对游标的所有请求都从 tempdb 数据库中的这一临时表中得到应答;因此,在对该游标进行提取操作时,返回的数据不反映对基本表所做的修改,并且在该游标中不允许修改基本表数据。如果省略 INSENSITIVE,则已提交的(任何用户)对基本表的删除和更新都会反映在后面的提取操作中。
⚫ SCROLL:指定所有的提取选项(FIRST、LAST、PRIOR、NEXT、RELATIVE、ABSOLUTE)均可用。如果未在 DECLARE CURSOR 中指定 SCROLL,则 NEXT 是唯一支持的提取选项。如果指定了 FAST_FORWARD,则不能指定 SCROLL。
⚫ select_statement:定义游标结果集的标准 SELECT 语句。
⚫ READ ONLY:禁止通过该游标更新数据。在 UPDATE 或 DELETE 语句的 WHERE CURRENTOF 子句中不能引用该游标。
⚫ UPDATE[OF column_name[,…n]]:定义游标中可更新的列。如果指定了 OF column_name [,…n],则只允许修改所列出的列。如果指定了 UPDATE,但未指定 column_name[,…n],则可以更新所有的列。
2.打开游标
打开游标的语句是 OPEN,其语法格式为:
OPEN cursor_name;其中 cursor_name 为游标名。
注意,只能打开已声明但还没有打开的游标。
3.提取数据
游标被声明和打开之后,游标的当前行指针就位于结果集中的第一行位置,可以使用 FETCH 语句从游标结果集中按行提取数据。其语法格式如下:
FETCH [ [ NEXT | PRIOR | FIRST | LAST
| ABSOLUTE n
| RELATIVE n ]
FROM
]
cursor_name [ INTO @ variable_name [ , …n ] ] 各参数的含义如下:
⚫ NEXT:返回紧跟在当前行之后的数据行,并且当前行递增为结果行。如果 FETCH NEXT 是对游标的第一次提取操作,则返回结果集中的第一行。NEXT 为默认选项。
⚫ PRIOR:返回紧临当前行前面的数据行,并且当前行递减为结果行。如果 FETCH PRIOR 为对游标的第一次提取操作,则不返回任何结果并将游标当前行置于第一行之前。
⚫ FIRSTS:返回游标中的第一行并将其作为当前行。
⚫ LAST:返回游标中的最后一行并将其作为当前行。
⚫ ABSOLUTE:如果 n 为正数,返回从游标第一行开始的第 n 行,并将返回的行变成新的当前行。如果 n 为负数,则返回从游标最后一行开始之前的第 n 行,并将返回的行变成新的当前行。如果 n 为 0,则不返回任何结果。n 必须为整型常量。
⚫ INTO @variable_name [,…n]:将提取的列数据保存到局部变量中。列表中的各个变量从左到右与游标结果集中的相应列对应。各变量的数据类型必须与相应的结果列的数据类型匹配。变量的数目必须与游标选择列表中的列的数目一致。在对游标数据进行提取的过程中,可以使用@@FETCH_STATUS 全局
变量判断数据提取的状态 @@FETCH_STATUS 返回 FETCH 语句执行后的游标最终状态。
@@FETCH.STATUS 的取值和含义如下表所示。
@@FETCH_STATUS 返回的数据类型是 int。由于@@FETCH_STATUS 对于在一个连接上的所有游标是全局性的,不管是对哪个游标,只要执行一次 FETCH 语句,系统都会对@@FETCH.STATUS 赋一次值,以表明该FETCH 语句的执行情况。因此,在每次执行完一条 FETCH 语句后,都应该测试一下@@FETCH.STATUS 全局变量的值,以观测当前提取游标数据语句的执行情况。

注意:在对游标进行提取操作前,@@FETCH_STATUS 的值没有定义。
4.关闭游标
关闭游标使用 CLOSE 语句,其语法格式为:
CLOSE cursor_name
在使用 CLOSE 语句关闭游标后,系统并没有完全释放游标的资源,并且也没有改变游标的定义,当再次使用 OPEN 语句时可以重新打开此游标。
5.释放游标
释放游标是释放分配给游标的所有资源。释放游标使用 DEALLOCATE 语句,其语法格弍为:
DEALLOCATE cursor_name
8.4.3游标示例
【例 14】对Table_Customer表,定义一个查询“北京市海淀区”姓“王”的顾客姓名和邮箱的游标,
并输出游标结果。
DECLARE @ cn VARCHAR(10) , @ Email VARCHAR(50)
DECLARE Cname_cursor CURSOR FOR
SELECT CName, Email FROM Table_Customer
WHERE Cname LIKE ‘王%’ AND Address LIKE ‘北京市海淀区’
OPEN Cname_cursor
FETCH NEXT FROM Cname_cursor INTO @ cn, @ Email
WHILE @ @ FETCH_STATUS = 0
BEGIN
PRINT ‘顾客姓名:’ + @cn + ',邮箱+ @ Email
FETCH NEXT FROM Cname_cursor INTO @cn, @ Email
END
CLOSE Cname_cursor
DEALLOCATE Cname_cursor