
原文标题:OmniVL: One Foundation Model for Image-Language and Video-Language Tasks
论文链接:OmniVL: One Foundation Model for Image-Language and Video-Language Tasks | OpenReview
三模态统一的工作。
一、问题提出
旨在设计一个全视觉语言基础模型OmniVL,以支持图像语言和视频语言的预训练以及相应的下游任务。
现有模型比较:
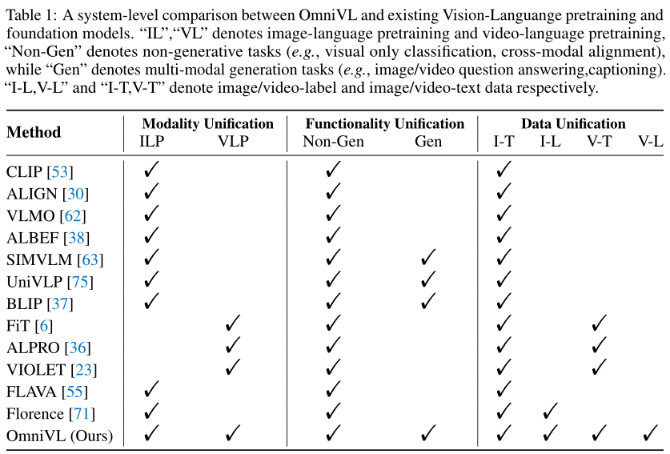
第一次证明了一个模型可以双向受益于图像和视频任务,而不是传统的单向方式,即使用image (/image-language)来帮助video(/video-language)
为了同时支持图像和视频输入,OmniVL采用了统一的基于transformer的视觉编码器来提取视觉表示,其中视频输入与图像共享大多数transformer层,3D patch tokenizer 和temporal attention blocks。与现有VLP model类似,OmniVL有另一个text encoder来提取语言表示。为了在同一体系结构中支持多个任务的学习,OmniVL遵循encoder-decoder结构,有两个基于视觉的decoder。其中一个具有视觉-文本语义对齐的双向注意,另一种解码器具有文本生成的因果注意。用图像语言和视频语言数据以一种解耦的联合方式对OmniVL进行预训练,这与现有的工作不同,这些工作只应用图像语言预训练,只应用视频语言预训练,或者从头开始使用它们的联合预训练。更具体地说,首先对图像语言进行预训练,专注于空间表示学习,然后与视频语言一起进行联合预训练,在保留/优化已学习好的空间表示的同时,增量地学习时间动态。这不仅使从空间到时间维度的学习效率更高,而且使学习相互补充。这种双向帮助在以前的工作中还没有被阐明,并且在推动一个基础模型来提高图像和视频任务的性能方面非常重要。
优势:目标是利用尽可能多的监督(或噪声监督)预训练语料;人类标注的视觉标签数据(如ImageNet)导致获得更具偏差的表示,这有利于迁移学习任务(如图像分类),而网络爬取的视觉语言数据涵盖更广泛的视觉概念,并有利于跨模态和多模态任务。
二、模型结构
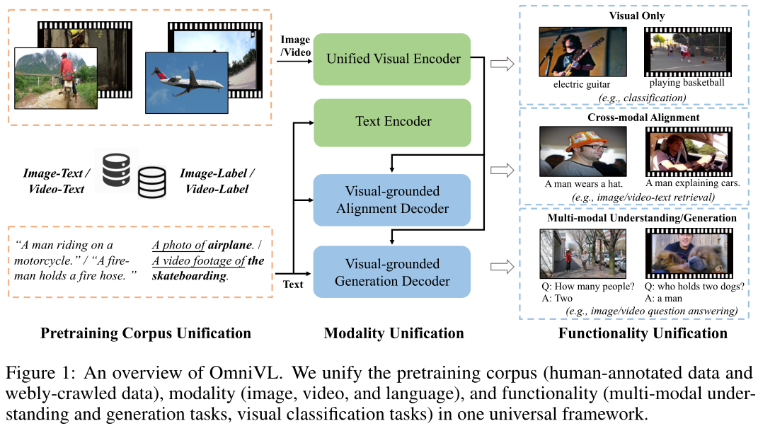
1、Framework
Unified Visual Encoder.
将图像和视频统一在一个基于transformer的visual encoder中,将它们转换为一系列token,其中独立的基于2D/3D convolution-based patch tokenizers分别用于图像/视频。因此,将空间和时间位置编码添加到输入token中以合并位置信息,依次执行时间自注意和空间自注意,对于图像输入,将自动跳过时间自注意块。最终的可视化表示vcls是从最后一个块的[CLS]令牌获得的。
Text Encoder. BERT
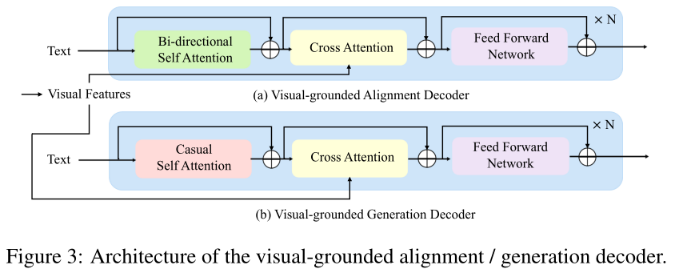
Visual-grounded Alignment Decoder
它以统一视觉编码器的文本和输出视觉特征作为输入,并将两种模式的信息用堆叠的变形块进行融合。每个块基本上包含一个自我注意层、一个交叉注意层和一个前馈层。一个特定于任务的token [ENC]被添加到输入文本中,其输出embedding将被用作融合的跨模态表示。
Visual-grounded Generation Decoder
通过附加一个基于视觉的文本生成解码器,使模型拥有多模态生成能力。它采用了与上述对齐译码器相似的结构,但将双向自注意替换为因果自注意。添加一个[DEC] token和一个[EOS] token分别表示任务类型和信号结束。
2、Pre-training Objectives
Unified Vision-Language Contrastive (UniVLC) Loss.
通过统一来自图像标签数据的监督学习和来自自然语言监督的对比学习,引入了一种新的视觉表示学习范式。在本文中,将其范围扩展到统一的视觉领域,通过联合视觉-标签-文本空间将图像和视频数据结合起来进行跨模态预训练。
定义人工标注图像/视频标签数据和web爬虫图像/视频文本数据为三元组格式S = (x, y, t),其中x为图像/视频数据,y是标签,t是语言描述,对于图像/视频标签数据,使用与CLIP和ActionCLIP相同的prompt生成t。
根据CLIP对其进行线性投影和归一化层,得到潜在视觉向量vi和文本向量wi,为了实现大批量的对比学习,我们维护了三个队列,分别存储动量编码器中最近的M个视觉向量和文本向量,以及对应的标签。然后计算对比损失:
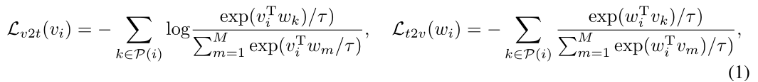
τ是一个可学习的温度参数。最后,统一的视觉-语言对比损失定义为:
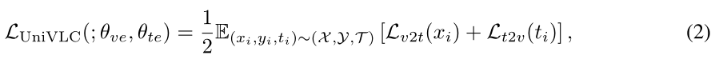
Vision-Language Matching (VLM) Loss.
Language Modeling (LM) Loss.
以交叉熵损失优化视觉接地生成解码器的输出,直接以自回归的方式最大化输入文本序列的似然:
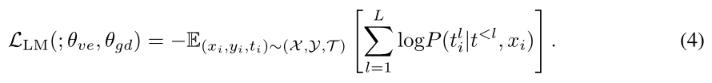
total loss:
3、Pretraining Corpus and Paradigms
Corpus. 对于图像-文本数据,默认共14M张图像,包括2个人类注释数据集(COCO和Visual Genome)和3个web数据集(CC3M,CC12M和SBU caption)。对于视频-文本数据,使用WebVid,包含250万来自网络的视频。
Paradigms. 采用解耦的联合预训练范式。具体来说,首先在图像-标签-文本数据上预训练,然后在图像-标签-文本数据和视频-标签-文本数据上进行联合训练。通过这种方式,将多模态建模解耦到空间和时间维度。这种设计有两个潜在的好处:1)考虑到视频预训练的高昂计算成本,首先应用图像数据学习空间表示更有效。2)解耦模式使多模态表示学习更加有效,这是图像语言和视频语言相互受益的关键。
三、Experiments
Implementation Details. 默认情况下,视觉编码器和文本编码器使用TimeSformer基本模型和BERT基本模型。在ImageNet-1K上预训练的Vit-B/16初始化空间注意力,分辨率为224 × 224的RandomCrop为输入,应用RandAugment。该模型使用batch_size 2880个预训练20个epoch。对于联合预训练,对8 × 224 × 224个视频片段进行稀疏抽样,训练10个epoch,视频数据batch_size 为800,图像数据batch_size 为2880个。联合预训练在图像和视频数据之间进行批量交替。使用AdamW优化,权重衰减为0.05。学习率被warmup到3e-4(图像)/ 8e-5(joint),并以0.85的速率线性衰减。在下游微调过程中,将图像-文本和视频-文本任务的图像分辨率提高到384 × 384。每个视频随机抽取8帧用于检索,16帧用于QA。在时空视觉编码器中插入时间位置embedding以适应不同长度的输入。
1、Visual Only Tasks
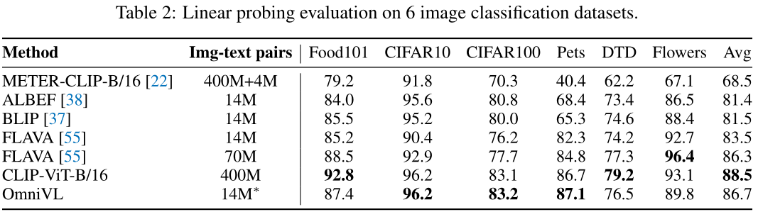
Image Classification
Video Action Recognition.
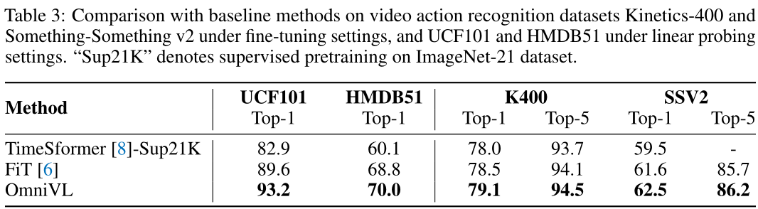
2、Cross-modal Alignment Tasks
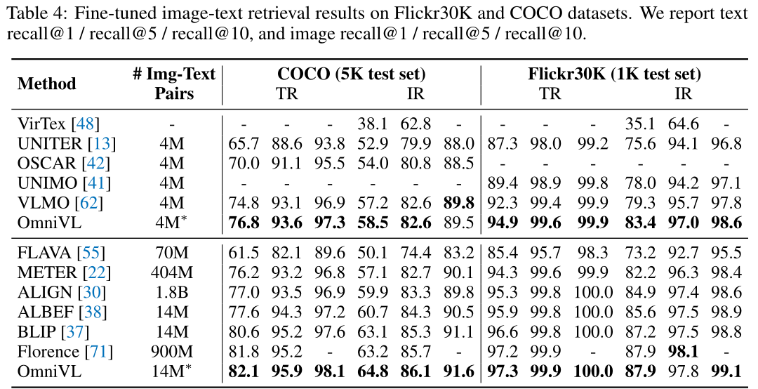
Image-Text Retrieval.
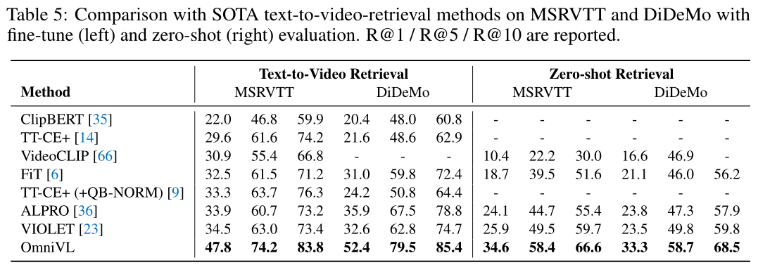
Text-to-Video Retrieval
3、Multi-modal Understanding and Generation Tasks
Image Captioning.
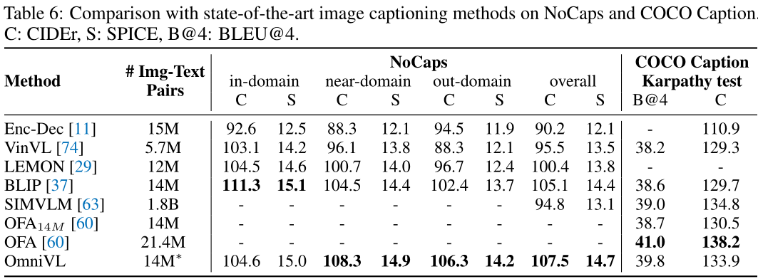
Video Captioning.
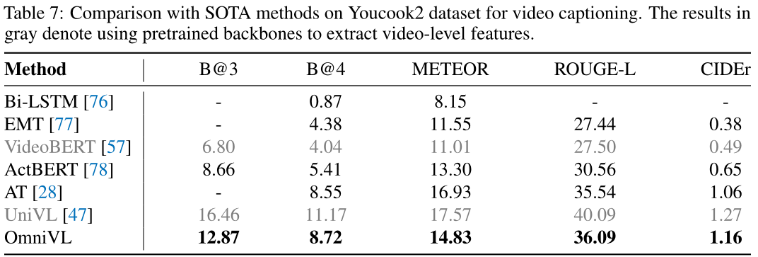
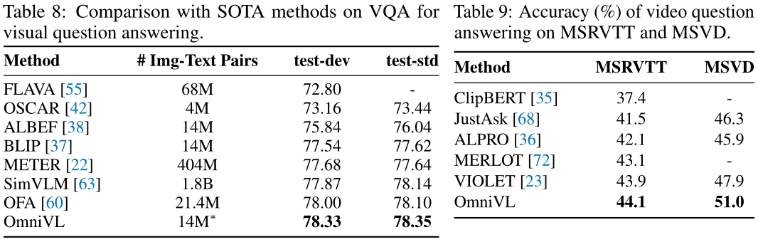
Visual Question Answering. & Video Question Answering.
4、Ablation Study
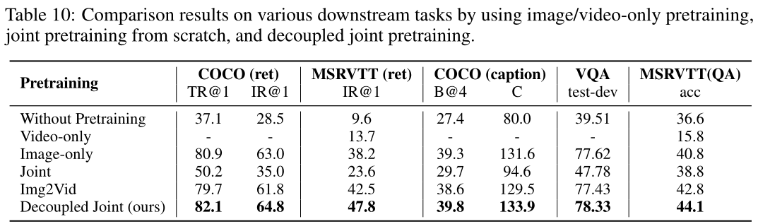
Decoupled Joint Pretraining.
使用不同的预训练策略进行了四种消融实验:仅图像预训练、仅视频预训练、从头开始的joint预训练和Img2Vid预训练,其中首先在图像上预训练OmniVL,然后在视频上预训练。
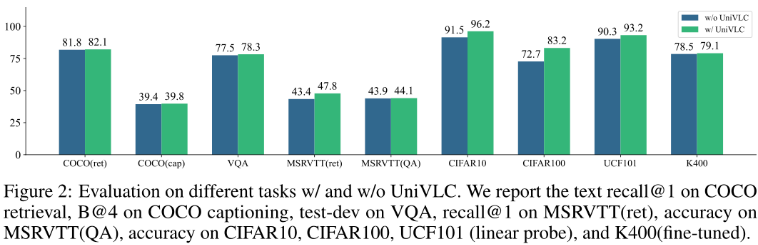
UniVLC Loss.
将UniVLC损失替换为vanilla对比损失,研究其对各种下游任务的影响
四、总结
尽管模型在广泛的下游任务上取得了优异的结果,但它仍然缺乏一些视觉语言交互任务所需的常识性推理能力(例如,视觉/视频问题回答)。还需要更好的架构设计,以支持可视化问答的zero-shot能力和GPT-3这样的zero-shot任务定制能力。从社会影响的角度来看,由于模型是在大规模的网络抓取数据上进行预训练的,这些数据可能包含一些有毒的语言或偏见,并且不容易明确地控制模型输出,因此应该非常注意确保负责任的模型部署