1 大数据分析现状和背景
1.1 大数据分析现状
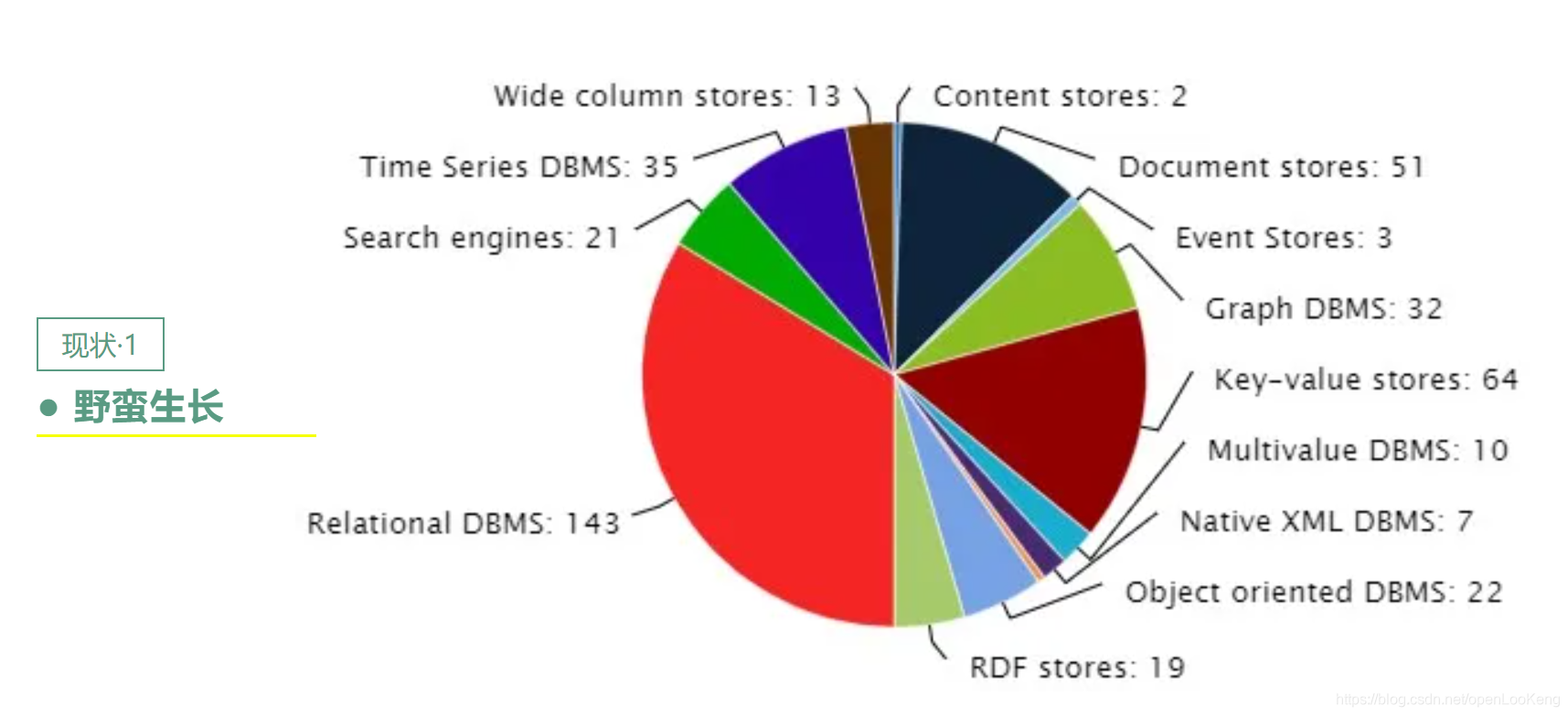
从2008年Hadoop成为Apache顶级项目之后,大数据技术经历了一个繁荣的发展阶段,各种组件层出不穷,上图显示了,当前查询分析软件有300+,这也导致了当前大数据平台就像堆积木一样,数据在各个组件之间流转,需要冗长的ETL过程,数据存在多个副本,开发者需要多种系统的编程语言,开发难度高,使用复杂;
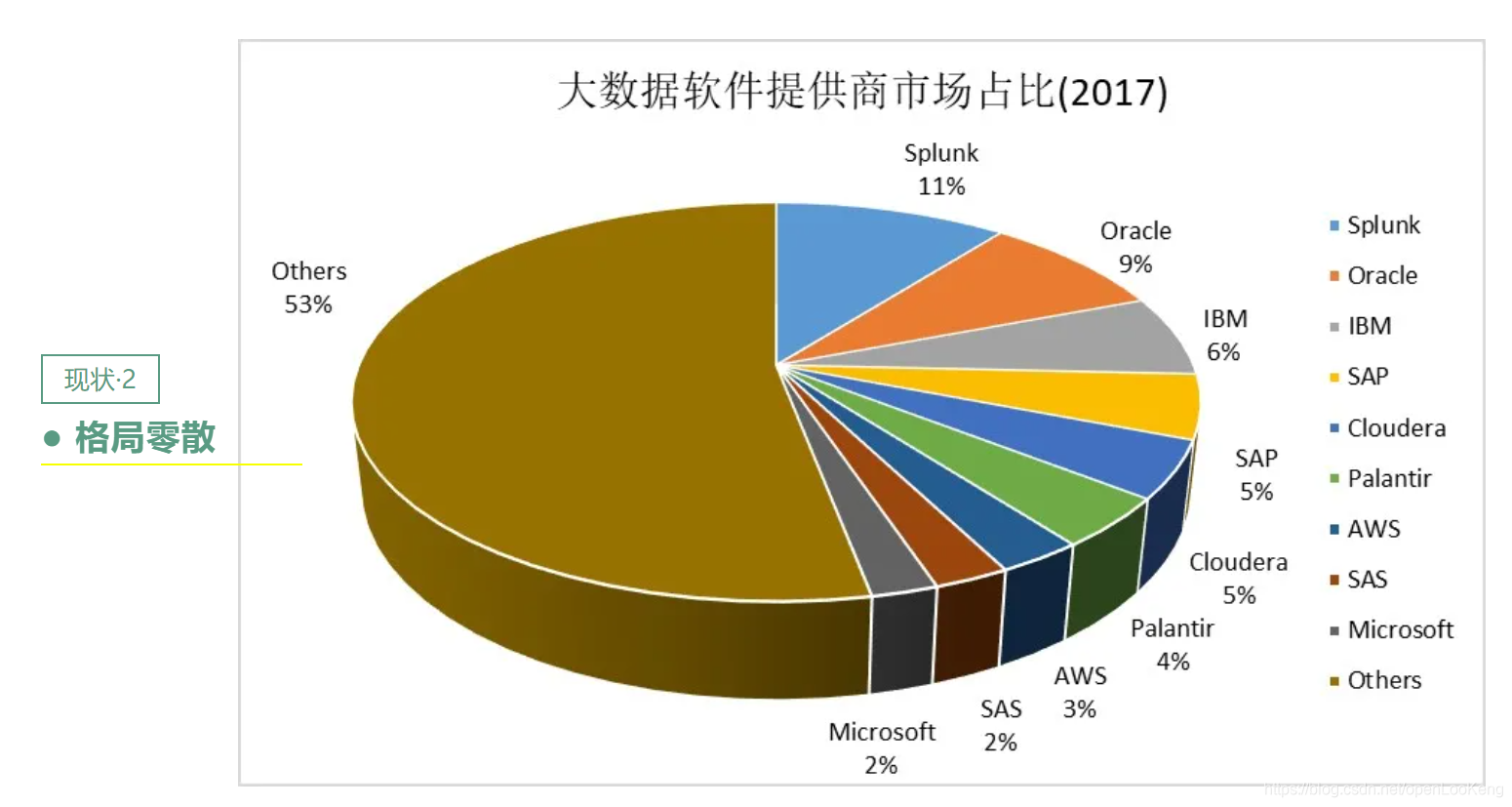
如上图所示,市场占有率最高也仅仅11%,老牌数据库厂商Oracle仅仅占优9%,而others占了53%,即没有巨头,新进入者有巨大的机会;
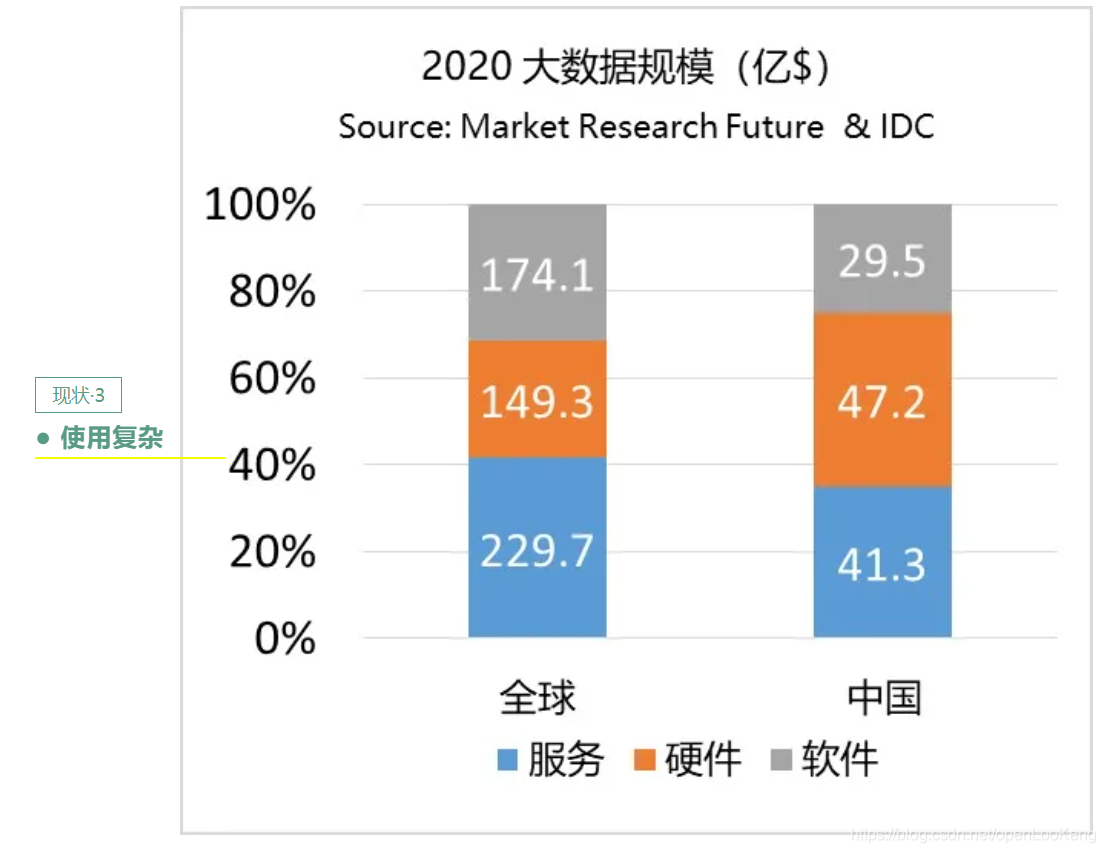
从上图可以看出大数据的市场服务占比在40%左右,而数据的服务占比在个位数,这里的服务指使用大数据的服务成本,包括开发,运维和维护,这也间接说明了大数据使用复杂的问题。
1.2 大数据分析面临的挑战
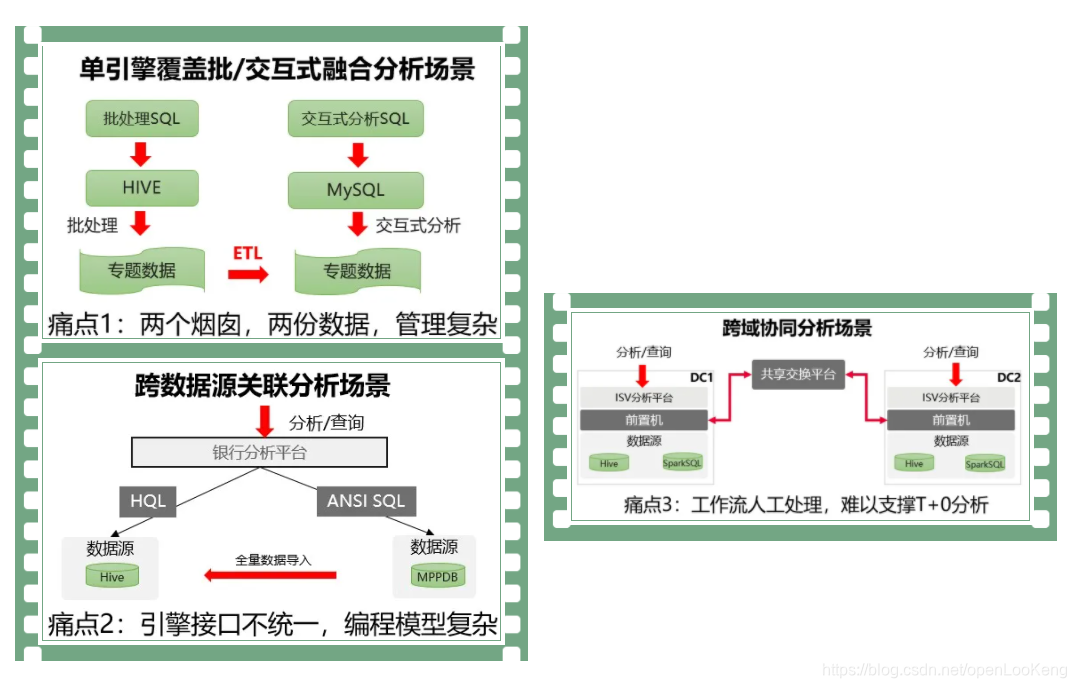
大数据当前面临的挑战归结起来有三点:
- 数据经过ETL之后,存在多个副本,多个数据烟囱,管理复杂;
- 引擎接口不同意,跨源关联分析的编程模型复杂,开发难度大;
- 跨DC的数据访问,数据需要经过多次的数据搬迁,比如DC1访问DC2,数据先要从数据源->DC2的前置机->共享交互平台->DC1的前置机->DC1的数据分析引擎。
上述的挑战就要求分析引擎提供:
(1)批/交互式融合分析;
(2)跨源数据分析;
(3)跨域协同分析。
2 openLooKeng架构
openLooKeng是一个统一高效的数据虚拟化融合分析引擎,我们的愿景是让大数据变简单,即要解决上述问题。 北向接口方面,openLooKeng提供ODBC、JDBC以及REST接口,以ANSI 2003 SQL为载体提供统一数据访问接口,BI工具、AI工具可以有效地通过所提供的接口与openLooKeng集成,简化系统设计。南向接口方面,通过数据源连接框架,Data Source Connector提供多种数据源的访问能力,无论是大数据生态的Hive或者Hbase,或是OLTP数据库PostgreSQL以及MySQL,都可以方便的接入。此外,openLooKeng提供跨数据中心Data Center Connector,提供高性能跨域协同计算。
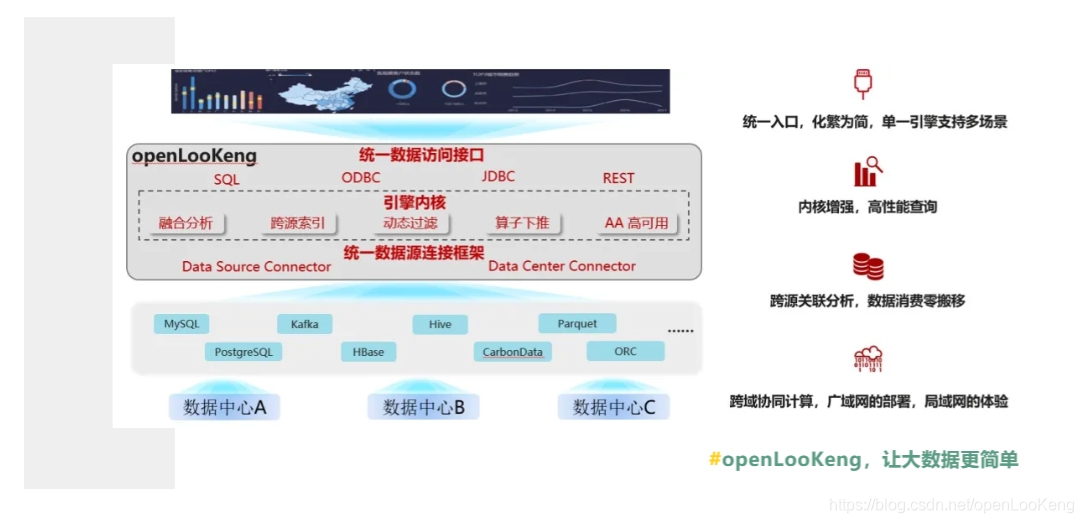
openLooKeng基础的交互式查询能力是基于Presto开源版本构筑的。但openLooKeng在技术场景、引擎内核技术、南北向应用生态等方面相对于Presto有较大差异。
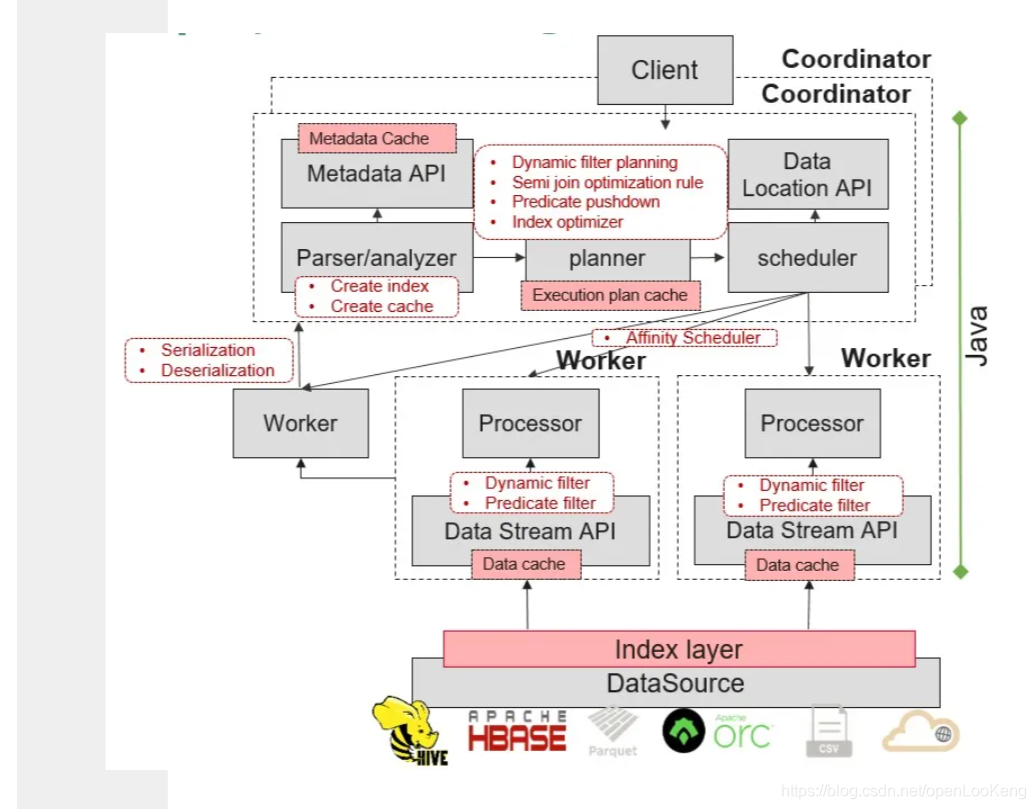
openLooKeng是一个类MPP架构的分布式处理系统,包含协调器Coordinator以及Worker两种角色,通过实现AA高可用性,整体系统无单点故障问题。同时,openLooKeng内部采用向量化列式处理,针对大数据场景列式处理性能更快,且可以充分利用CPU并行潜力。通过基于内存的流水线处理结构,openLooKeng可以实现高性能并行处理。
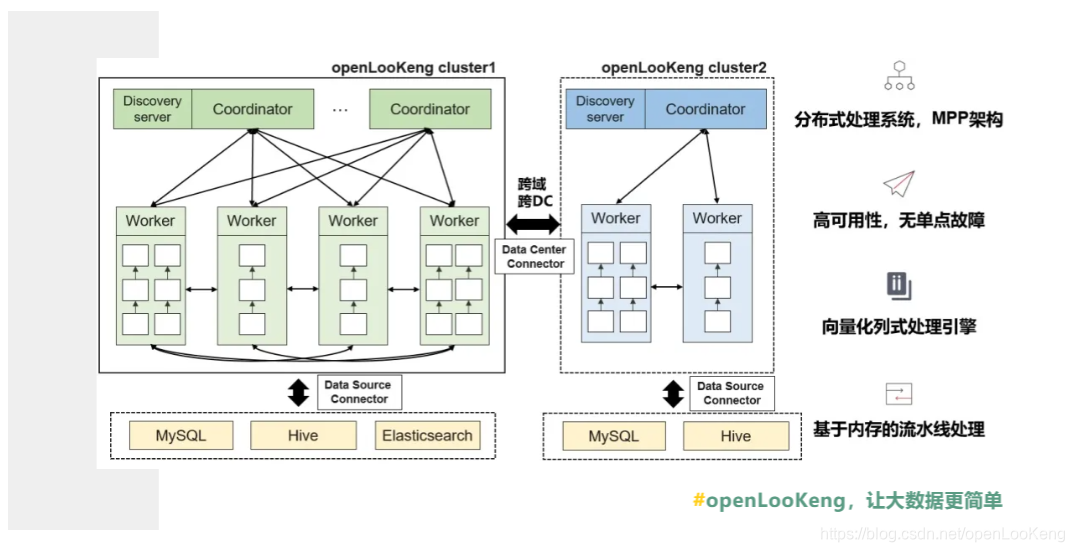
同时,openLooKeng提供以下三个特性:
(1)高可用Coordinator AA,防止单节点失效,
(2)DC Connector提供跨域分析的能力,
(3)VDM(虚拟数据集市)简化数据的开发流程。
2.1 高可用Coordinator
上图显示高可用Coordinator的架构,图中的StateStore是一个分布式缓存,当前使用的是hazelcast,它有三作用:提供lock服务,用于选出提供discovery服务的Coordinator(即主Coordinator);存储discovery信息;存储query states。
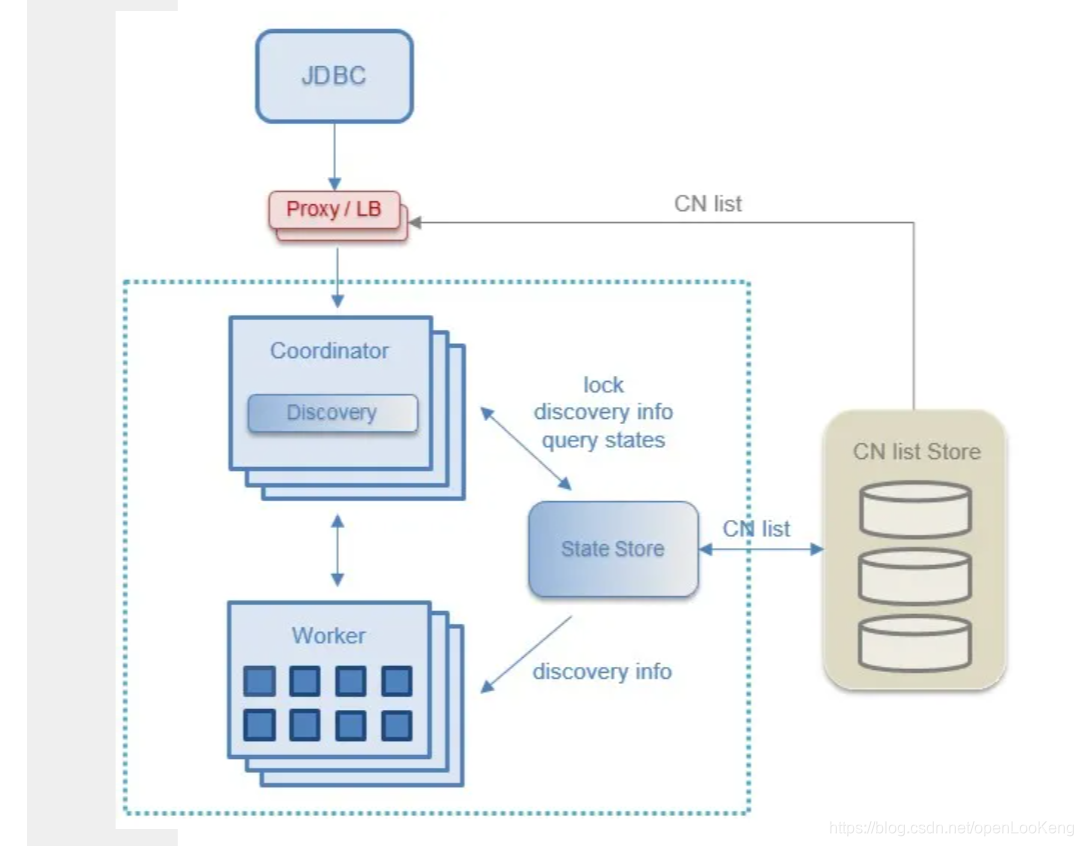
Coordinator AA的工作原理:首先,多个Coordinators在启动的时候,都会向StateStore申请lock,谁先申请到,谁就是主Coordinator,同时把自己的ip地址存储在StateStore里面;其次,worker在启动的时候,从StateStore获取主Coordinator的IP,之后的过程就和原始的过程一致;最后,如果主Coordinator挂了,则其他的Coordinator会感知,它们会去申请lock,即抢主。
Coordinator AA的作用:
(1)多Coordinator同时运行并接收客户端的查询提交,
(2)提供持续的应用可用性和抗灾能力,单个Coordinator故障不影响集群的正常运行,
(3)高并发下,可减轻单Coordinator的压力,提高吞吐量,
(4)结合Nginx等反向代理工具可实现负载均衡等高阶特性。
2.2 DC connector
DC connector和data source connector的实现类似,只不过数据源是一个DC。
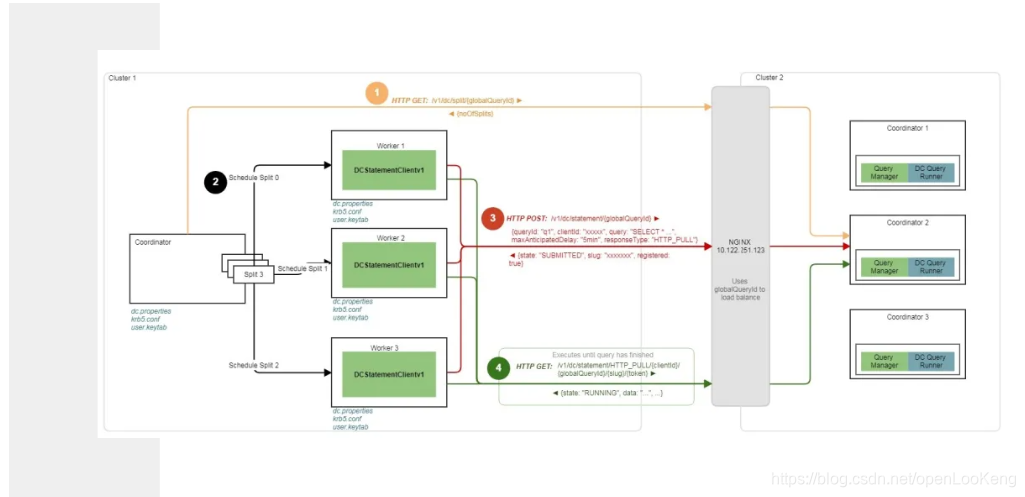
DC coonector的数据流如上图所示:
(1)获取分片,当前DC的分片是配置设置的一个值;
(2)DC1 调度分片;
(3)DC1 worker收到分片处理请求之后,向DC2发送一个Post请求,实际上是一个SQL请求;
(4)DC1的worker一直调用Http Get从DC2获取数据,直到数据获取完成。
通过DC connector打通异地数据中心数据访问,跨DC数据协同查询无需依赖数据中转平台,且通过算子下推与跨域动态过滤技术,可获得广域网部署,局域网的性能体验。
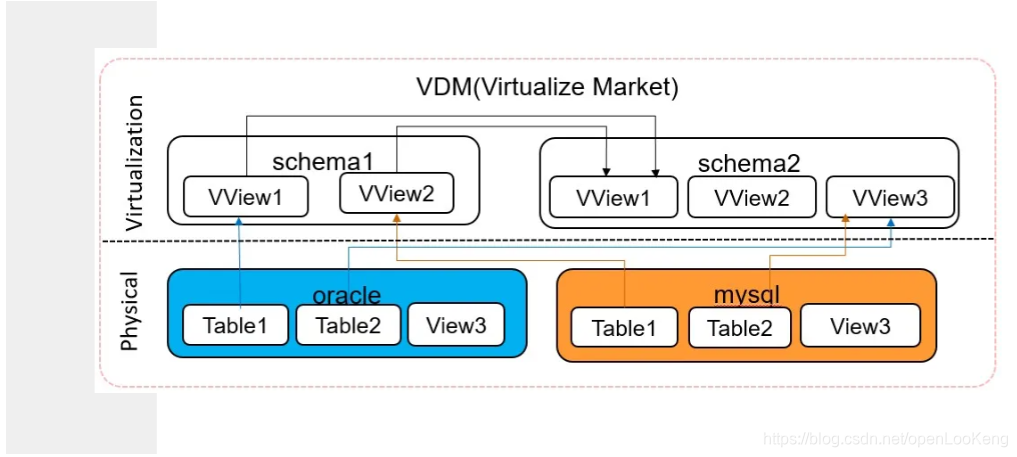
2.3 虚拟数据集市VDM
通过VDM,可方便的对底层的数据源、数据表进行管理,通过建立轻量级的视图来实现对不同数据源的模式化访问,使得用户不需要每次查询都关心数据的分布以及访问方式,从而简化数据开发过程。
3 性能优化实践
3.1 优化技巧全景
优化的技巧主要包括:
(1)在数据源侧,更适应openLooKeng,针对Hive数据源分桶/分区、小文件合并、查询字段排序等策略可以让数据源更加适配openLooKeng,提升整体性能。
(2)引擎层,增强交互式查询能力,包括多种缓存加速(执行计划缓存、元数据缓存、增量列式缓存)。
(3)增强优化器,包括谓词下推、动态过滤、RBO&CBO等提升性能。
(4)采用自适应调度器,让数据处理更贴近数据源。
(5)额外层,加速交互式查询,包括启发式索引Heuristic index layer(bitmap/bloomfilter/min-max)、Data cache layer同时提供序列化&反序列化优化。
3.2 稀疏索引
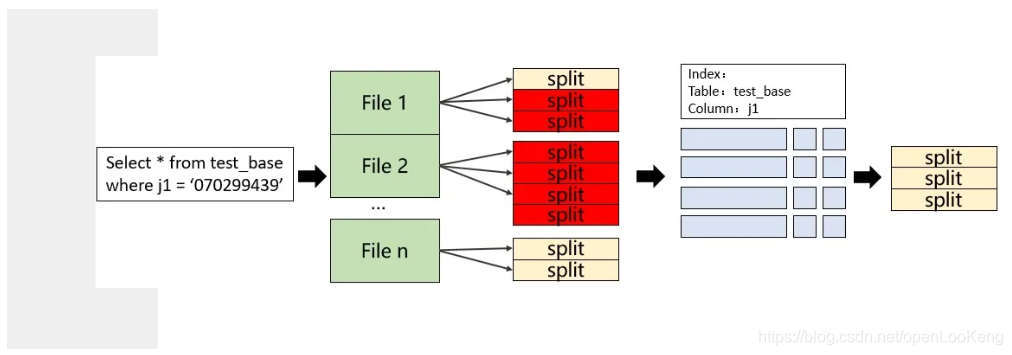
当前,Presto在分区列上已经可以进行分区过滤,但是非分区上不可以。为了应对上图中的sql,openLooKeng提供稀疏索引来进行分区裁剪。
Bloom filter索引,确定每个split是否包含要搜索的值,并只对可能包含该值的split进行读操作:
(1)可以快速判断一个集合中有无某个值;
(2)需要预先通过create index进行索引创建,openLooKeng提供类似于DB的create index命令,可以创建bloom filter、min/max和bitmap索引;
(3)通过在coordinator侧过滤,减少不必要的split生成与处理。
上图是真实客户场景的测试结果,客户的场景分析如下: (1)单表数据量很大,只有天分区,测试数据包含30天;
(2)谓词包含OR以及AND;
(3)单表点查询,聚合操作,无join。客户的要求是100并发下,30天的数据查询在3秒内返回。
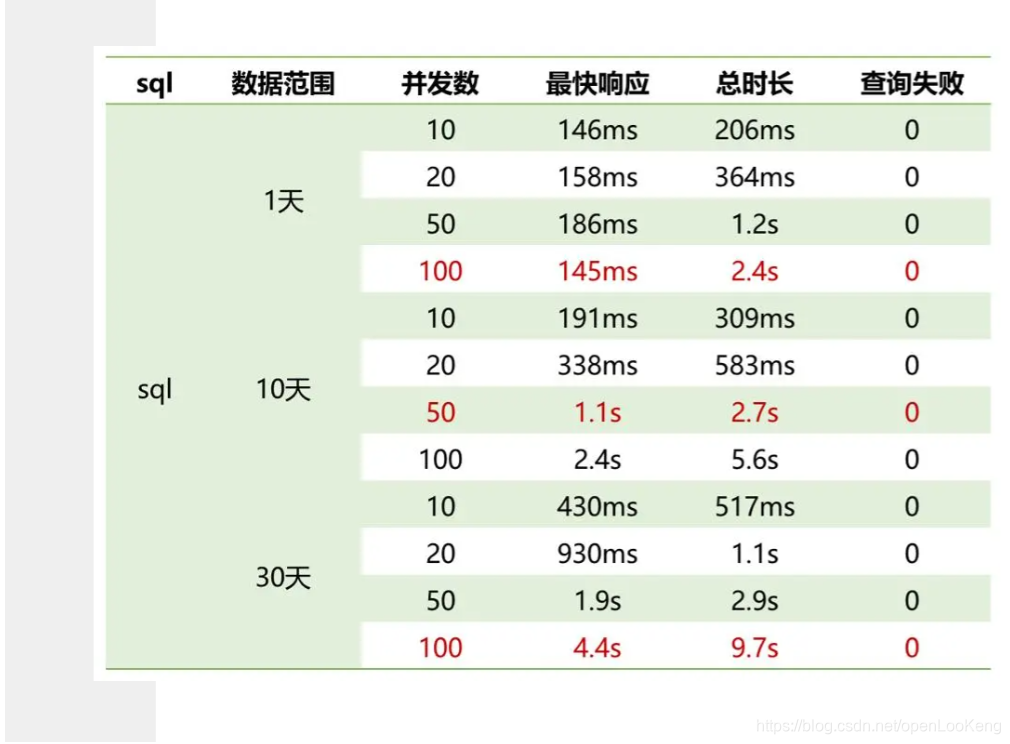
在没有创建索引前,单并发的查询性能在8~10秒左右。通过添加索引,可以看出:只50并发下都满足了需要,30天100并发的查询还存在一定差距。后续的优化思路包括:索引OR支持,并且下推OR操作;聚合场景的Aggregation Stage Cache和StarTree Index。
3.3 动态过滤
TPC-DS是TPC标准组织推出的一个广泛使用的行业标准决策支持基准,用于评估数据处理引擎的性能。在TPC-DS是一个典型的星型&雪花型的数据仓库组织方式,包含7张事实表和17张维度表,事实表数据量极大,而维度表相对较小,查询很少有谓词直接应用到事实表,事实表查询条件通过维度表相连接得到。
问题:传统谓词下推等优化很难应用,因为probe侧的表无法做到有效过滤,几乎是全表进行扫描参与join,导致join数据量巨大导致执行时间过长。
针对这种场景,openLooKeng采用动态过滤(Dynamic Filtering)技术。
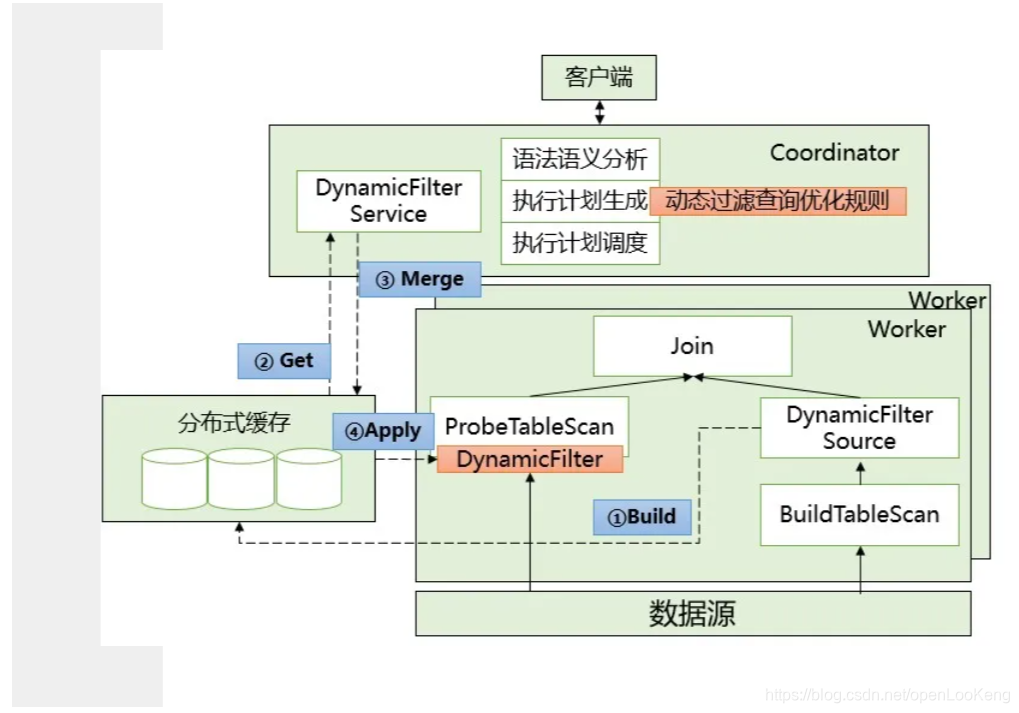
依靠join条件以及build侧表读出的数据,运行时生成动态过滤条件(dynamic filters),应用到probe侧表的table scan阶段,从而减少参与join操作的数据量,有效地减少IO读取与网络传输。
整体来看,通过在build侧表的table scan之上添加DynamicFilterSource算子,搜集build侧数据,通过分布式缓存进行DF的处理,最终经过coordinator端DynamicFilterService的合并,生成最终可以应用的条件,推送给probe侧的table scan进行数据过滤。
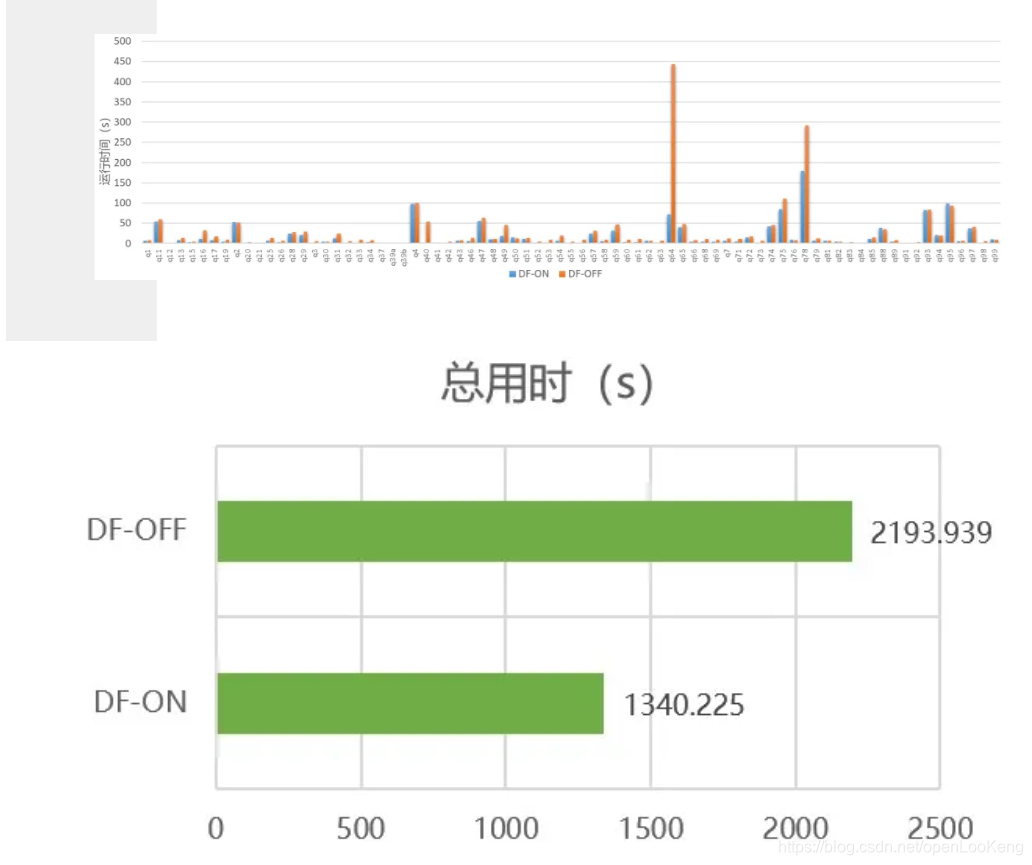
TPC-DS的性能结果如上图所示,开启动态过滤,TPC-DS测试用例的执行时间减少了38.9%。
3.4 全局动态过滤
为了提高跨DC的访问性能,openLooKeng把动态过滤应用到跨DC的数据访问,即全局动态过滤特性。设计思路如下:
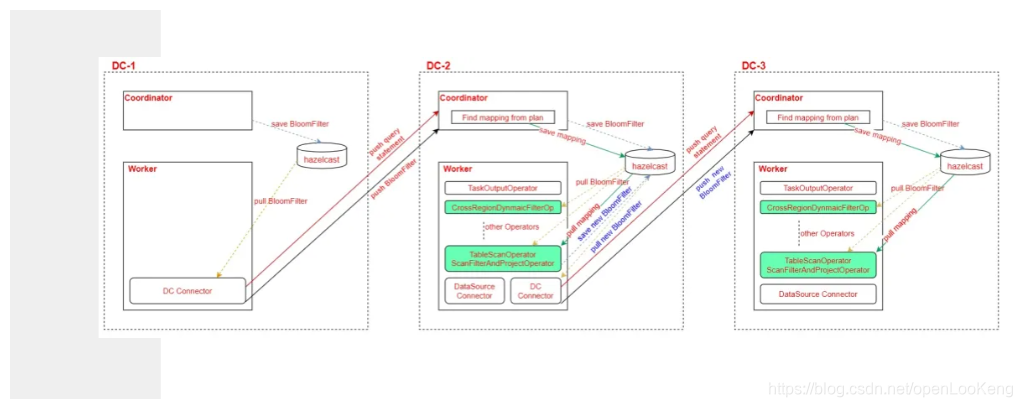
DC2 coordinator侧:
(1)增加业务用户的生产能力并提升效率;
(2)通过session判断当前query是否存在cross-region-dynamic-filter,判断依据是dc-1的DC Connector在下推子语句到dc-2时,会监测是否有dynamicFilter,若存在,则会在HTTP Request中设置属性标签,在dc-2的coordinator接收语句时,将session中的设置启用cross-region-dynamic-filter;
(3)coordinator完成子语句的Analyze会生成Plan,从Plan中提取子语句的列名到Plan中各个PlanNode的outputSymbol的映射关系,同时,在这个过程中,判断TableScanNode是否DC table,若是,则标记下来,可能存在需要继续下推filter的可能;将mapping和DC标记记录存入到hazelcast。
DC2 worker侧:
(1)CrossRegionDynamicFilterOperator从hazelcast根据queryId获取filter,通过OutputNode中columnNames和outputSymbols的映射判断是否存在需要过滤的列,若存在,则对Page中的该列进行过滤;
(2)对从Connector获取的Page数据进行过滤;涉及的Operator有三个,TableScanOperator、ScanFilterAndProjectOperator、TableScanWorkerProcessorOperator; 从hazelcast中根据queryId拉取filter,mapping,DC标记记录,然后根据规则对Page的对应列进行filter,以及生成新的bloomFilter并存入hazelcast;
(3)DC Connector从hazelcast获取是否需要下推到远端集群的filter。
性能测试如下:
SQL-2性能提升这么明显于以下几个原因:
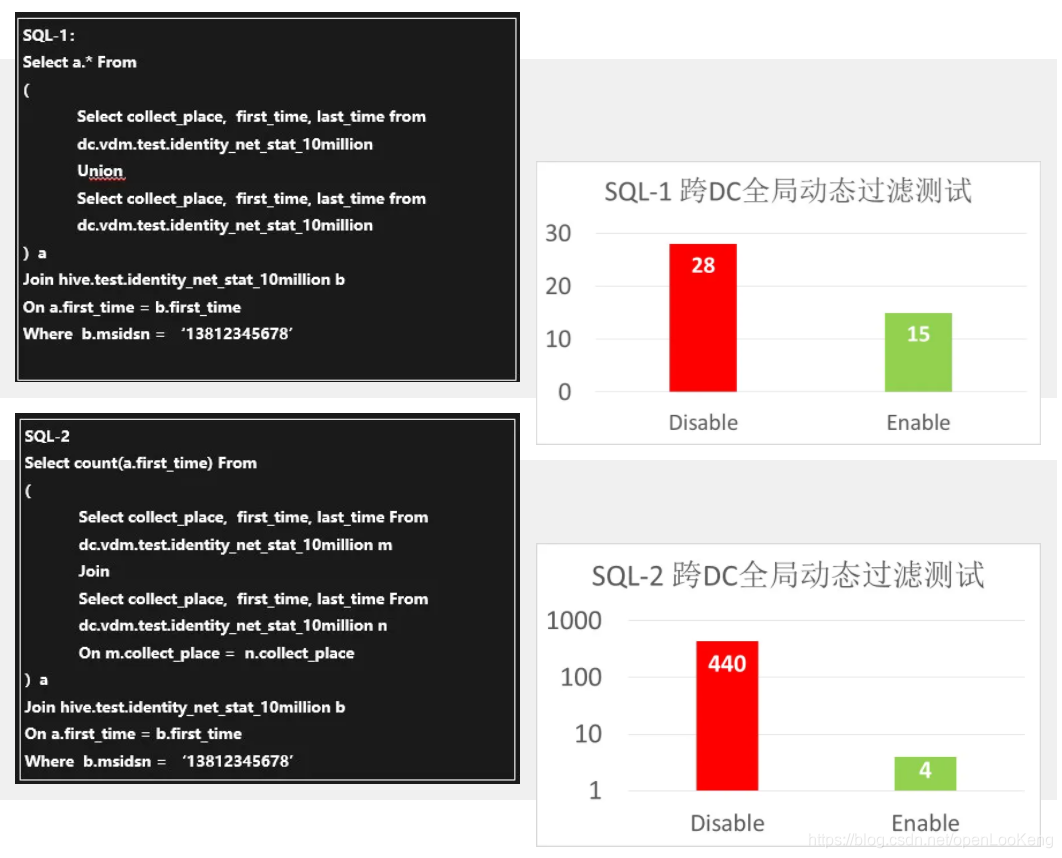
(1)通过动态过滤,DC2右表的TableScan操作之后返回给上一阶段的数据明显降低了几个数量级,从而极大的减少了数据Join的时长;
(2)减少了DC2到DC1的数据传输;
(3)在DC1上进行join的数据量极大减少了。
3.5 TPC-DS性能测试
优化技巧总结:
(1)动态过滤:q64,q78,q75,q40,q49
(2)Semi join 转 inner join:q95,q14,q93,q58
(3)window function + filter 转 Top(N+M):q67
(4)使用group by 消除self join: q95
(5)join reorder: q64

4 总结
-
统一北向数据访问接口,丰富南向数据源,实现跨数据源数据免搬迁融合分析。
-
DC connector提供跨域分析能力,并且通过全局动态过滤,算子下推,压缩断点续传,Coordinator AA等技术来提高DC connector的性能和稳定性。
-
通过元数据cache,执行计划优化,索引,动态过滤,算子下推等特性,整体提高openLooKeng的性能。
• • •
为了进一步增强引擎的查询性能,openLooKeng 最近发布的 1.2.0 版本提供了新的通用算子下推框架,让Connector 参与到执行计划中。那么,该算子下推框架是什么样的?Connector如何参与到执行计划中?本周四晚8:00,openLooKeng开发工程师罗旦将为我们一一解读。感兴趣的朋友可以听听。

openLooKeng是一款开源的高性能数据虚拟化引擎,提供统一SQL接口,具备跨数据源/数据中心分析能力,为大数据用户提供极简的数据分析体验。
openLooKeng开源社区官方网站:
https://openlookeng.io/zh-cn/
openLooKeng代码仓地址:
https://gitee.com/openlookeng