先不管CAP是什么,就谈谈对于一个分布式的系统,它有哪些特征或行为。
(1)分布式系统会把服务部署在多个节点上
(2)每个节点都有可能存储数据,一份数据可能在多个节点上有副本
(3)节点之间通过网络进行数据的同步
假设有个服务,需要部署在3个节点上,每个节点都需要存储同一份数据id,id的初始值都是1。
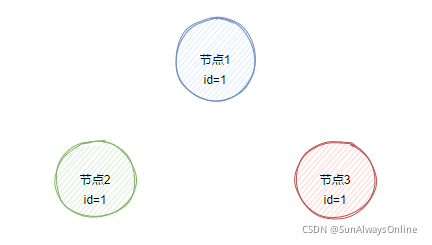
现在对节点1写入id=2,当网络正常的情况下,节点1会向节点2与节点3进行数据同步,此时3个节点的id值都是2。不管访问哪个节点,读取的id都是一样的值。

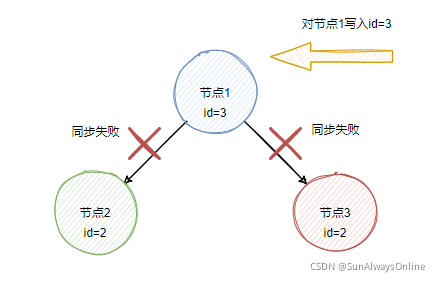
再对节点1写入id=3时,由于此时发生网络闪断,节点1无法联系到节点2与节点3,那么此时访问节点1与节点2将会得到不一样的值,出现了不一致性。
CAP理论是分布式系统中的核心理论,由三个单词的首字母组成,分别是
C(Consistence)一致性,对于指定的副本数据,访问任意一个节点,都能读到相同的值。
A(Availability)可用性,访问非故障的节点,总能在合理的时间内得到合理的响应。
P(Partition Tolerance)分区容错性,发生网络分区时,整个系统依然能对外提供服务。
一致性
对节点1执行数据更新的操作后,如果不进行同步操作,这个时候再去读取节点2的数据,就会得到不一样的结果,从而产生不一致。如果任意用户能在任意时间访问不同节点,都能得到相同的数据,那么这个分布式系统就是强一致的。
CAP中的C代表的就是强一致性,并且不考虑数据同步之间的延迟。
此外,还有
弱一致性,指的是在更新某个节点的数据之后,访问其余一小部分的节点得不到最新的结果。
最终一致性,指的是某个节点的数据之后,在一段时间内访问其他节点得不到最新的结果,但在稍后的某一个时刻,能够得到最新的结果。
可用性
指的是能在合理的时间内得到合理的响应,或者说在有限的时间内得到一个可以理解的响应。对于不同的系统,有不同的“有限时间”。“可以理解的响应”指的是要么返回执行成功,要么执行失败(但状态码是200),而不是返回404、500等。
分区容错性
网络分区指的是,由于网络是不可靠的,本来A机房与B机房可以互相访问,是一个整体。当A机房与B机房的光纤断了,A机房便不能与B机房进行通信,整体被划分成了两个区域(区域内部是可以互相通信的),于是网络也被划分成了两个区域,形成所谓的网络分区。
对于一个分布式系统,发生网络分区是必然存在的。必定不发生网络分区的系统,那就是一个单体系统,并不是分布式系统。
当然,一个分布式系统,在极端的情况下,如果要牺牲P保证AC也是可以的。
一般来说,分布式系统都会选择满足P。
那么,剩余的CA可以同时满足吗?
先说结论,在存在网络分区的情况下(即满足P),那就不可以同时满足A与C。
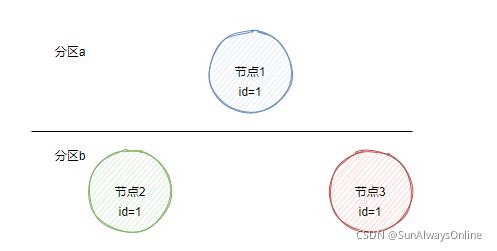
假设节点1存在于分区a中,节点2与节点3存在于分区b中。
此时修改节点1的副本数据,将id变为2
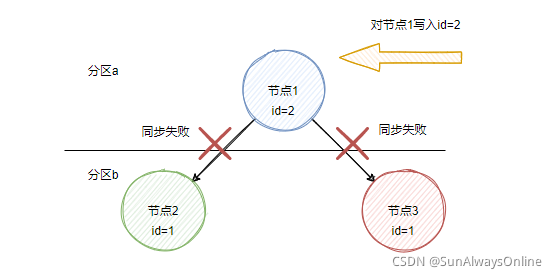
由于存在网络分区,无法将id的新值2同步到其他分区的节点下。
如果此时要满足A(可用性),且节点2与节点3只是在另外一个分区中,并没有发生节点本身的故障,由可用性的定义,三个节点都可以进行访问。
此时用户访问节点1,得到id=2,访问节点2时,得到id=1,发生数据不一致的情况。
所以,满足A的情况下,就满足不了C(一致性)。
如果一开始要满足C呢?
为了保证访问各个节点,都能用户最新更新的值,就要禁止任何对节点2与节点3的读写操作,这就违背了A。
所以,在满足C的情况下,就满足不了A。
既然在发生网络分区的时候,不能同时满足A与C,那么怎么在两者之间进行权衡呢?
选择AP
在发生网络分区的情况下,选择可用性,就要放弃一致性。
Eureka就是典型的AP系统
在Eureka集群中,各个server节点没有主从之分,都是相互平等的个体。
各个server节点会互相复制数据,产生冲突时,直接用最新的数据覆盖掉旧数据即可。
每一个client只会向一个server节点注册,server会将该client的ip等信息放入到注册列表中。
之后client会向server节点定时发送心跳并同时拉取注册列表到client的本地缓存中,超过一定时间不发送,server会将该client从注册列表中剔除。
如果一个client下线,首先需要过一段时间才能在server的注册列表中体现出来,随后才能在其他的client上的本地缓存中体现出来。因此client上本地缓存中的服务注册数据并不是最新的,因此这里不能保证强一致性。
一个server节点宕机或出现网络分区联系不上其他节点,其他节点仍然能提供注册与查询服务,因此保证了可用性。该server节点没有将自己的注册列表同步到其他节点,就会使得部分client的注册信息丢失,因此这里不能保证一致性。
当上述server节点重新上线或网络稳定后,就能将当前的注册列表同步到其他节点,整体又能达到最终一致性。
Eureka作为一个专门的服务注册与发现的系统,能够容忍数据不一致的情况(例如当A调用B,B已经下线,但A查询server时,依然能够获得B的注册信息。A随后发起对B的调用,结果肯定是调用失败,这个时候A选择重试或者直接熔断即可)。即使发生不一致的情况,也基本上是少数数据的不一致,如果这个时候直接强行让注册中心不可用,显然是忍受不了的。
选择CP
即放弃可用性
Zookeeper属于CP模型
在Zookeeper集群中,会有一个主节点与多个从节点。主节点负责写入数据,从节点负责读取数据。
客户端对zk的写入,需要等到同步到所有的从节点才会返回。
如果主节点挂了,整个集群会进入选举阶段。在选举阶段,会停止对外服务(这个时候就表现出不可用性,即不满足A),直到选举成功才会继续提供服务。
使用CAP模型来看待分布式锁
分布式锁就要求锁数据在各个节点上都是一致的,因此分布式锁的本质其实就是CP模型,如果使用主从模式的Redis来实现分布式锁,会有什么问题吗?
使用Redis去实现分布式锁,有兴趣的同学可以移步我的另外一篇文章我用了上万字,走了一遍Redis实现分布式锁的坎坷之路,从单机到主从再到多实例,原来会发生这么多的问题
首先,主从模式的Redis,是属于AP模型的。
主节点负责写入,从节点负责读取。对主节点的数据写入会立即返回,数据将会异步的同步至从节点。
如果主节点宕机,哨兵会将从节点切换为主节点,保证了可用性,但如果主节点的数据还没来得及同步到从节点时,就会发生数据不一致的情况。
如果此时client在主节点上获取到锁之后,主节点还没来得及将锁数据同步到从节点就发生宕机时,哨兵将从节点切换成新的主节点,另外一个client对此主节点申请相同的锁时,此时这两个client同时获取到锁,分布式锁便没有了意义。
因此,考虑在AP模型的主从模式的Redis上实现CP模型的分布式锁,在技术选型上就是错误的。当然考虑到实现成本、业务容忍等因素,使用AP模型去实现分布式锁也是可以的。
单机版本的Redis也可以实现分布式锁,但此Redis并不是分布式系统,CAP理论也无从谈起。
基于CP模型的Zookeeper与Etcd实现分布式锁,能够满足分布式锁要求的强一致性,但是性能不如Redis。
如果业务场景对一致性要求不高,但对性能要求较高,那就大胆使用Redis吧。
一些注意点
CAP描述的是,当系统能容忍网络分区时,只能在可用性与一致性中进行抉择。当然,你以可以理解为三者不可能同时存在,只能三选二。但是一个分布式系统,如果在发生网络分区时,直接就不对外服务了,确实不太符合绝大多数业务的需要。
出现网络分区时,只能在可用性与一致性中进行抉择。但是当没有出现网络分区的时候,系统是可以同时保证可用性与一致性的。
另外,当描述一个系统是AP模型还是CP模型时,并不是从系统整体出发,而是从某一个局部出发的。一个分布式系统,可能有些模块需要保证AP,有些模块又需要保证CP。
CAP中的一致性,是强一致性,并且认为数据同步是瞬间完成的,也就是不考虑网络的延迟,系统要么是一致的,要么是不一致的,没有中间过渡的过程。真实的业务场景中,数据同步的过程是肯定要花费时间的。CAP理论只是描述出现网络分区时,系统应当处于什么状态,但是并不去管这些状态如何转化,因此后来出现了BASE理论,是对CAP理论的延伸及补充。
BASE理论
可以理解为,不要求做到强一致性,系统或者模块可以采用一种渐进同步的方式,在业务可以忍受的时间内,来达到一致性,即最终一致性。
BASE由以下几个单词组成:
BA,Basically Available,基本可用
在系统前期的设计中,需要考虑当系统出现一些比较严重的问题从而使得整个平台不可用的场景。
为了避免整个平台不可用,可以选择牺牲部分模块来保证核心模块可用。
例如当流量暴涨的时候,选择一系列诸如熔断、限流、降级、数据切片等措施,来使得绝大多数用户可以访问核心模块。
S,Soft state,软状态
软状态是CAP中的强一致到最终一致的中间状态,允许数据同步存在时间延迟。
例如,为了提高系统的吞吐量与性能,存在于消息队列中的数据以及即将要进行补偿的数据,这些数据的状态就是软状态。
(关于消息队列如何保证消息不丢失,可以参考我的这篇文章RabbitMQ如何在各个环节保证消息不丢失)
E,Eventually consistent,最终一致性
系统中的副本数据,在经过一段时间的同步之后,最终能得到一致的状态。
例如,消费端完成消费的数据以及补偿完毕的数据,将会使得在某个时间范围内的所有副本数据达成最终一致。
BASE理论弥补了CAP理论中的不足,为保证数据一致提供了一种新的思路。有时候为了提升性能,不需要刻意使用ACID来保证强一致性,只需要在业务能够容忍的时间内达成最终一致即可。