默认情况下是Intel I9,10核,每个核2个threads,共20个CPUs:
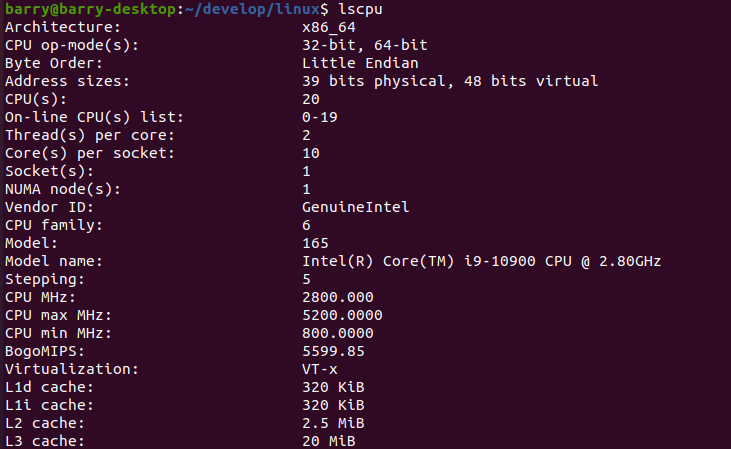
下面编译内核:

需要2分钟30秒左右。
再来一遍:

这说明make clean, drop_caches后时间也差不多。
现在我们关闭smt,只保留10个CPU:
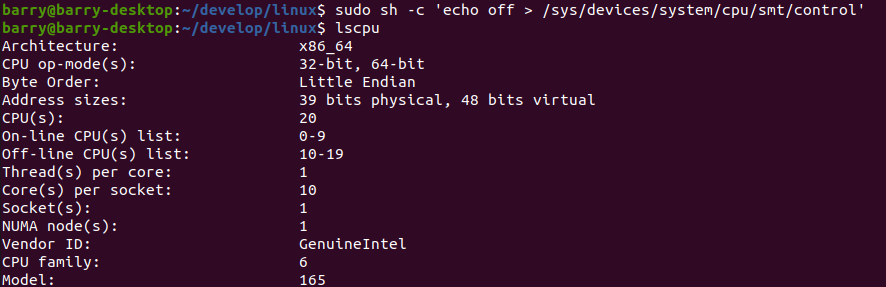
具体的关闭方法就是:
sudo sh -c 'echo off > /sys/devices/system/cpu/smt/control'这样只剩下10个CPU,下面来编译:

时间2分51秒,相对于2分30秒,速度下降仅仅14%。
这说明超线程SMT对性能的提升绝对没有达到100%,甚至都没有达到20%。
我们现在重新开启超线程:
sudo sh -c 'echo on > /sys/devices/system/cpu/smt/control'看一下哪个CPU和哪个CPU是thread sibling:

看起来CPU0和CPU10是一对,CPU1和CPU11是一对,依次类推。
刚才我们关闭SMT是把CPU10-CPU19全关了,只留下每对里面的1个CPU,也就是留下了CPU0-CPU9。
在开启SMT的时候(假设蓝色和红色是一个CORE里面的两个CPU):

在关闭SMT的时候,等于每对里面只留1个CPU:

现在我们换一种关法,一对对关,只留下五对:

指令如下:
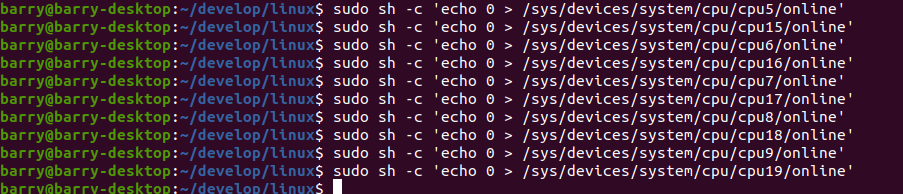
实现效果如下:
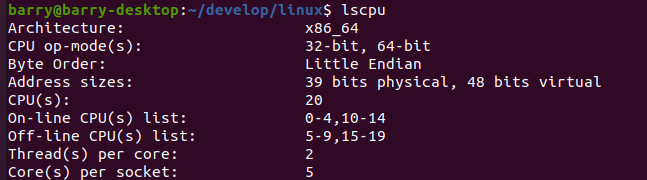
再重新编译内核:

现在耗时是3分10秒,想对于所有CPU全开,下降27%。相对于每个core里面只关一个线程,下降12%。
这就比较神奇了?为什么我关了5个core,性能没有下降100%呢?这至少说明一个问题,从5core到10core,Intel I9编译内核性能并没有线性地scale。只是从3分10秒,提升到2分30秒。