美团2020年发表的《Multi-modal Knowledge Graphs for Recommender Systems》
https://zheng-kai.com/paper/cikm_2020_sun.pdf
1 背景
知识图通过引用各种有效的辅助数据用于推荐系统,有效的解决了推荐系统的冷启动和数据稀疏性问题。
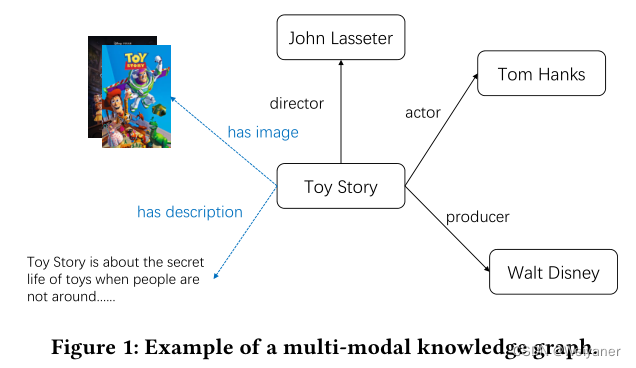
但是一般的知识图没有考虑多模态信息的作用,比如商品的图片评论信息。多模态知识图(MKG)将视觉或文本信息引入知识图,将图像或文本视为实体或实体的属性,如下图。
基于知识图的表示学习在推荐中有着关键作用,通常用来学习实体信息的嵌入。多模态知识图中,通常有两种方法
-
基于特征的多模态图
将多模态信息作为实体的一个辅助特征,通过视觉表征模型对视觉信息进行提取,视觉表征可以从与知识图谱实体相关的图像中提取。在这些方法中,三元组的得分是根据知识图谱的结构以及实体的视觉表征来定义的,这意味着每个实体必须包含图像属性。这对知识图谱的数据源提出了相对的要求,因为它要求知识图谱中的每个实体都有多模态的信息。
然而,在真实场景中,一些实体并不包含多模态信息。所以这种方法不能被广泛使用。
-
基于实体的多模态图
将多模态信息视为结构化知识的关系三要素,而不是预先确定的辅助特征。然后使用基于CNN的KGE方法来训练知识图谱的嵌入。然而,现有的基于实体的方法独立处理每个三元组,忽略了多模态信息的融合。虽然解决了基于特征的方法中对MKGs数据源的高要求问题,但它只关注实体之间的推理关系,而忽略了多模态信息的融合。
事实上,多模态信息通常是作为一种辅助信息来充实其他实体的信息。因此,我们需要一种直接的互动方式,在对实体之间的推理关系进行建模之前,将多模态信息明确地融合到其相应的实体中。
2 基于知识图的推荐模型
对于一个知识图,每个实体都是由三元组关系组成。三元组:<主体,关系,客体>
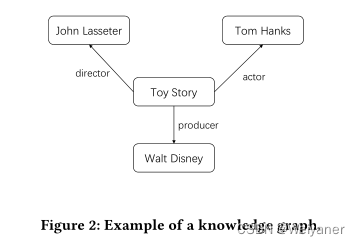
基于知识图结构的推荐,主要分为三类,
-
基于嵌入的方法
首先嵌入算法对知识图谱进行预处理,然后在推荐框架中使用学到的实体嵌入,将各种类型的侧面信息统一到推荐框架中。
-
基于路径的方法
基于路径的方法[33, 36]探索知识图谱中实体之间的各种连接模式,为推荐系统提供额外的信息。例如,关于知识图谱作为一个异质信息网络(HIN),个性化实体推荐(PER)[33]和基于元段的推荐[36]提取元段/元段的潜在特征来表示用户和项目之间沿着不同类型的关系路径/图谱的连接。
基于路径的方法以一种更自然、更直观的方式利用知识图谱,但它们在很大程度上依赖于手工设计的元路径,这在实践中很难被优化。另一个问题是,在某些实体和关系不属于一个领域的情况下,不可能设计出手工制作的元路径。
-
基于融合的方法
基于嵌入的方法利用KG中实体的语义表示进行推荐,而基于路径的方法则利用KG中实体之间的连接模式。这两种方法都只利用了KGs中的一个方面的信息。为了充分地利用KGs中的信息进行更好的推荐,人们提出了统一的方法,它整合了实体和关系的语义表示。
以上基于知识图谱的推荐,虽然引入了图结构的各种辅助信息,但是在多模态数据的建模上有所缺陷。
3 多模态知识图的推荐
3.1 任务描述
输入:协同知识图谱,包括用户-物品交互图和多模态知识图
输出:用户对物品的预测概率
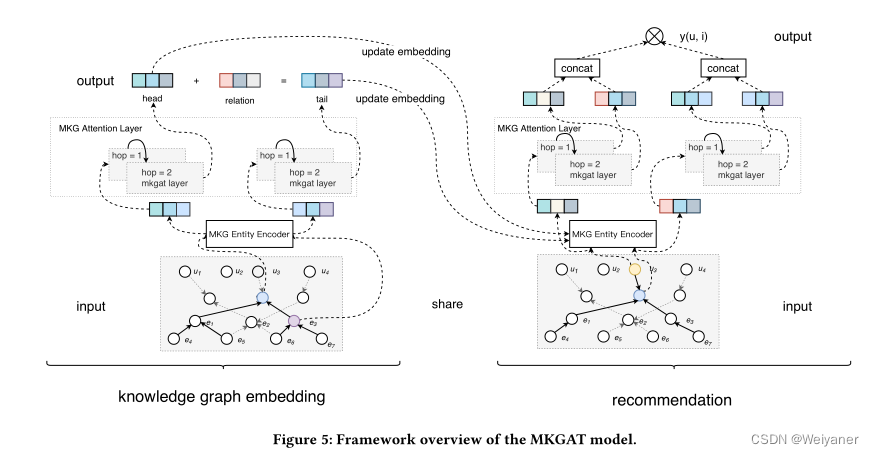
3.2 Multi-modal Knowledge Graph Attention Network (MKGAT)
模型的基础模块
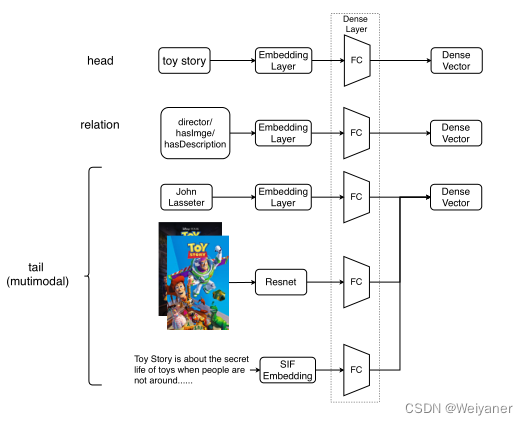
1. 多模态知识图谱实体编码器
对不同的数据类型,使用不同的编码器进行嵌入。本质上,为所有实体提供一个嵌入。
- 结构化数据
对于主体,关系,客体表示为独立的嵌入向量。 - 图像数据
使用resnet50的最后一个隐含层数据作为嵌入表征 - 文本数据
使用word2vec作为训练词向量,应用平滑反频率(SIF)模型[1]来获得一个句子的词向量的加权平均值,作为句子向量来表示文本特征。
最后,使用密集层将实体的所有模态统一到同一维度,
2. 多模态知识图注意力层
通过注意力机制将每个实体的邻居实体信息汇总到自身,得到加权后的实体嵌入。
下图的MKGs注意层,它沿着高阶连接性递归传播嵌入[10]。此外,通过利用图注意网络(GATs)的思想[22],我们产生了级联传播的注意力权重,以揭示这种连接的重要性。尽管GATs很成功,但它们并不适合于KGs,因为它们忽略了KGs的关系。因此,我们修改了GATs以考虑到KGs的嵌入关系。
对于一个单层模型,由传播层和聚合层构成。
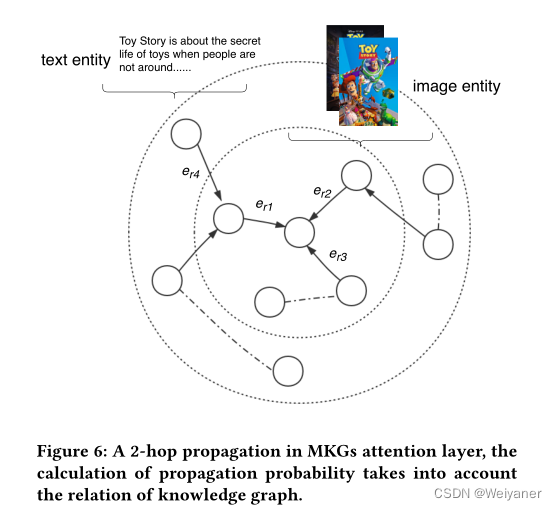
传播层:
对于候选实体h,在学习嵌入过程中,考虑两方面,第一是根据transE模型学习实体三元组的结构化表示,然后对于实体的多模态邻居信息,汇总到实体上,得到实体聚合邻居实体信息的表征向量e_agg.
(前者是后者的注意力得分)
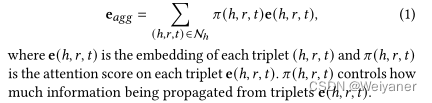
对于三元组结构嵌入,使用<h,r,t>的嵌入进行线性变化得到:

对于三元组的注意力得分,通过leakyRelu函数和softmax函数求解。

聚合层(Aggregation Layer)
对实体信息和邻居的聚合信息的在聚合,得到新的实体嵌入。
可以通过两种方法:
(1) 加和
(2)串联聚合

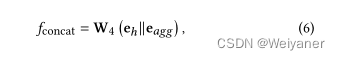
高阶传播
通过堆叠更多的传播和聚合层,我们探索了协作知识图谱中固有的高阶连接性。
一般来说,对于一个n层模型,传入的信息是在一个n-hop的邻居上积累的。
3. 多模态知识图嵌入模块
嵌入模块利用多模态知识图谱(MKGs)实体编码器和MKGs注意层为每个实体学习新的实体表示。
新的实体表征聚合了其邻居的信息,同时保留了关于自身的信息。然后,新的实体表示可以用来学习知识图谱嵌入,以表示知识推理关系。

4. 推荐模块
得到每一个实体的嵌入信息后,输入到推荐模块。
为了保留1-n hop的信息,保存了候选用户和项目的输出信息,不同层的输出表达着不同层的hop信息。通过串联拼接这些表达:
最后通过内积,得到用户和项目的预测得分:

进一步,通过贝叶斯个性化排名BPR损失函数来优化目标函数
总上,得到MKGAT的模型结构
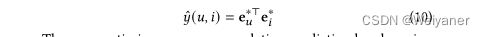

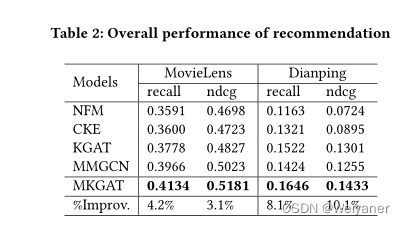
4 实验
在Movielens数据集和dainping数据集上: