0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。强基计划实现从理论到实践的全面覆盖,由本人亲自从底层编写、测试与文章配套的各个经典算法,不依赖于现有库,可以大大加深对算法的理解。
1 层次聚类
层次聚类(hierarchical clustering)的核心原理是在不同距离层次对数据集进行划分,从而形成树形的聚类结构。划分方式通常分为自底向上和自顶向下两种。
AGNES算法是一种采用自底向上聚合策略的层次聚类算法,其核心原理是先将数据集中每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个簇进行合并,该过程不断重复直至达到预设的聚类簇个数。
2 簇间距离度量
如何度量AGNES算法原理中的“距离最近”?有如下方式
- 最小距离
d min ( C i , C j ) = min x ∈ C i , z ∈ C j d i s t ( x , z ) \mathrm{d}_{\min}\left( C_i,C_j \right) =\min _{\boldsymbol{x}\in C_i,\boldsymbol{z}\in C_j}\mathrm{dist}\left( \boldsymbol{x},\boldsymbol{z} \right) dmin(Ci,Cj)=x∈Ci,z∈Cjmindist(x,z) - 最大距离
d max ( C i , C j ) = max x ∈ C i , z ∈ C j d i s t ( x , z ) \mathrm{d}_{\max}\left( C_i,C_j \right) =\max _{\boldsymbol{x}\in C_i,\boldsymbol{z}\in C_j}\mathrm{dist}\left( \boldsymbol{x},\boldsymbol{z} \right) dmax(Ci,Cj)=x∈Ci,z∈Cjmaxdist(x,z) - 平均距离
d a v g ( C i , C j ) = 1 ∣ C i ∣ ∣ C j ∣ ∑ x ∈ C i ∑ z ∈ C j d i s t ( x , z ) \mathrm{d}_{\mathrm{avg}}\left( C_i,C_j \right) =\frac{1}{\left| C_i \right|\left| C_j \right|}\sum_{\boldsymbol{x}\in C_i}{\sum_{\boldsymbol{z}\in C_j}{\mathrm{dist}\left( \boldsymbol{x},\boldsymbol{z} \right)}} davg(Ci,Cj)=∣Ci∣∣Cj∣1x∈Ci∑z∈Cj∑dist(x,z) - 豪斯多夫距离
d i s t H ( X , Z ) = max { d i s t h ( X , Z ) , d i s t h ( Z , X ) } \mathrm{dist}_{\mathrm{H}}\left( X,Z \right) =\max \left\{ \mathrm{dist}_{\mathrm{h}}\left( X,Z \right) ,\mathrm{dist}_{\mathrm{h}}\left( Z,X \right) \right\} distH(X,Z)=max{ disth(X,Z),disth(Z,X)}
当簇间距离采用 d min \mathrm{d}_{\min} dmin、 d max \mathrm{d}_{\max} dmax、 d a v g \mathrm{d}_{\mathrm{avg}} davg计算时,AGNES算法被相应地称为单链接(single-linkage)、全链接(complete-linkage)与均链接(average-linkage)算法。
3 AGNES算法
算法主要分两步:初始化和迭代更新
- 初始化
- 迭代更新


4 Python实现
本节是第三节算法原理的复现,建议对比学习
4.1 初始化
# 初始化簇
kCluster = {
i: [self.dataSet[i]] for i in range(self.m)}
# 初始化距离矩阵
M = np.zeros([self.m, self.m], dtype=float)
for i in range(self.m):
for j in range(i + 1, self.m):
M[i][j] = self.pFunc(kCluster[i], kCluster[j])
M[j][i] = M[i][j]
# 设置当前聚类簇数
q = self.m
4.2 合并最近的两个簇
# 找出距离最近的两个聚类簇
minDist, inew, jnew = 99999999, 0, 0
for i in range(q):
for j in range(i + 1, q):
if M[i][j] < minDist:
minDist, inew, jnew = M[i][j], i, j
# 合并这两个簇
kCluster[inew].extend(kCluster[jnew])
4.3 更新距离矩阵
# 删除距离矩阵被合并的jnew行、jnew列
M = np.delete(M, [jnew], axis=0)
M = np.delete(M, [jnew], axis=1)
# 更新距离矩阵
for j in range(q - 1):
M[inew][j] = self.pFunc(kCluster[inew], kCluster[j])
M[j][inew] = M[inew][j]
# 更新簇数
q = q - 1
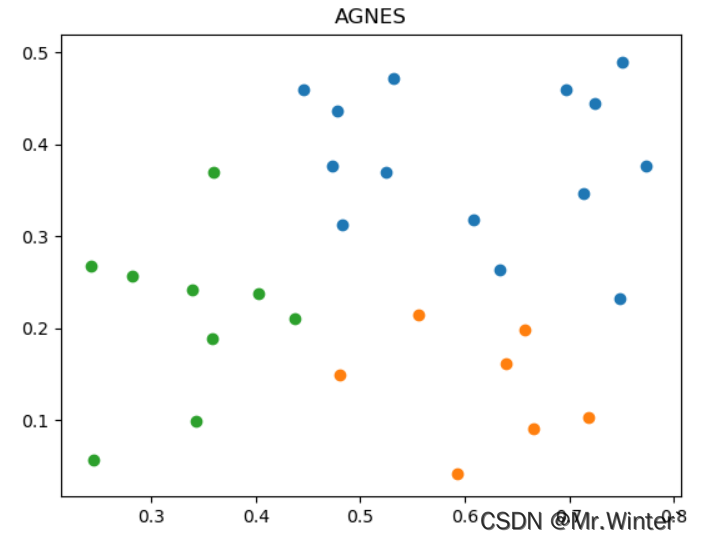
4.4 可视化
def plotGraph(self) -> None:
kCluster = self.run()
for i in kCluster:
x = np.array(kCluster[i])[:,0]
y = np.array(kCluster[i])[:,1]
plt.scatter(x,y)
plt.title("AGNES")
plt.show()
本文完整工程代码联系下方博主名片获取
🔥 更多精彩专栏: