业绩爆发:2025年营收15.05亿元,同比激增243.37%,年复合增长率超200%;归母净利润为-10.24亿元,亏损同比收窄幅度为36.70%。
技术突破:旗舰级产品MTTS5000实现规模化量产,单卡AI稠密算力达1000 TFLOPS,居行业前列。
生态加速:率先完成GLM-5、MiniMax M2.5、Kimi K2.5、Qwen3.5等SOTA大模型的深度适配,实现“即出即用”。
2月27日,摩尔线程智能科技(北京)股份有限公司(证券代码:688795,以下简称“摩尔线程”)发布《2025年度业绩快报》。根据业绩快报,报告期内,公司2025年营收为15.05亿元,较2024年同期增长243.37%。归属于母公司所有者的净利润为-10.24亿元,与上年同期相比,亏损收窄幅度为36.70%。此外,基本每股收益(元)、加权平均净资产收益率同比均有所改善,展现出稳健向好的发展态势。
对于此次业绩的表现,摩尔线程在公告中表示,得益于人工智能产业蓬勃发展及市场对高性能GPU的强劲需求,公司以AI训推一体智算卡MTT S5000为代表的产品竞争优势进一步扩大,市场关注与认可度持续提升,推动收入与毛利增长,整体亏损幅度同比收窄。
业内人士认为,GPU行业具有行业壁垒高、重研发投入、研发周期长等特征,其发展需跨越芯片设计、软件适配、应用场景落地等诸多考验。在此背景下,企业成长普遍遵循“研发攻坚—营收放量—亏损收窄—盈利兑现”的发展路径,摩尔线程当前的业绩表现与之高度相似,具体表现为:
其一,营收跨越式增长,摩尔线程2022-2025年营收从0.46亿元增长至15.05亿元,年复合增速超200%;其二,研发持续强势投入,2022年至2025年上半年,摩尔线程累计投入金额超43亿元,始终遵循“以研发驱动技术突破”的策略;其三,亏损持续收窄,公司规模效应初步显现,核心经营指标持续改善。
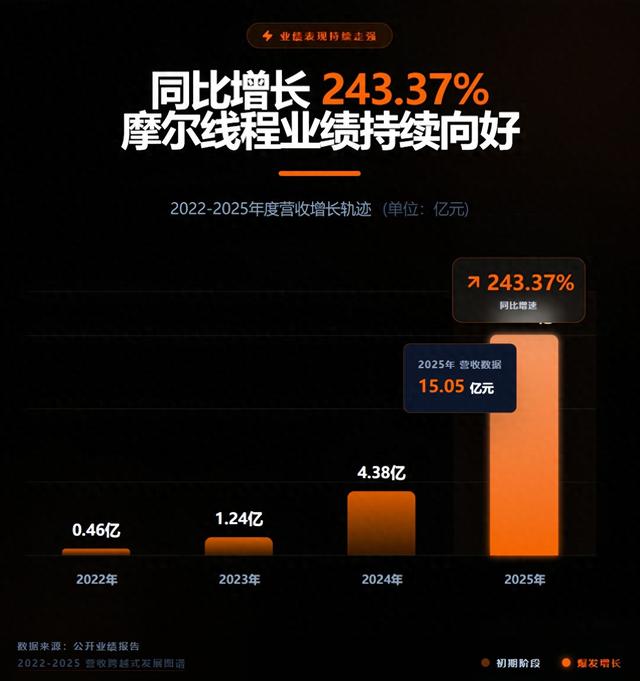
由此可以看出,摩尔线程正处于从“研发攻坚期”向“规模化盈利”过渡的关键节点。随着技术壁垒不断夯实、产品矩阵日趋成熟、MUSA生态持续扩容,摩尔线程有望延续行业已有的成功路径,加速步入盈利周期。
值得关注的是,摩尔线程旗舰级产品智算卡MTT S5000正加速规模化量产。基于该产品搭建的大规模集群已上线服务,可高效支持万亿参数大模型训练,计算效率达到同等规模国外同代系GPU集群先进水平,且具备全精度、全功能的通用计算能力,成为驱动其业绩增长与商业化落地的重要引擎。
据悉,MTT S5000基于第四代MUSA架构“平湖”打造,是专为大模型训练、推理及高性能计算而设计的全功能GPU智算卡,其单卡AI稠密算力最高可达1000 TFLOPS,配备80GB显存,显存带宽达到1.6TB/s,卡间互联带宽为784GB/s,完整支持从FP8到FP64的全精度计算。
同时,依托MUSA全栈平台,MTT S5000实现了对PyTorch、Megatron-LM、vLLM及SGLang等主流AI生态的深度兼容与平替。“零成本”迁移能力极大地缩短了客户的部署周期,显著降低了算力切换的综合成本,为规模商业化扫清了落地障碍。无论是构建大规模训练集群,还是部署高并发、低延迟的在线推理服务,MTT S5000均展现出对标国际主流旗舰产品的卓越性能与稳定性,彰显国产算力底座的硬核实力。
在AI模型迭代以“周”为单位的背景下,算力底座的敏捷交付能力已成为商业竞争的分水岭。2026年春节前后,凭借MUSA架构卓越的生态兼容性和广泛的算子库,MTTS5000已高效完成对GLM-5、MiniMax M2.5、KimiK2.5及Qwen3.5等SOTA大模型的深度适配。通过原生FP8加速、SGLang-MUSA引擎调优以及对MUSA C/C++、Triton-MUSA与TileLang-MUSA的原生支持,MTT S5000在确保模型精度的同时,显著降低了开发者的迁移门槛与算力切换成本,彰显了国产算力底座从模型适配到高效部署的全链路支撑能力与常态化响应优势。
未来,随着AI产业持续深化、国产替代加速推进,摩尔线程将持续以技术自主创新为核心驱动力,深化MUSA架构生态迭代完善,加速推进MTT S5000规模化量产与国产大模型生态快速适配,全面提速商业化落地与市场拓展,携手产业链上下游伙伴共建开放协同的国产算力生态,以更强劲的成长动能推动业绩持续向好发展。