第一章
解释了机器学习是什么,数据为什么可以通过模型预测,模型又是什么,怎么选模型和怎么训练模型?作者对我们的疑虑进行了深层的探索,并且用了很多理论去支撑自己的观点,接下来我们省去一些背景介绍和复杂的公式推理,直接由浅入深学习这些知识。
首先,机器学习是什么?
起初,我们想通过历史数据找到一些规律,并拿它来预测新的事物。(比如我们通过观察前几天的天气,发现多云的天气往往会下雨,而今天恰好是多云的天气,因此我们预测今天很有可能会下雨。)
找到规律意味着我们假设每个单一事件的发生都不是个例,而是服从于总体的一些规则。而这个假设在概率论中就是每个事件是服从于同一个分布的,同时我们会假设每个基本事件的发生都是独立的(事件A的发生与否不会影响事件B是否发生)。
现在我们明白了机器学习就是假设数据是独立同分布的,而这个同分布的假设就是机器学习概念的支撑点(若历史数据都是个例,那么这个经验就没有办法适用于新事物)。
基于这个假设,我们再去探索机器学习到底是怎么找到数据之间的规律,怎么去预测新事物的?
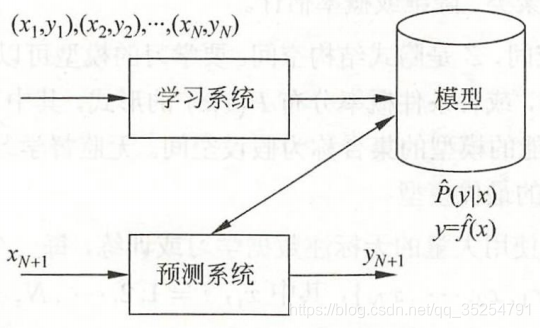
假设我们给的历史数据是X,Y(X是我们观察的因,Y是我们由观察到的X所下的结论),他们服从联合概率分布P(X,Y)。
而我们让机器学习的过程就是指定一类模型,让这一些模型去拟合这些数据。例如,我们选的是多项式函数模型,
我们让多项式函数去拟合数据,其实本质就是通过设置让拟合误差最小化,使我们找到最适合数据的多项式函数的参数
,此时我们就可以说模型学习到了数据的规律。因此我们可以说机器学习就是选择了一个能更好拟合数据的模型。
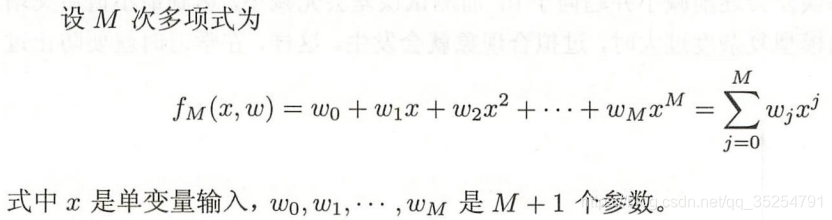
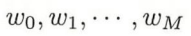
我们假设选中某类模型(可以是线性模型),此时所有这类模型构成了模型的假设空间。而我们用某种策略确立模型选择的方向,比如让模型朝着拟合程度更高的方向去选择。而我们怎么定义选择的策略(方向)呢?
损失函数用来表示模型一次预测下预测值和真实值的不一致性。(此时需要注意的是这个预测值是对我们放进去训练的数据的预测,并不是对新事物的预测,所以这个损失函数只是提供反馈供我们更好的选择模型)。损失函数的类别:
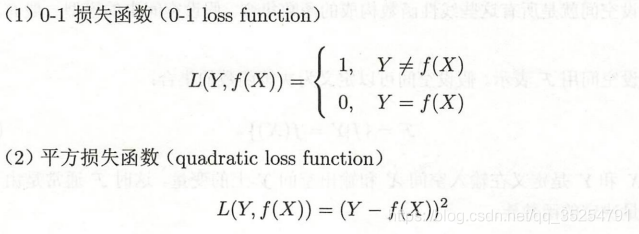

此时,我们把损失函数对所有数据在平均意义下的值(期望值),又称期望风险函数,作为我们需要最小化的目标:
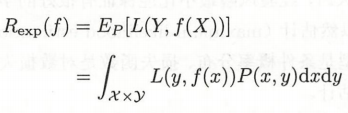
而此时联合分布P(X,Y)是我们没有办法得到的,因为我们的假设是存在这个联合分布,希望用模型去尽可能的学习到这个分布。如果事先就能得到分布,可以直接用概率论的知识求得Y下事件X下发生的概率了。因此我们没法得到损失函数对所有数据的平均值,我们手上只有拿进去训练的那些数据。
为了得到风险函数的值,我们找到能用手上的数据去代替整体数据的方式。根据大数定律,当样本容量N趋近于无穷大时,期望风险函数等于样本的损失函数的平均值,也称经验风险函数,如下。
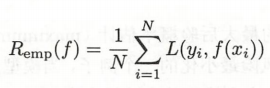
但是,正如上文所说,N趋近于无穷才能等价,若样本容量较小时,经验风险函数并不能等同于期望风险。如果我们朝着经验风险最小化的目标去选择模型,可能会导致模型拟合样本点十分好,但是对新数据的拟合十分差的效果,这种现象就叫过拟合,这是因为我们选择模型的方向距离全局拟合差距太远。
过拟合现象可以用两个方式解决:
1.用结构风险函数代替经验风险函数;
2.用交叉验证方式将新数据的预测损失最小化。
其中,第一个方案是在经验风险函数上增加惩罚项,惩罚项为Lp范数(范数是度量向量的大小和方向的工具)的变式与参数(lambda)的乘积。
如下,L1范式:
L2范式的平方:
而含有L1范式的结构风险函数可以起到迫使一些系数估计值为0,即可以起到过滤掉某些维度变量的作用。
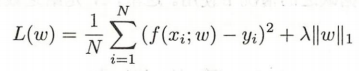
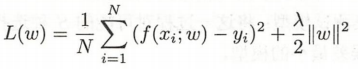
我们可以认为上述式子是求解一个最优化问题(在本问题中为最小化问题),而我们令系数w的模数之和(惩罚项)小于等于 s。其中,s
是一个随收缩因子 λ 变化的常数。假定在给定的问题中有 2 个参数。那么根据上述公式 |w1|+|w2|≤ s,只有在由 |w1|+|w2|≤ s
给出的菱形中,我们才能找到具有最小损失函数的系数。同样地,对带有 L2范数的损失函数而言,方程变为 w1² + w2² ≤ s。这意味着在由
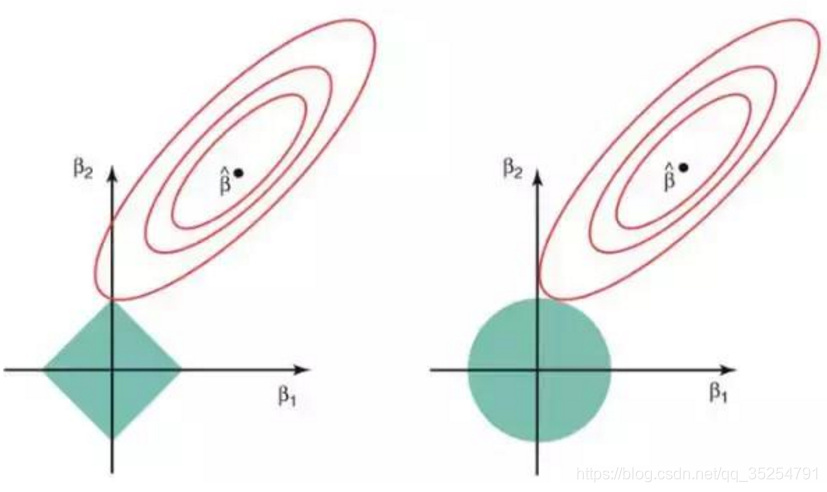
w1² + w2² ≤ s 给出的圆的所有点当中,我们才能找到具有最小损失函数的系数。下图的绿色区域代表约束函数域:左侧代表包含L1范式的损失函数,右侧代表包含L2范式的损失函数。其中红色椭圆是经验风险函数(L(w)砍去惩罚项)的等值线,即椭圆上的点有着相同的
Remp 值。
对于一个非常大的 s
值,绿色区域将会包含椭圆的中心,使得两种回归方法的系数估计等于最小二乘估计。但是,上图的结果并不是这样。在上图中,系数估计是由椭圆和约束函数域的第一个交点给出的。因为右侧函数的约束函数域没有尖角,所以这个交点一般不会产生在一个坐标轴上,也就是说L2正则化损失函数的系数估计全都是非零的。然而,L1正则化函数域在每个轴上都有尖角,因此椭圆经常和约束函数域相交。发生这种情况时,其中一个系数就会等于
0。在高维度时(参数远大于 2),许多系数估计值可能同时为 0。
原理:因为过拟合常常会导致模型复杂度增高,我们通过对模型的复杂度赋予权重,在最小化目标函数时可以使模型的复杂度一并减小,从而可能间接的控制了过拟合现象的发生的程度。(因为过拟合和模型复杂度升高并不一定互为充要条件,只是一个定性的分析)
其中,第二个方案是我不把所有的数据拿出来训练,而是把他们分成多份,一份拿来训练,另一份拿来预测,以预测效果好的方向来选择模型。
其中要涉及到几种分数据的方式:
1.直接分成两块——简单交叉验证;
2.分成互不交叉且大小相等的K块,其中每次拿其中的K-1块来训练模型,剩下的一块扔进模型中预测;——K折交叉验证
3.(2的极端情况)每次把N条数据中的N-1条作为训练数据,剩下的一条扔进模型中预测——留一法
原理:为了让模型在新数据上的预测效果好,我直接把样本进行切割,其中一部分不放入训练集合,而专门拿来预测(此时这些数据可以视为“新“数据),选预测效果好的模型。这是一种靶向思维,为了让模型达到目的A,我选接近目的A的模型。
而我们在确立了模型选择的方向后,怎么去逼近它呢?
例如怎么找到使结构风险函数最小化的值,怎么找交叉验证的预测效果最好的值呢?肯定不是用枚举法记下假设空间中每个模型对应的函数值,然后进行比较。那我们用什么效率更高的方式去找呢?
有一种情况不需要去找,当我们可以用最优化理论直接求出目标函数(结构风险函数)的精确数值解时;其他情况,我们可以用剪枝,梯度下降等算法进行求解,尽量逼近最优解。
说完了这些,我们再来看看机器学习主要分为哪几类:监督学习,非监督学习,半监督学习,主动学习,批量学习等等。
监督学习的意思是数据是有X和Y(即我们可以把训练数据通过模型得到的预测值和真实值进行比较);
非监督学习是没有Y值的;
半监督学习是有一部分数据有Y,一部分没有Y;
主动学习是当有部分数据没有Y时,我们找到最需要被标记成y的数据推上来,让我们对他们打标签,这是一种平衡的办法,当我们需要打了标签的数据而此时大量数据并没有标签时,一个个标记是十分耗费人力成本的,此时我们选择一种平衡人力和机器学习效果的方式,只选模型最需要的部分数据去打标签。
这本书主要讨论的就是监督学习,而监督学习又可以分为分类、回归和标注问题。
分类问题指Y是有限个离散的数据,如判断邮件是否为垃圾邮件。
回归问题指找到X,Y之间函数映射的问题,如预测波士顿房价的问题,
标注问题指输入X为一段序列,输出为X的序列的标注,常用于自然语言处理,例如对一段英文标记它的名词出现的起止点。
提炼:
假设——数据独立同分布
目的——学习分布规律,预测新数据
方式——确立模型范围和一个策略(评价指标),用算法找到(逼近)评价最好的模型
策略——经验风险最小化——防过拟合改进后——结构经验风险最小化或者交叉验证预测效果最小化
引用文章:
https://www.jiqizhixin.com/articles/2017-11-23-4