目录
1、背景
我们往一张表里插入的行数据是存储在页上的,一张页的大小为16KB,数据量大的时候一张页不可能存储完一张表里的所有数据,所以需要多张页来进行存储,这多张页所在的存储空间就叫表空间,表空间分为系统表空间和独立表空间,接下来就讲一下独立表空间上是如何存储页的。
2、独立表空间
【1】表空间大小
之前讲过页的组成,我们再来看一下页的通用部分File Header(38字节大小)的组成:
| 名称 | 字节大小 | 含义 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 页的校验和 |
| FIL_PAGE_OFFSET | 4 | 页号 |
| FIL_PAGE_PREV | 4 | 上一页 |
| FIL_PAGE_NEXT | 4 | 下一页 |
| FIL_PAGE_LSN | 8 | 页最后被修改时对应的日志序列位置 |
| FIL_PAGE_TYPE | 2 | 页类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 仅在系统表空间的一个页中定义,代表文件执行被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 页属于哪个表空间 |
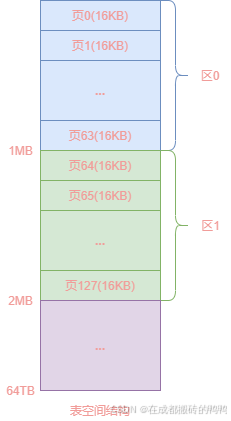
File Header里的页号由4字节组成,也就是32位,所以一个表空间最多能存储232个页,每个页按照16KB的大小来算,一个表空间最多可以存储64TB的大小的数据
【2】区
表空间里每连续64个页组成一个区,一个页按16KB大小来算,一个区的大小就为64*16KB=1MB,如下图表示:
【3】组
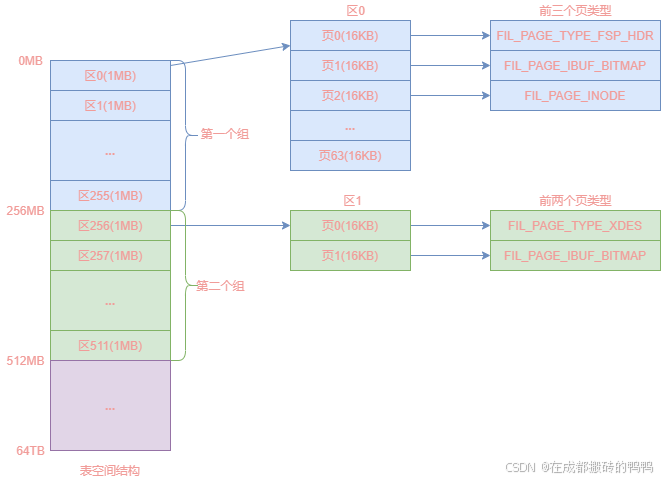
表空间上连续256个区就为一个组,区0到区255就为第一个组,区256到区511就为第二个组,剩下的以此内推,需要注意的是,第一个组的前三个页的类型是固定,其它组的前两个页类型是固定的,在讲这些页之前我们先看一下页的类型有几种:
| 类型 | 含义 |
|---|---|
| FIL_PAGE_UNDO_LOG | Undo日志页 |
| FIL_PAGE_INODE | 段信息节点 |
| FIL_PAGE_IBUF_FREE_LIST | Insert Buffer空闲列表 |
| FIL_PAGE_IBUF_BITMAP | Insert Buffer位图 |
| FIL_PAGE_TYPE_SYS | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 表空间头部信息 |
| FIL_PAGE_TYPE_XDES | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | BLOB页 |
再看组的表结构图,如下图:
【4】段
一个索引有叶子节点和非叶子节点,存放叶子节点所在区的集合就叫叶子段,存放非叶子节点所在区的集合就叫非叶子段,一个索引有两个段。
【5】区的类型
段就是索引中叶子节点和非叶子节点所在区的集合,一个索引两个段,一个区64个页,数据量小的时候用一个区来作为存储单位十分浪费空间,所以就有了碎片区的概念,在数据量小的时候段就以碎片区中的页为单位来分配空间,数据量大的时候就以区为单位来分配存储空间,碎片区不属于任何段,并且碎片区里的页可以存储多个索引的数据,区的类型有如下几种:
| 区类型 | 含义 |
|---|---|
| FREE | 属于表空间,区中的页都没被使用 |
| FREE_FRAG | 属于表空间,有可用页的碎片区 |
| FULL_FRAG | 无可用页的碎片区 |
| FSEG | 属于某个段的区 |
【6】XDES Entry区结构
InnoDB中每一个区都对应一个XDES Entry结构,其组成图如下:
XDES Entry结构字段含义如下:
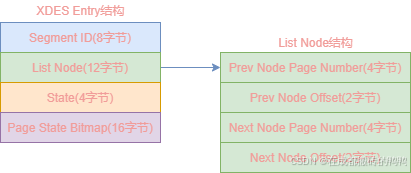
| XDES Entry | 字节大小 | 含义 |
|---|---|---|
| Segment ID | 8 | 段的唯一编号,只有FSEG类型的区此字段才有用 |
| List Node | 12 | 指向上一个和下一个XDES Entry结构 |
| State | 4 | FREE、FREE_FRAG、FULL_FRAG、FSEG四种区类型 |
| Page State Bitmap | 16 | 16字节对应的128比特位,其中每2个比特位对应一个区64个页中的一个页,2个比特位中第一个比特位代表该页是否被使用 |
List Node结构字段含义如下:
| List Node | 字节大小 | 含义 |
|---|---|---|
| Prev Node Page Number | 4 | 上一个XDES Entry结构所在的页 |
| Prev Node Offset | 2 | 上一个XDES Entry结构页内偏移量 |
| Next Node Page Number | 4 | 下一个XDES Entry结构所在的页 |
| Next Node Offset | 2 | 下一个XDES Entry结构页内偏移量 |
【7】XDES Entry链表
在数据量比较小的时候,段是以碎片区中的页为单位来分配存储空间的,插入数据方式如下:
1、查找表空间中状态为FREE_FRAG的区,找到了就取出零碎的页把数据插进去,
2、没找到就申请一个状态为FREE的区,将状态变为FREE_FRAG,再取出零碎的页将数据插入进去,
3、之后再插入数据当没有零碎的页可用时状态就变为FULL_FRAG。
快速查找这3个类型的区通过3个链表来查找,这3个链表是属于表空间独有的,3个链表如下:
| 链表 | 含义 |
|---|---|
| FREE链表 | FREE状态的区对应的XDES Entry结构通过List Node组成的链表 |
| FREE_FRAG链表 | FREE_FRAG状态的区对应的XDES Entry结构通过List Node组成的链表 |
| FULL_FRAG链表 | FULL_FRAG状态的区对应的XDES Entry结构通过List Node组成的链表 |
当一个段中的数据超过32个零碎的页之后,就以区为单位来分配存储空间了,此时每个段都涉及3个链表,注意每个段都有3个链表,3个链表如下:
| 链表 | 含义 |
|---|---|
| FREE链表 | 同一个段中所有页都是空闲的区对应的XDES Entry结构组成一个链表 |
| NOT_FULL链表 | 同一个段中有空闲页的区对应的XDES Entry结构组成一个链表 |
| FULL链表 | 同一个段中没有有空闲页的区对应的XDES Entry结构组成一个链表 |
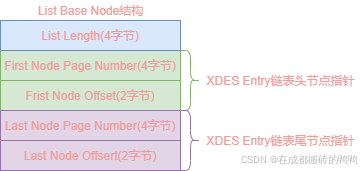
【8】XDES Entry链表基节点
为了快速找到XDES Entry链表的头和尾,InnoDB中设计了链表基节点结构List Base Node,其结构图如下:
【9】INODE Entry段结构
段也有一个对应的结构INODE Entry,其结构如图:

INODE Entry结构字段含义如下:
| INODE Entry | 字节大小 | 含义 |
|---|---|---|
| Segment Id | 8 | 段的唯一id |
| NOT_FULL_N_USED | 4 | NOT_FULL链表中已经使用了的页数 |
| List Base Node For FREE List | 16 | 对应段中的FREE链表 |
| List Base Node For NOT_FULL List | 16 | 对应段中的NOT_FULL链表 |
| List Base Node For FULLList | 16 | 对应段中的FULL链表 |
| Magic Number | 4 | INODE Entry是否被初始化 |
| Fragment Array Entry | 4 | 零碎页页号,总共32个 |
【10】FIL_PAGE_TYPE_FSP_HDR页类型
表空间第一个组中第一个页的类型为FIL_PAGE_TYPE_FSP_HDR,结构如下:
FIL_PAGE_TYPE_FSP_HDR字段解释:
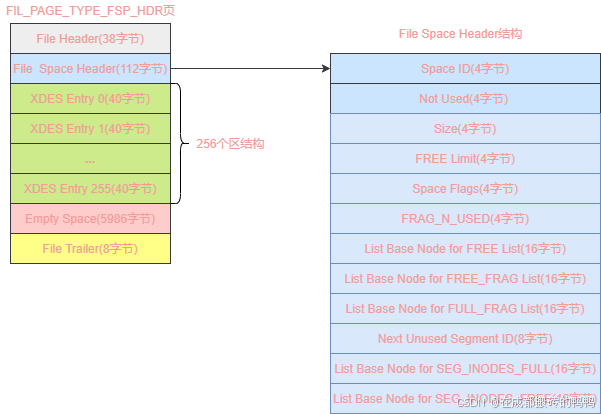
| 字段 | 字节大小 | 含义 |
|---|---|---|
| File Header | 38 | 页的通用信息 |
| FIle Space Header | 112 | 表空间的一些整体属性 |
| XDES Entry | 10240 | 256个区信息 |
| Empty Space | 5986 | 未使用的空间 |
| File Trailer | 8 | 校验页是否完整 |
File Space Header结构字段解释:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| Space ID | 4 | 表空间ID |
| Not Used | 4 | 未使用 |
| Size | 4 | 表空间占有的页数 |
| FREE Limit | 4 | 未被初始化的最小页号,大于等于此页号对应的区的XDES Entry结构都没被加入FREE链表 |
| Space Flags | 4 | 存储占用空间比较小的属性 |
| FRAG_N_USED | 4 | FREE_FRAG链表中已使用的页数量 |
| List Base Node for FREE List | 16 | FREE链表基节点 |
| List Base Node for FREE_FRAG List | 16 | FREE_FRAG链表的基节点 |
| List Base Node for FULL_FRAG List | 16 | FULL_FREG链表的基节点 |
| Next Unused Segment ID | 8 | 表空间中下一个未使用的段ID |
| List Base Node for SEG_INODES_FULL List | 16 | SEG_INODES_FULL链表的基节点 |
| List Base Node for SEG_INODES_FREE List | 16 | SEG_INODES_FREE链表的基节点 |
【11】FIL_PAGE_IBUF_BITMAP页类型
表空间所有组的第二个页的类型为FIL_PAGE_IBUF_BITMAP,用于InnoDB存储引擎中事务日志缓冲区,与插入缓冲有关,后面再讲。
【12】FIL_PAGE_INODE页类型
第一组第三个页类型就为FIL_PAGE_INODE,用于存储段结构INODE Entry,其页结果如图:
FIL_PAGE_INODE页类型字段解释如下:
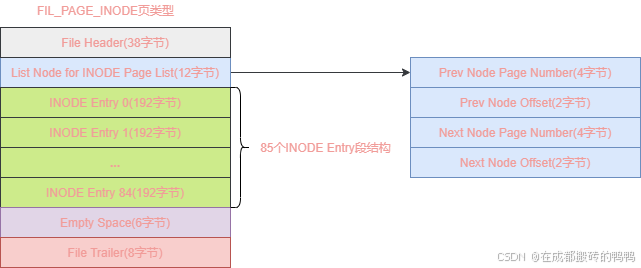
| 字段名 | 字节大小 | 含义 |
|---|---|---|
| File Header | 38 | 页的通用信息 |
| List Node for INODE Page List | 12 | 存储上一个INODE页和下一个INODE页 |
| INODE Entry | 16128 | 段信息,可以存储85个 |
| Empty Space | 6 | 未使用的空间 |
| File Trailer | 8 | 校验页是否完整 |
可以看到一个FIL_PAGE_INODE类型的页最多存储85个INODE Entry段结构,如果超过85个,就需要申请其它FIL_PAGE_INODE类型的页来进行存储了,所有FIL_PAGE_INODE类型的页会组成两个链表,这两个链表存储在FIL_PAGE_TYPE_FSP_HDR类型页的File Space Header结构里,链表如下:
| 链表 | 含义 |
|---|---|
| SEG_INODES_FULL链表 | FIL_PAGE_INODE类型的页中没有空闲空间来存储INODE Entry段结构 |
| SEG_INODES_FREE链表 | FIL_PAGE_INODE类型的页中有空闲空间来存储INODE Entry段结构 |
存储一个INODE Entry结构的过程如下:
1、从SEG_INODES_FULL链表中取出一个页去存储INODE Entry段结构,
2、如果页上的INODE Entry段机构存储满了就放入SEG_INODES_FREE链表,
3、如果SEG_INODES_FULL链表为空,就从表空间所属的FREE_FRAG链表中取出一个零碎页,修改其类型为FIL_PAGE_INODE,再放入SEG_INODES_FULL链表中。
【13】FIL_PAGE_TYPE_XDES页类型
表空间第一个组之外的其它组的第一个页类型为FIL_PAGE_TYPE_XDES,和FIL_PAGE_TYPE_FSP_HDR页类型差不多,相比少了一些其它属性,其结构图如下:

【14】索引关联INODE Entry段结构
一个索引有两个段,它们之间是这样关联起来的,数据页组成的页类型中有两个字段如下:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| PAGE_BTR_SEG_LEAF | 10 | B+树叶子段的头部信息,只在B+树的根页定义 |
| PAGE_BTR_SEG_TOP | 10 | B+树非叶子段的头部信息,只在B+树的根页定义 |
这两个字段各对应一个Segment Header结构如下:
| Segment Header字段 | 字节大小 | 含义 |
|---|---|---|
| SpaceID ofthe INODE Entry | 4 | INODE Entry结构所在的表空间ID |
| Page Number of the INODE Entry | 4 | INODE Entry结构所在页号 |
| Byte Offset of the INODE Ent | 2 | INODE Entry结构在页中偏移量 |
通过Segment Header就能很方便找到索引对应的INODE Entry段结构,并且只需要在B+树的根节点中定义这两字段。
3、总结
本文主要讲解独立表空间的组成部分,涉及到页、区、组还有各种结构等,后续可以再讲解系统表空间的组成,和独立表空间类似。