文章目录
0 前言
机器学习(Machine Learning,之后用ML代替机器学习)中的线性学习器包括两种:
1、线性回归模型。如:
- 普通最小二乘回归(Ordinary Least Squares Regression);
- 岭回归(Ridge Regression);
- Lasso回归(Lasso Regression);
- 弹性网回归(Elastic-Net Regression);
- 多项式回归(Polynomial Regression)
2、线性分类模型。如:
- 感知机(Perceptron);
- Logistic回归(Logistic Regression)。
虽然Logistic回归的名字里有“回归”二字,但实际上是解决分类问题而不是回归问题的一类线性模型。
1 线性回归模型
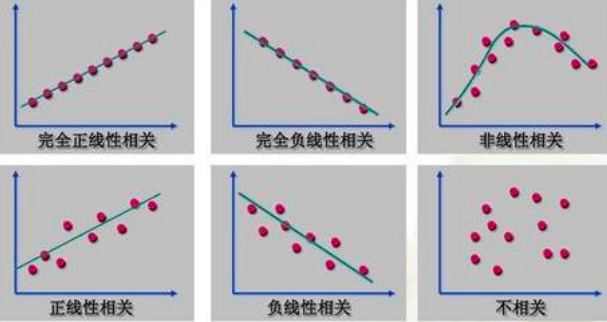
上图是六种相关关系及其图示。
1.1 数据集的形式化描述
ML中的回归分析的目的是:找出相关关系的具体形式——y=f(x)。线性回归模型的具体形式是线性函数f(x)=w·x+b,其中称w、b分别为回归系数与截距。
给定一个包含N个样本的数据集T={(x1,y1),(x2,y2),…,(xN,yN)},其中每个样本包含两部分:
1、特征观测值:x1,x2,…,xN。∀n∈[1,N],都有xn∈Rm。每个样本xn有m维特征向量,所以xn=(xn(1),xn(2),…,xn(m))∈Rm;
2、响应观测值:y1,y2,…,yN。∀n∈[1,N],都有yn∈Rd,其中每个特征向量对应d个观测响应,d=1时是单目标回归,d>1时是多目标回归。回归问题中的响应观测应该是物理上连续变化的量。
1.2 模型的形式化描述
1、多元线性回归模型的标量化形式:
2、多元线性回归模型的向量化形式1:
3、多元线性回归模型的向量化形式2:
4、多元线性回归模型的矩阵化形式:

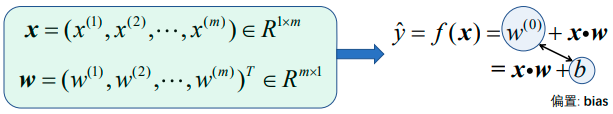
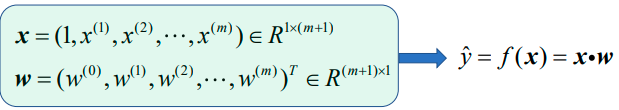
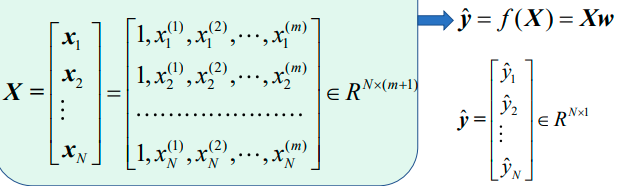
1.3 模型的评价策略
第一步是确定损失函数(loss function)的具体形式,现将损失函数选为误差的平方:
第二步是确定风险函数(risk function)的具体形式,有两种:
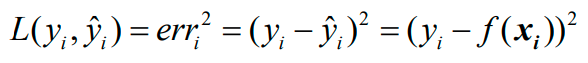
1、经验风险函数;
2、结构风险函数。
注意:损失函数是单个样本点上的损失,而经验风险函数是所有样本点上平均损失。
1.3.1 经验风险函数
现将风险函数选为经验风险,下面的emp是empirical,中文是"以经验为根据的":
下面将前面确定的损失函数:
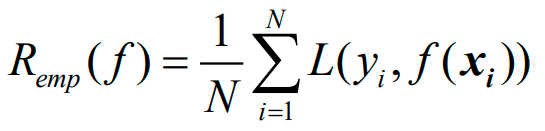
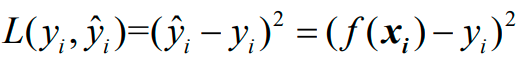
代入上上一张图的公式,得到:
再将前面确定的模型的数学形式:
代入上上一张图的公式,得到:
上图即为经验风险函数的具体形式。接下来需要最小化经验风险函数:
上面最小化的是样本集的平均损失,而普通最小二乘回归最小化的是样本集的总体损失。普通最小二乘回归变换了一下形式,把1/N变成了1/2,即:
普通最小二乘学习器的形式有两种:
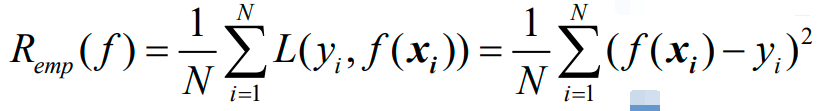
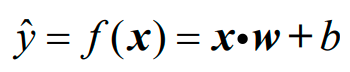
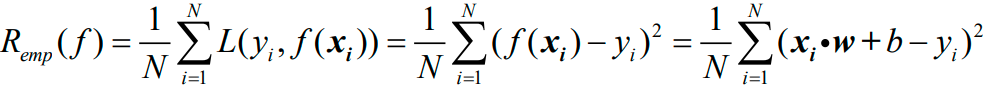
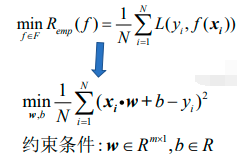
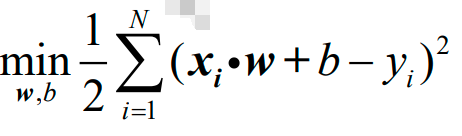
1、向量化描述:
2、矩阵化描述:
上图中最后一个公式的X是:
最小二乘学习器的缺点:

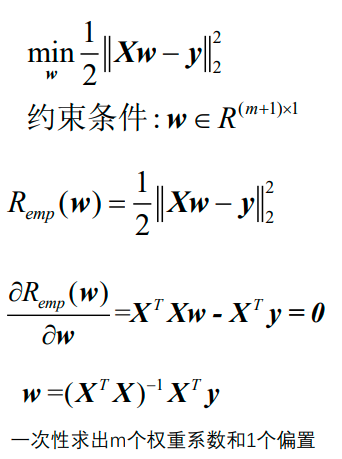
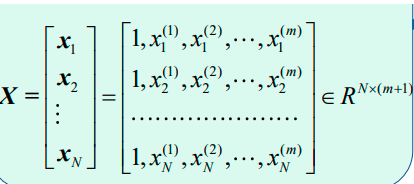
1、模型系数的估计依赖于各个特征分量之间的相互独立性。当特征分量之间有相关性,导致输入矩阵X的各列存在近似线性依赖,矩阵X会趋向于奇异矩阵(即不是满秩矩阵,奇异矩阵是对应的行列式等于0的方阵),这会导致最小二乘估计对观测数据中的随机误差非常敏感,产生很大的方差。
2、样本数量太少容易导致过拟合的情况发生。
3、样本数量太多会导致矩阵的SVD分解计算无法进行。
下面将风险函数选为结构风险函数。
1.3.2 结构风险函数
上图为结构风险函数。将下面的公式:
代入上上一张图的公式得到:
在上图中,有两个参数:
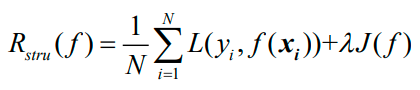

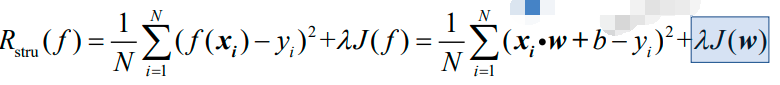
1、λ是平衡因子(trade-off factor),是超参数,表示多大程度上依赖(信任)于给定的数据集;
2、J(w)是正则化项(regularization),也称作对模型复杂度的惩罚项(penalty)。
下面是J(w)的三种具体形式:
上面最后一个公式c的正则化项其实是a和b的凸组合。下图显示了二维参数空间中不同正则化项的轮廓,其中J(w)=1:

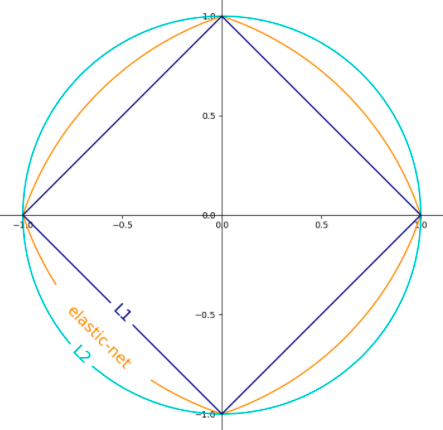
1.3.2.1 岭回归
岭回归的结构风险函数为:
对应于上图的岭回归的结构风险函数的矩阵形式为:
求偏导得:
岭回归的解为:
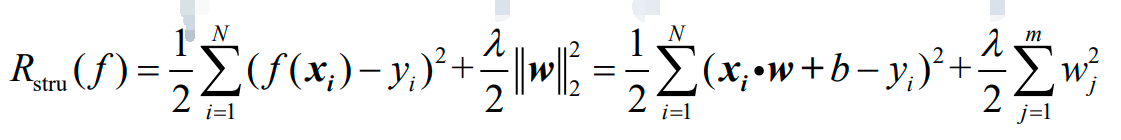
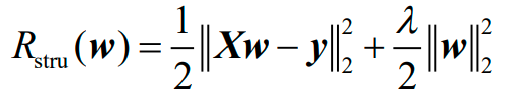
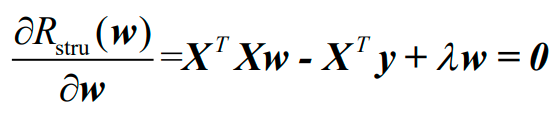
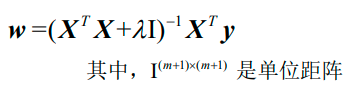
1.3.2.2 Lasso回归
Lasso回归的结构风险函数为:
对应于上图的Lasso回归的结构风险函数的矩阵形式为:
若求偏导:
则会因为有绝对值而不好获得解析解。在SKLearn中的Lasso类使用了坐标下降(coordinate descent)优化方法来训练上述模型。
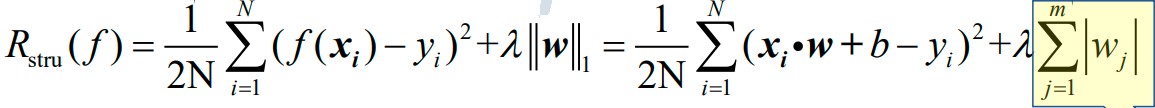
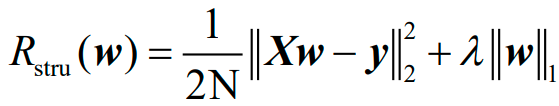
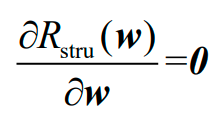
1.3.2.3 弹性网回归
弹性网回归的结构风险函数为:
对应于上图的弹性网回归的结构风险函数的矩阵形式为:
若求偏导:
则会与Lasso回归一样因为有绝对值而不好获得解析解。SKLearn中的ElasticNet类也使用了坐标下降(coordinate descent)优化方法来训练上述模型。
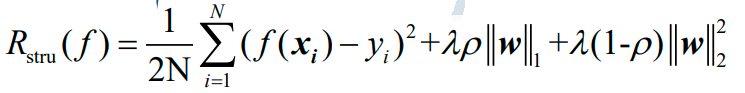
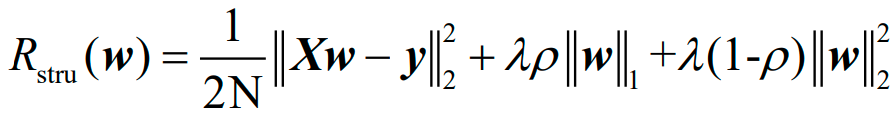
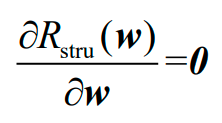
1.4 多项式回归模型
ML中还可以使用在数据集的非线性函数上训练的线性模型,这样保持了线性方法的快速性能,同时允许线性方法适应范围更广的数据。如一个简单的线性回归器可以通过从系数构造多项式特征而扩展到非线性数据的拟合任务中。在标准线性回归模型中,一个用于拟合二维数据的模型如下所示:
若想用抛物面拟合数据,可以用二阶多项式组合各个特征分量,使模型为:
上面的模型仍然是一个线性模型,可创建一组新的特征分量:
用上面的一组新的特征分量重新变换数据,原来的问题就可以写成这样:
由此产生的多项式回归与之前见过的线性模型是一样的,并且可以用线性模型的求解方法解决它,这是因为模型关于未知系数同样是线性组合的形式。对由这些基函数构建的高维空间进行线性拟合,可以使该模型在拟合更大范围的数据时拥有更大的弹性和灵活性。
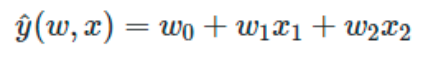
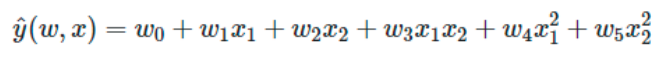
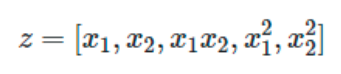
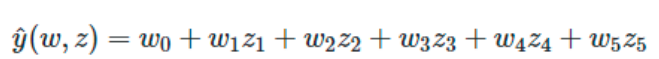
2 线性分类模型
根据两种不同的标准,可将分类问题归类为:
把上面的两种分类标准下的问题进行组合,可以得到四种子问题,如下:

1、线性可分多分类问题;
2、线性可分二分类问题;
3、线性不可分多分类问题;
4、线性不可分二分类问题。
2.1 感知机
感知机解决的是线性可分二分类问题。
2.1.1 问题的形式化描述
C={c1,c2,…,cd}是类别标签的集合,d=2时是二分类问题,即C={c1,c2}={-1,+1}。其中:
1、标签为+1的类称为正类,对应的样本为正样本;
2、标签为-1的类称为负类,对应的样本称为负样本。
需要注意的是:
1、样本的“正”和“负”只是一种称谓或标签,与样本内部特征分量的正负号无关;
2、一个样本即使是负样本,该样本的所有特征分量都可能大于零。
当特征分量的个数等于两个时:
1、如果数据能够被一条直线分开,就是线性可分的;
2、如果找不到一条这样的直线,则是线性不可分的。
如下:
当特征分量的个数等于三个时:
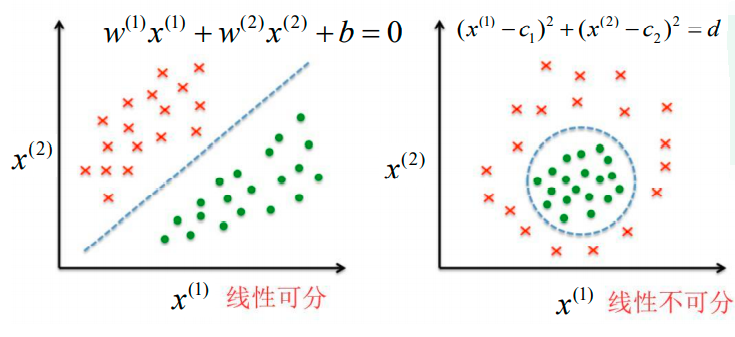
1、如果数据能够被一个平面分开,就是线性可分的;
2、如果找不到一个这样的平面,则是线性不可分的。
如下问题是线性可分的:
当特征分量的个数超过三个时:
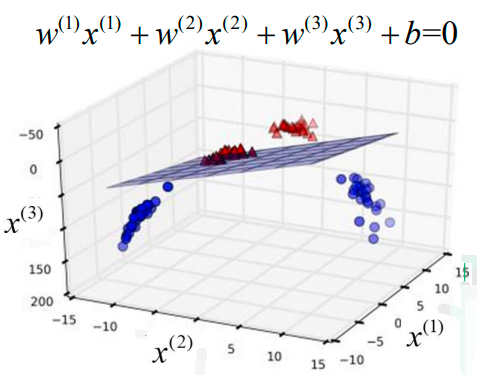
1、如果数据能够被一个超平面(hyperplane)分开,就是线性可分的;
2、如果找不到一个这样的超平面,则是线性不可分的。
线性可分二分类问题的定义:

2.1.2 模型的形式化描述
上图依次是符号函数、感知机模型的形式和模型预测输出的类别标签集合。

感知机是一种线性分类模型,属于判别模型。感知机模型的假设空间是定义在特征空间上的所有线性函数构成的集合,即:
每一对具体的参数组合w和b就唯一地决定了一个模型,所以在给定数据集上训练感知机的过程就是不断调整参数w和b,从而寻找最优假设的过程。
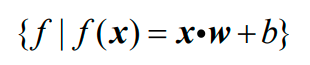
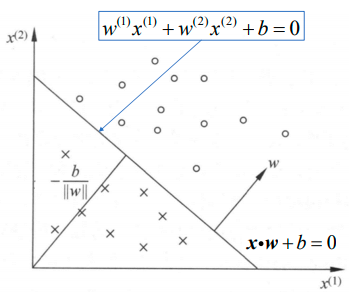
下面是特征分量的个数等于2个的例子:
感知机的几何解释:线性方程对应于m维特征空间中的一个超平面,其中w是超平面的法向量,b是超平面的截距。超平面将特征空间划分为两个部分,位于两部分的点分别被分为正、负两类。
2.1.3 模型的评价策略
感知机的模型为:
在单个样本上的损失函数有以下几种:
因此上述四种损失函数在感知机中无法使用。但是可以注意到错误分类点到超平面的距离始终不为零,所以可以将误分类点到超平面的距离设为其损失值,同时正确分类点到超平面的距离也是不为零的,但分类正确的样本点是不应该有损失的。那如何构造损失函数才能够正确区分正确分类点与错误分类点呢?
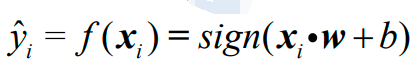
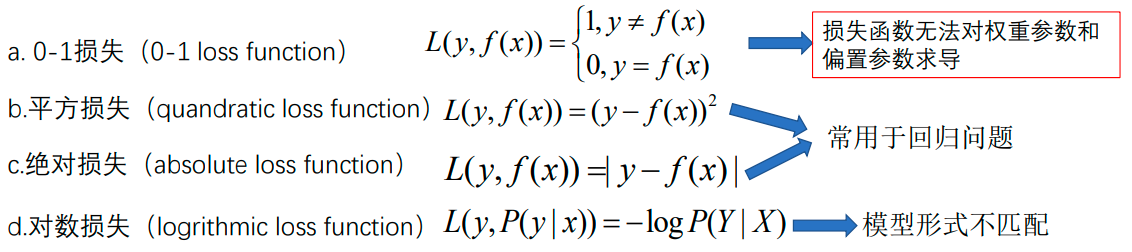
首先将数据集分为Q和M:
然后:
得到感知机的经验风险函数为:
其中,M是所有错误分类的样本点的集合:
如果把正确分类点集合Q也写进去:
就变成如下的形式:
上式中:


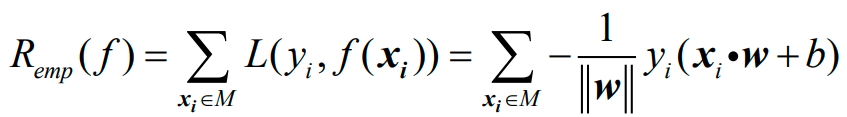
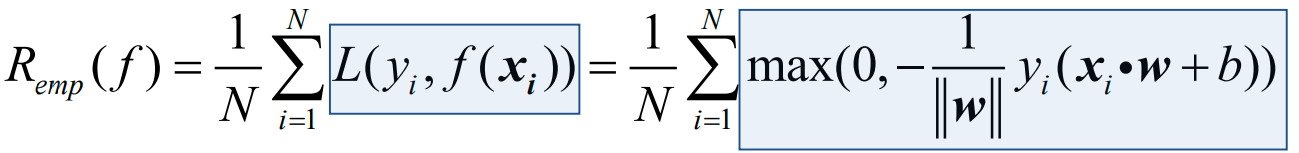
(1) 经验风险函数是非负的,而且如果没有误分类点,其值为0;
(2) 误分类点越少,或误分类点离超平面越近,经验风险的取值就越小;
(3) 对于一个特定样本点的损失函数:在误分类时是参数w和b的线性函数;在正确分类时等于0。因此Remp是关于参数w和b的连续可导函数。
因此,感知机的经验风险函数最终变为:
同时地,感知机的结构风险函数为:
可以看出,结构风险函数只是增加了正则化项J(w),而J(w)有三种类型:
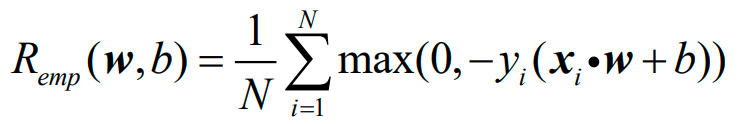
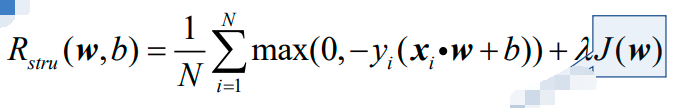
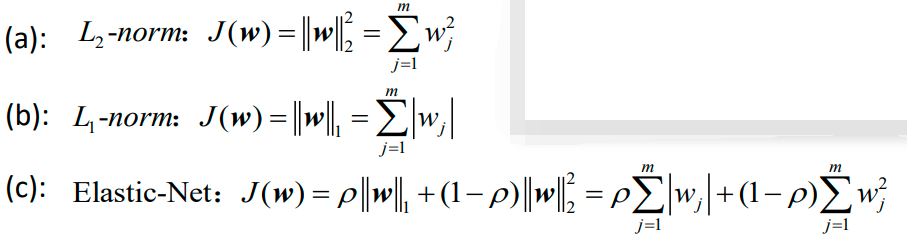
2.1.4 模型的优化方法
最优化问题为:
只关注错误分类点的话可以化为:
其中,M是所有错误分类的样本点集合:
感知机的学习算法是错误分类驱动的。
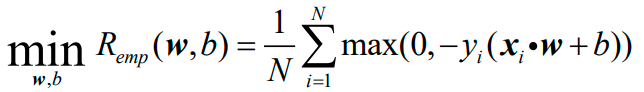
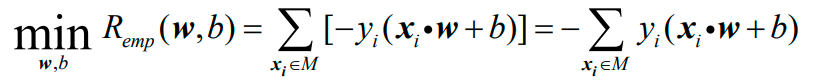
首先任意选取一组初始参数w0与b0,然后用梯度下降法不断地极小化目标函数:
在极小化过程中,可以一次使用M中所有误分类点来调节权重w和偏置b。假设误分类点的集合M是固定的,那么经验风险函数Remp(w,b)的梯度计算方式如下:
然后沿着梯度的反方向调整:
上式中的超参数η是步长,又称为学习率(learning rate)。在实践中,经常采用随机梯度下降法(SGD)。极小化过程是一次在M中随机选取一个误分类样本点使其梯度下降。即:
然后沿着梯度的反方向调整:
整个优化是一个循环过程,通过不断迭代可以使得经验风险函数的取值不断减小,直到为零,此时说明所有样本都被正确分类了!
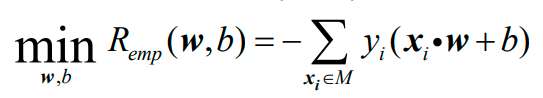
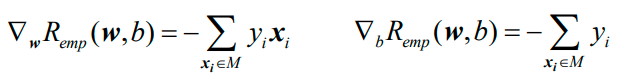
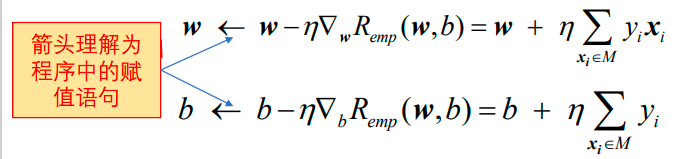
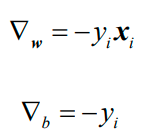
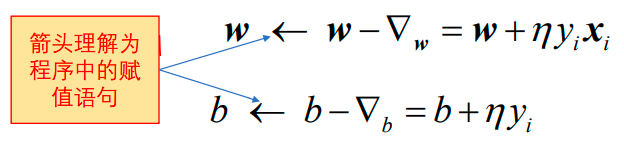
下面给出感知机学习算法的输入输出及详细步骤:
使用SGD(随机梯度下降法)的感知机模型的通俗解释是这样的:当一个实例点被误分类,即位于超平面的错误一侧时,则调整w、b的值,使超平面向该误分类点的一侧移动,以减少该误分类点与超平面间的距离,直至超平面越过该误分类点使其被正确分类。

2.2 Logistic回归
2.2.1 模型的形式化描述
Logistic回归从概率的角度看待二分类问题。已知样本特征向量xi=(xi(1),xi(2),…,xi(m))∈Rm,根据后验概率来判断类别:
只要知道了正类的后验概率p,就可以进行二分类了,因为负类的后验概率q=1-p,接下来只需要比较p与q的大小关系便可以知道预测的类别。
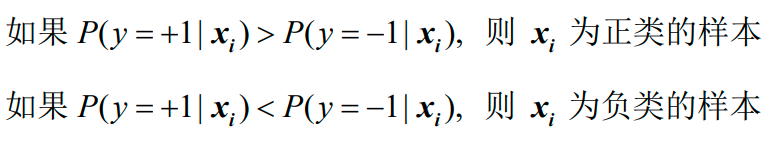
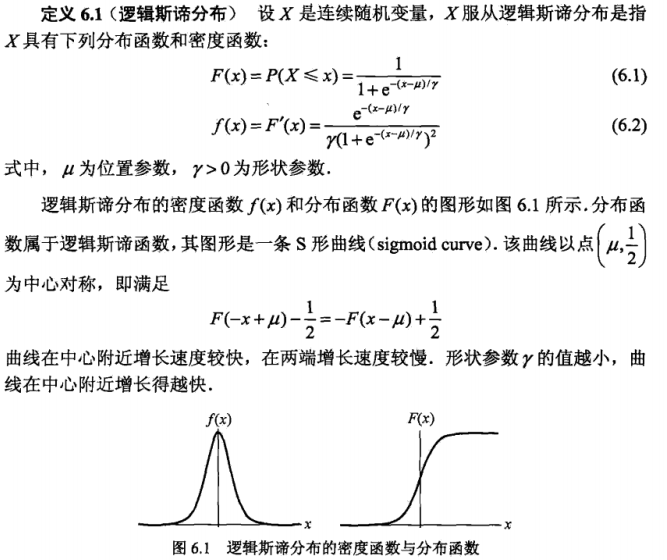
下面是Logistic分布及其概念:
把线性组合z:
输入到参数μ与γ分别为0和1的Logistic分布函数F(z)中:
将z转换成后验概率值:
再结合指数函数和Logistic分布的性质,可得:
若把偏置b=w0也并到权重向量里边去,则样本特征向量x与权重向量w变为:
最后得到的Logistic模型如下所示:
这样的话,只要给一个样本特征向量x,就可以立即计算出其属于正类和属于负类的概率p、q,再比较大小便可以得到预测的类别。
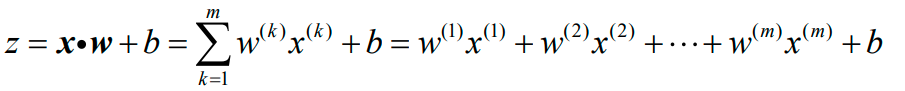
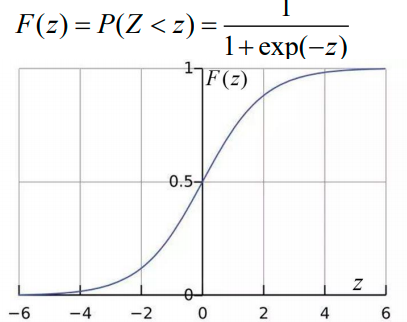
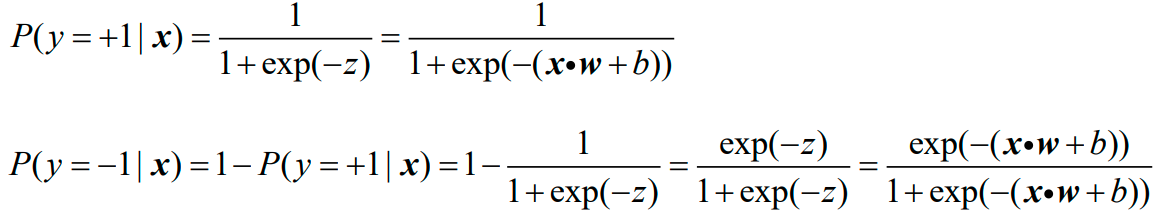

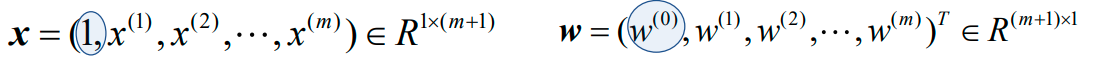
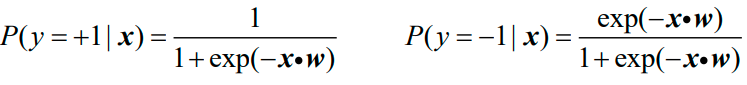
2.2.2 模型的评价策略
Logistic回归在单个样本xi上的损失函数选择的是对数损失(logarithmic loss function):
在对数损失的情况下,不管样本是否分类正确,都会产生损失,只是损失大小不一样。预测出的概率越接近1,损失越接近0。所以,这里也要分两种情况进行计算:正样本的损失和负样本的损失:
为了将两种情况下的损失函数统一,Logistic模型在单个样本点上的预测损失函数为:
这样的话,任意给一个样本,不管预测为正类还是负类,也不管预测的对还是错,计算损失的方式是一样的了。如果把偏置b单列出来,则损失函数为:
因此,Logistic回归的经验风险函数为:
Logistic回归的结构风险函数为:
其中J(w)可以是:
之后问题就变成了关于风险函数的最优化问题,Logistic回归通常采用的方法是梯度下降法及拟牛顿法,这些内容省略。
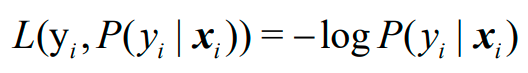

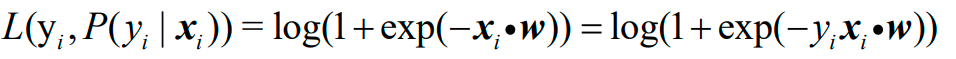
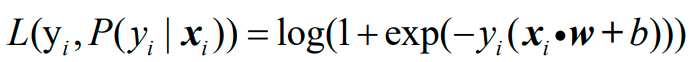
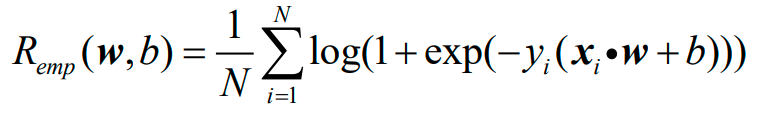
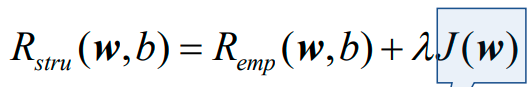
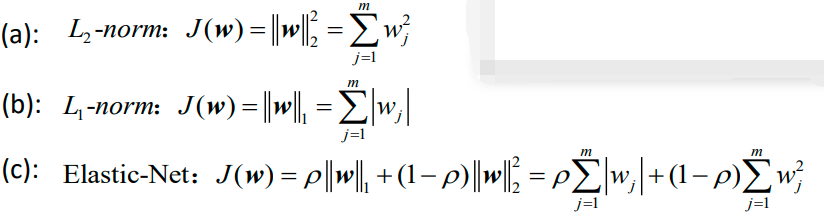
END