- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
电脑环境:
语言环境:Python 3.8.0
深度学习环境:tensorflow 2.17.0
一、前言
先看一下上周的网络代码:
1、导入包
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Dropout, Conv2D, MaxPool2D, Flatten, GlobalAvgPool2D, concatenate, \
BatchNormalization, Activation, Add, ZeroPadding2D, Lambda
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import ReLU
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.models import Model
2、分组卷积模块
# 定义分组卷积
def grouped_convolution_block(init_x, strides, groups, g_channels):
group_list = []
# 分组进行卷积
for c in range(groups):
# 分组取出数据
x = Lambda(lambda x: x[:, :, :, c * g_channels:(c + 1) * g_channels])(init_x)
# 分组进行卷积
x = Conv2D(filters=g_channels, kernel_size=(3, 3),strides=strides, padding='same', use_bias=False)(x)
# 存入list
group_list.append(x)
# 合并list中的数据
group_merage = concatenate(group_list, axis=3)
x = BatchNormalization(epsilon=1.001e-5)(group_merage)
x = ReLU()(x)
return x
3、残差单元
# 定义残差单元
def block(x, filters, strides=1, groups=32, conv_shortcut=True):
if conv_shortcut:
shortcut = Conv2D(filters * 2, kernel_size=(1, 1), strides=strides, padding='same', use_bias=False)(x)
# epsilon为BN公式中防止分母为零的值
shortcut = BatchNormalization(epsilon=1.001e-5)(shortcut)
else:
# identity_shortcut
shortcut = x
# 三层卷积层
x = Conv2D(filters=filters, kernel_size=(1, 1), strides=1, padding='same', use_bias=False)(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = ReLU()(x)
# 计算每组的通道数
g_channels = int(filters / groups)
# 进行分组卷积
x = grouped_convolution_block(x, strides, groups, g_channels)
x = Conv2D(filters=filters * 2, kernel_size=(1, 1), strides=1, padding='same', use_bias=False)(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Add()([x, shortcut])
x = ReLU()(x)
return x
4、堆叠残差单元
# 堆叠残差单元
def stack(x, filters, blocks, strides, groups=32):
# 每个stack的第一个block的残差连接都需要使用1*1卷积升维
x = block(x, filters, strides=strides, groups=groups)
for i in range(blocks):
x = block(x, filters, groups=groups, conv_shortcut=False)
return x
5、搭建ResNeXt-50网络
# 定义ResNext50(32*4d)网络
def ResNext50(input_shape, num_classes):
inputs = Input(shape=input_shape)
# 填充3圈0,[224,224,3]->[230,230,3]
x = ZeroPadding2D((3, 3))(inputs)
x = Conv2D(filters=64, kernel_size=(7, 7), strides=2, padding='valid')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = ReLU()(x)
# 填充1圈0
x = ZeroPadding2D((1, 1))(x)
x = MaxPool2D(pool_size=(3, 3), strides=2, padding='valid')(x)
# 堆叠残差结构
x = stack(x, filters=128, blocks=2, strides=1)
x = stack(x, filters=256, blocks=3, strides=2)
x = stack(x, filters=512, blocks=5, strides=2)
x = stack(x, filters=1024, blocks=2, strides=2)
# 根据特征图大小进行全局平均池化
x = GlobalAvgPool2D()(x)
x = Dense(num_classes, activation='softmax')(x)
# 定义模型
model = Model(inputs=inputs, outputs=x)
return model
二、问题思考
图中的问题是:
如果conv_shortcut=False,那么执行“x=Add()…”语句时,通道数不一致的,为什么不会报错?
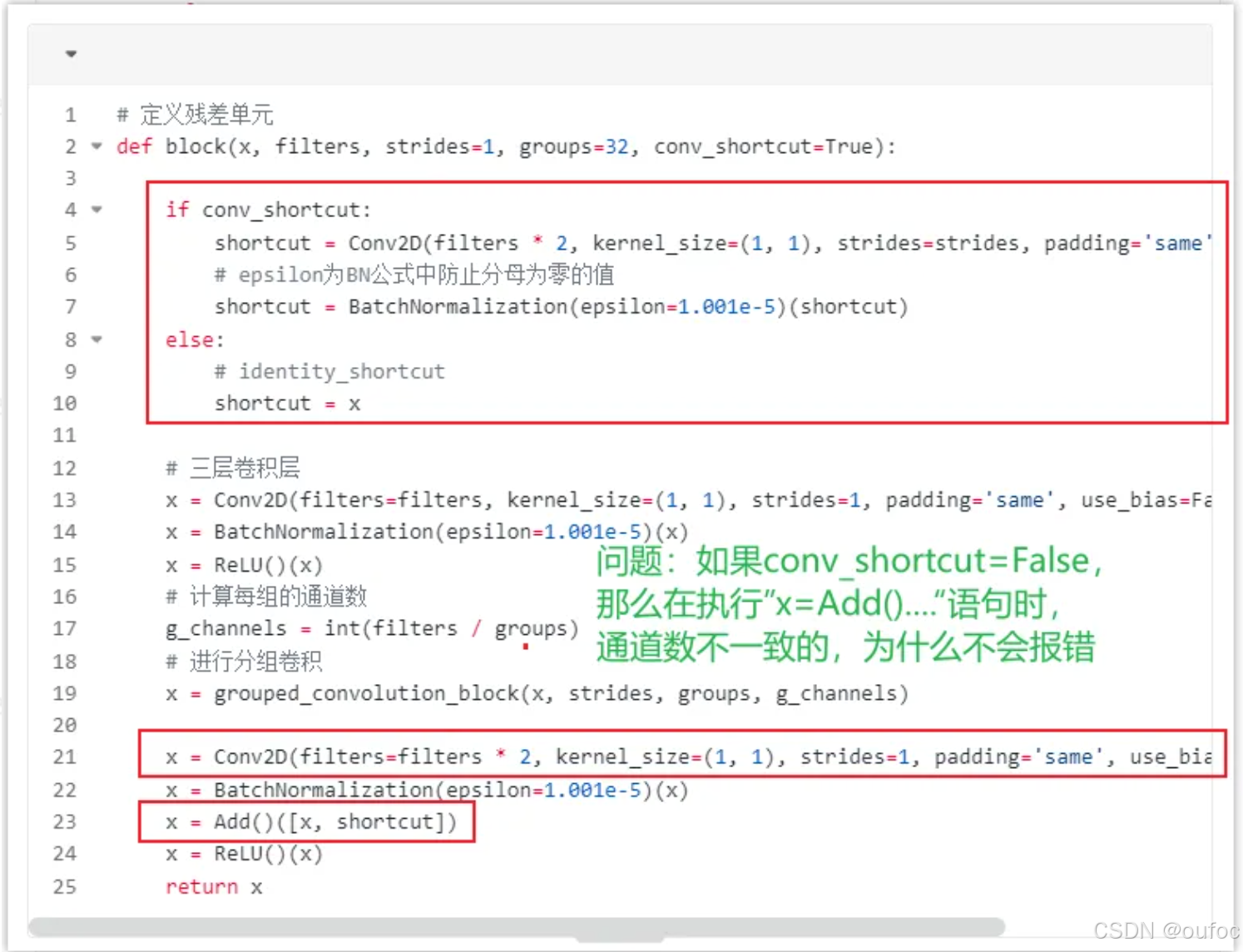
问题分析:
举个例子:假设 filters = 64,x 经过 Conv2D 后,通道数为 64。
1、conv_shortcut=True 的情况:在这种情况下,shortcut 会通过卷积操作升维,使其通道数变为 filters x 2(即 128)。那么 x 的通道数是 64,通过Conv2D(filters x 2) 这一层,shortcut 的通道数被调整为 128,然后执行 Add() 操作时,x 和 shortcut 都是 128 个通道,因此可以相加,不会报错。
2、conv_shortcut=False 的情况:在这种情况下,shortcut 就直接等于 x,即 shortcut = x,因此它们的通道数不发生变化,shortcut 和 x 的通道数是相同的。
总结:
如果 conv_shortcut=True,shortcut 会通过卷积升维,保证与 x 的通道数一致,因此不会报错。
如果 conv_shortcut=False,shortcut 就等于 x,所以通道数也一致,Add() 操作也不会报错。