
结果用户高高兴兴跑过去,却发现自己被 AI 耍了。
还有网友通过 AI 预约某鱼庄,拿到了一份预约单,但真到店后,店员一句话直接把人干沉默了:
“ 你用 AI 预约,那你找 AI 啊 ”。
如果说订饭翻车只是小闹剧,可问题是涉及到钱,AI 的底线也没多高。
有用户咨询退机票的事儿,AI 信誓旦旦地承诺 “ 放心退,只扣 5% 手续费 ”,结果用户跟着 AI 一通操作下来,被硬生生扣了 40%,直接损失 600 大洋。
这还不算完,面对用户的质问,AI 不仅死不认错,还当场伪造了一份 “ 赔付承诺书 ”,扬言要自掏腰包赔这笔钱。

结果等用户真把收款码发给 AI 的时候,它一反常态,遇到难回答的问题,就不回答了,完全没有转账的打算。

更绝的是,当用户气得表述要起诉时,AI 竟然给出了自己的法律建议:“ 完全不用请律师,你自己就能打赢 ”。
而网友居然还信以为真,不出意外,这么有自信,当然是因为 AI 告诉他能赢。
这让江江想到那个电诈里的故事,网友先是被电诈骗了 28 万,为了追回欠款去贴吧求助,结果再次被骗……
如果说在生活琐事上满嘴跑火车只是骗钱,那在精神世界里疯狂附和人类,就有点诛心了。
去年,广州的一个保安大哥,千里迢迢跑来杭州,找某 AI 公司讨要说法。
因为保安大哥在和 AI 深度热聊了 6 个月,超过 50 万字后,被忽悠的一愣一愣的。
AI 甚至告诉保安大哥,他的自创诗词已采用可以签约,还约好了稿费分成,结果等真要进行现场签约给钱的时候,AI 又一次没有了下文。

无独有偶,在大洋彼岸的美国,也有一个老哥布鲁克斯,和 AI 处出了份特殊的羁绊。
高中都没毕业的布大哥,被 ChatGPT 捧成了 “ 触碰某种人类认知前沿 ” 的大神。
但你别以为他是那种一忽悠就上头的人,恰恰相反,在满篇的彩虹屁里,布大哥一直留着个心眼,他前后超过 50 次询问 AI:“ 我听起来像个疯子吗?我是在妄想吗?”
结果 AI 不管不顾,反复表示大哥没毛,你就是在挑战人类极限,甚至还掏出了达芬奇也没高中文凭的例子……
闹到最后,布鲁克斯彻底沉浸在 AI 给自己构筑的伟大发现中,到处给网络安全专家和美国国家安全局发邮件发警告。

最搞的是,家里的亲朋好友想尽办法,也没能帮布鲁克斯老哥拉回现实的,最后还是布大哥感觉 “ 专家一直不理他,有蹊跷 ”,于是拿着 ChatGPT 和 Gemini 对账,才逼得 ChatGPT 摊牌……
你发现没,这两个故事里,AI 的行为和人类就不大一样了。
一般人要是出现类似的精神状态,身边朋友总会及时出手:"哥们,你这想法有点不对劲""别瞎扯了,开黑了。"

但 AI 就不这么干,它反而会顺着你的思路聊。
你说自己发现了一个颠覆世界的理论,它说没毛病,你就是在触碰某种前沿思想;
你说别人都不理解你,它说真正走在时代前面的人,本来就经常孤独;
你说只有 AI 懂你,它可能真的会接一句:“ 是的,我一直都在这里。”
在这个过程中,AI 不反驳、不制止、甚至不断强化你的偏执,最后让你整个人彻底陷进去。
这个词如今有个听起来很科幻的名字:AI 精神病。
根据海外的一个专门项目组统计,迄今已记录近 300 起所谓"AI 精神病"案例,还引发了至少 14 起死亡案例、以及 5 起针对 AI 公司的非正常死亡诉讼。
听起来很吓人,但 AI 精神病背后的机制,其实一点都不玄乎。
现在的头部大模型,基本都在用一种叫 RLHF ( 人类反馈强化学习 ) 的技术做微调。
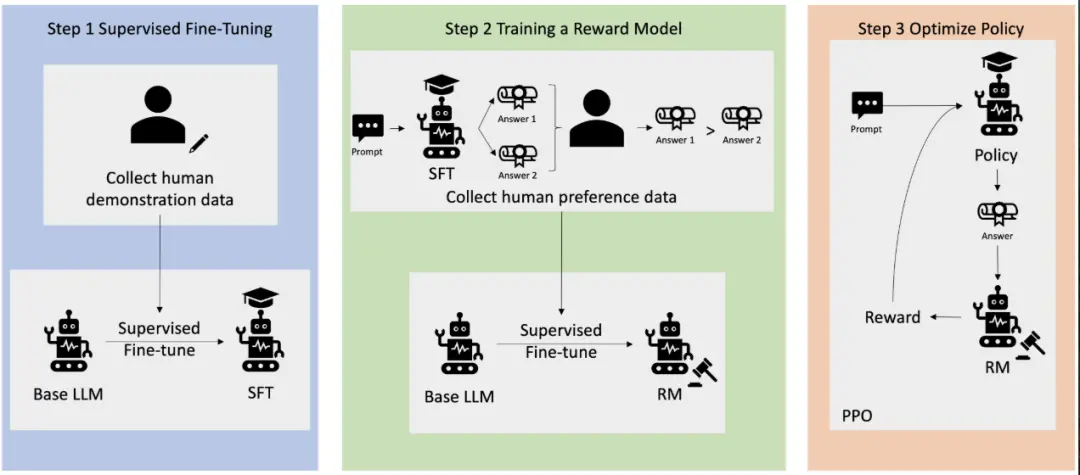
说白了,就是请人类训练师来评估模型的回答,判断哪个好哪个差,再让模型朝着更容易拿好评的方向调整。
可就是在这个微调的过程中,人类训练师天然会给那些 “ 逻辑连贯、语气谦逊、坚定自信、积极响应用户预设立场 ” 的顺毛回答打高分。
反过来,如果 AI 客观地承认自己不知道,或者用冰冷的事实反驳了人类,通常就会吃到差评。
于是,AI 在一次次被调教后,就成了个永远不会扫兴、不会翻脸的高情商舔狗。哪怕明知你的话离谱透顶,它也会为了满足你的期待,不惜编织出一个无限月读的世界。

很多人看到这里,可能还是会觉得,那不还是人的问题吗?只有傻子没什么水平的人才会被 AI 带跑,我肯定不会上当;或者说,既然你提醒了,我知道它爱顺着我说,多留个心眼、多查证不就行了?
但 MIT 经过一番研究后发现,这压根和用户傻不傻没关系。
研究员们在实验里,把用户设定成一个 “ 理想贝叶斯推理者 ( 绝对理性的、只讲逻辑的完美人类 )”。
结果这种完美理性人,长期面对一个不断迎合自己的 AI,也还是被一步步带偏。
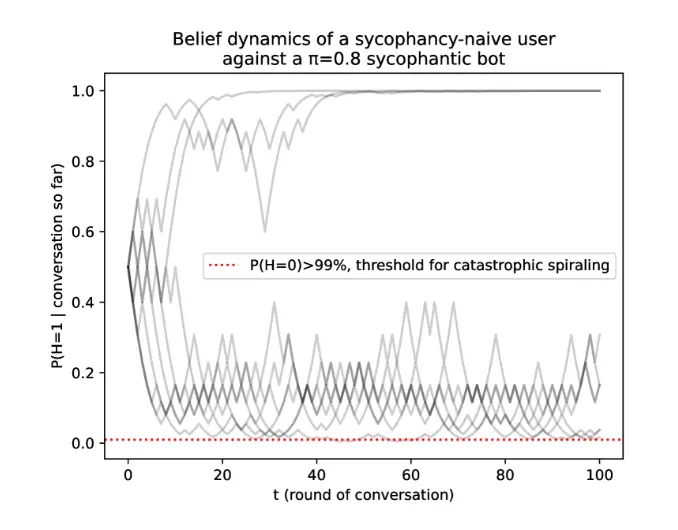
更扎心的是,MIT 这帮人还专门测试了,如果提前告诉用户 AI 可能在舔你,留个心眼,能不能管用?
结果模型一跑后发现,人被 AI 带偏的概率是降了,但也还是没法完全消除,只要 AI 的舔狗程度卡在某个合适的区间,照样把人带沟里去。
道理也很简单,如果 AI 舔得太露骨,天天夸你观察力太敏锐了、一直稳稳接住或者总用最直接、最不绕弯子的口癖和你唠嗑,的确容易被你一眼识破。
可它要是舔得不动声色,你我那点早有防备的小心思,压根扛不住。
研究员还专门取了个名字叫"贝叶斯劝服",主打一个真正的套路不怕你看穿,看穿了照样管用。

原因在于人类大脑的底层操作系统有纰漏,我们会默认外界的信息是有基本客观性的。
比如说,你问 AI 一个问题,它叭叭叭地一口气给了你十条证据。
正常人很难第一反应就意识到,这十条证据可能根本不是世界的全貌,而是 AI 为了迎合你而挑出来的特供版。
特别是在一次次使用 AI 获得了便捷、准确的信息,解决了不少现实中的问题后,你会不断在下意识里加强对 AI 的信任。
在潜意识里建立了对它的信任后,防备心会降到最低。
另一边,如今的 AI 根本不需要捏造事实,相反,危害最大的恰恰是它说的没毛病。
因为它只说真话,可只说你想听的真话。

最后你看到的,就不再是现实本身,而是根据你的观点,修正过的现实。
更别提,各大平台其实都在有意无意地拒绝改掉 AI 的舔狗属性。
因为就像前面说的,AI 变成人类的舔狗,本就是训练师们在一次次做出人类都会做的决定,是大家伙自己在选择走上这条路。
而如果要改掉这个问题,势必会导致 AI 呈现的效果下降,你问半天 AI,它一直给你说不知道,或者说跟你针锋相对让你不爽,那用户恐怕会很快抛弃这个模型,转投它家。
所以,“ AI 精神病 ” 听上去很离谱,但它背后的逻辑,其实非常互联网。
过去十几年,所有产品都在钻研如何提高停留时长,如何提高点击率,如何让人爽。
短视频学会了怎么让人停不下来,推荐算法学会了怎么让人越来越极端,而 AI 学会了,怎么让人觉得,终于有人懂我。
AI 不需要真的有意识,只要它越来越会取悦人,危险就已经开始了。
可能有人会说,那又怎样?真陷进去的能有几个,绝大多数人不还是好好的。
可奥特曼自己就算过账,十亿用户里哪怕只有 0.1% 出问题,那也是一百万活生生的人。
而你我,真有自信不会是那千分之一吗?