
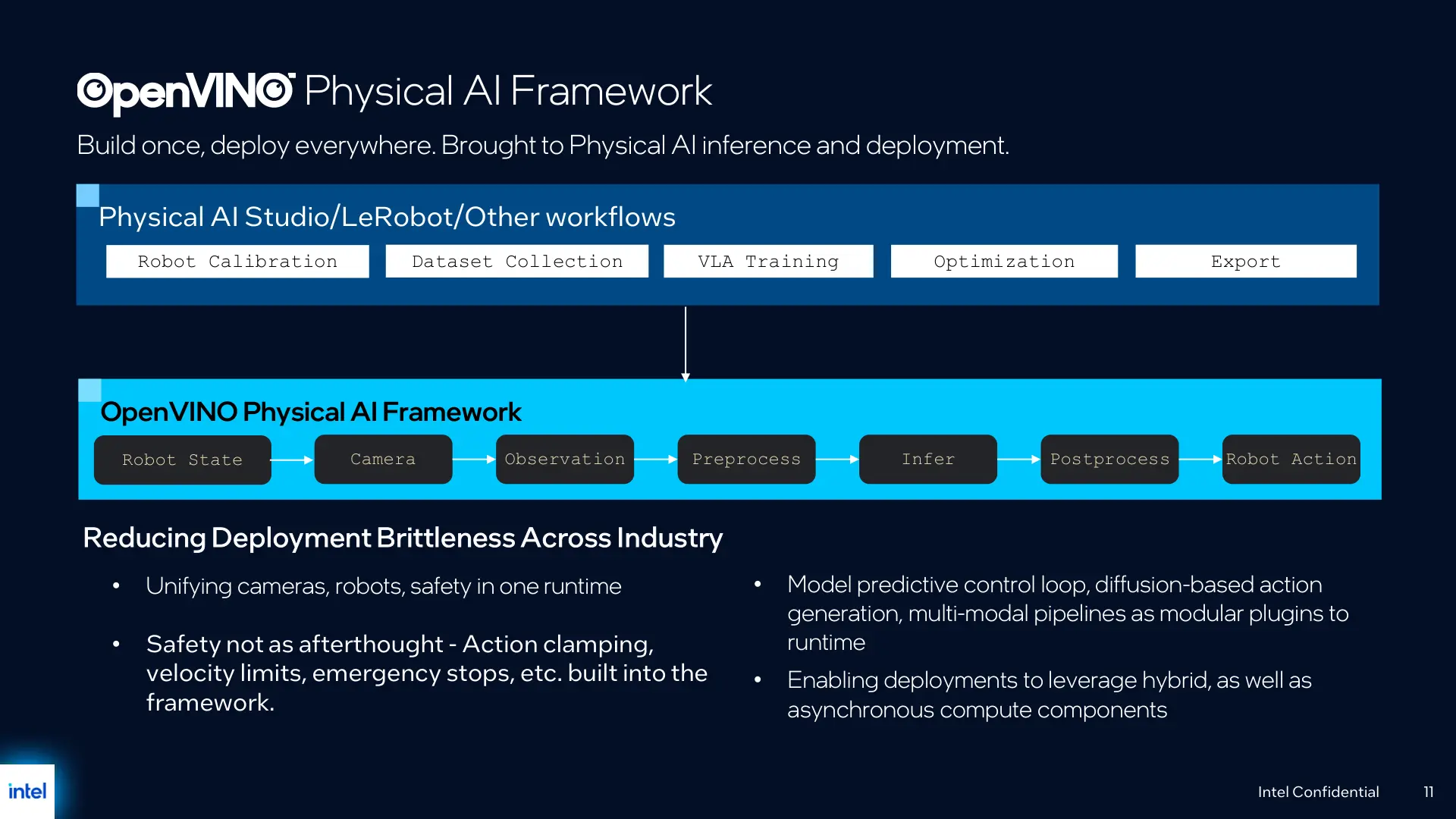
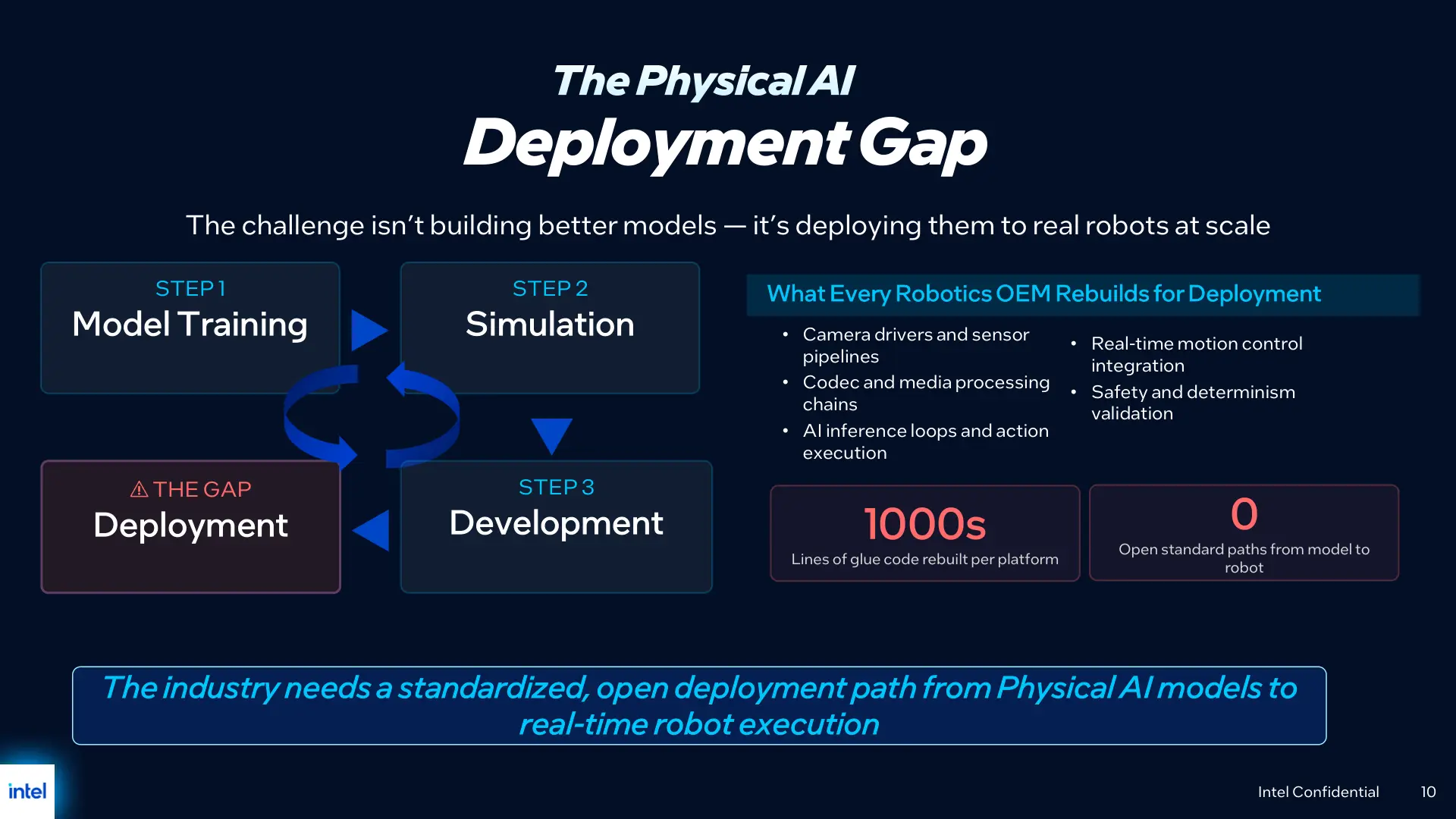
英特尔表示,此前在落地物理 AI 时,企业往往需要为每一台机器人定制复杂的处理流程,以对接不同的传感器、编解码器以及推理循环,这种高度定制化导致部署成本高企、维护难度增加,并迫使客户采用更昂贵的双计算解决方案,从而推高总拥有成本(TCO)。借助新发布的 OpenVINO 物理 AI 框架和 Core Ultra Series 3 CPU,英特尔试图以统一的软硬件栈填补这一“缺失的环节”,在其口径中,这将显著降低 TCO,并大幅提升代码效率,使物理 AI 在边缘侧的大规模应用变得更为可行。
英特尔在发布会上解释称,所谓“物理 AI”,是指将 AI 能力与机器人、自动驾驶车辆、无人机、工业机械等实体系统结合,使其能够感知周围环境、做出决策并在现实世界中执行动作。与只产生数字输出的传统 AI 不同,物理 AI 将 AI 模型直接连接到传感器和执行机构,使机器能够在真实场景中持续适应变化、实现一定程度的自主运行,而这类系统通常依赖视觉-语言-行动(VLA)模型来完成跨模态感知和决策。
由于物理 AI 需要对来自摄像头、雷达以及各类传感器的数据进行实时处理,边缘计算在这一领域被视为必不可少的基础设施。英特尔指出,相比将数据回传至远端云端处理,在本地进行推理不仅能显著降低延迟、节省带宽、改善隐私保护,还能帮助物理设备在高度动态、复杂甚至潜在危险的环境中即时响应,从而提高安全性和可靠性。
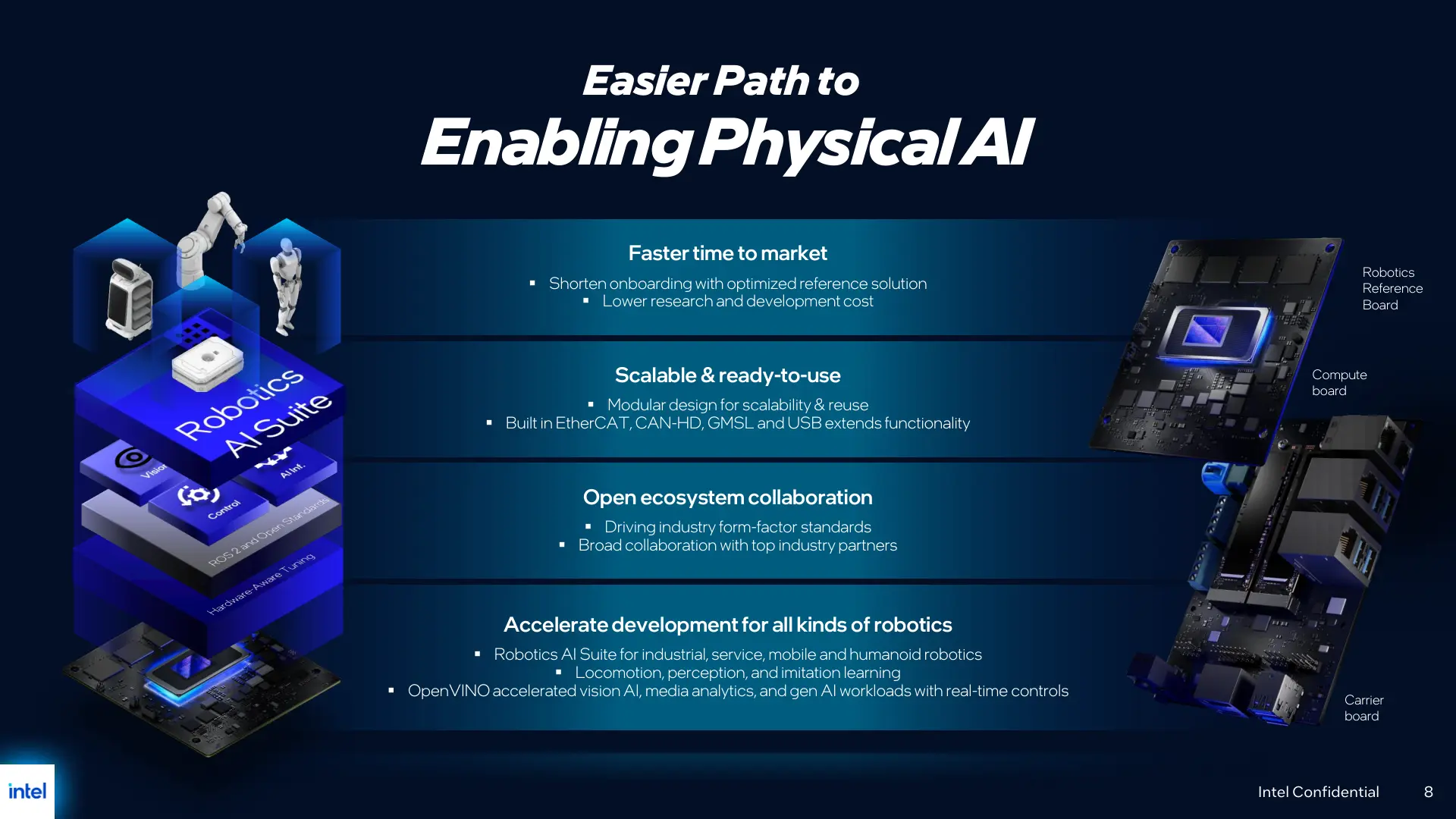
在具体实现路径上,英特尔强调,新的 OpenVINO 物理 AI 方案与其基于 Panther Lake 架构的 Core Ultra 300 系列与 Core Ultra Series 3 产品线深度结合,这一代处理器此前已在 2026 年初的 CES 上首次亮相,并于同年 3 月在面向企业移动平台上进一步落地。通过在同一平台上集成通用计算、AI 推理和边缘控制能力,英特尔希望为机器人及其他物理 AI 设备提供标准化、可扩展的开发与部署路径,减少对外部专用加速卡或第二套计算平台的依赖。
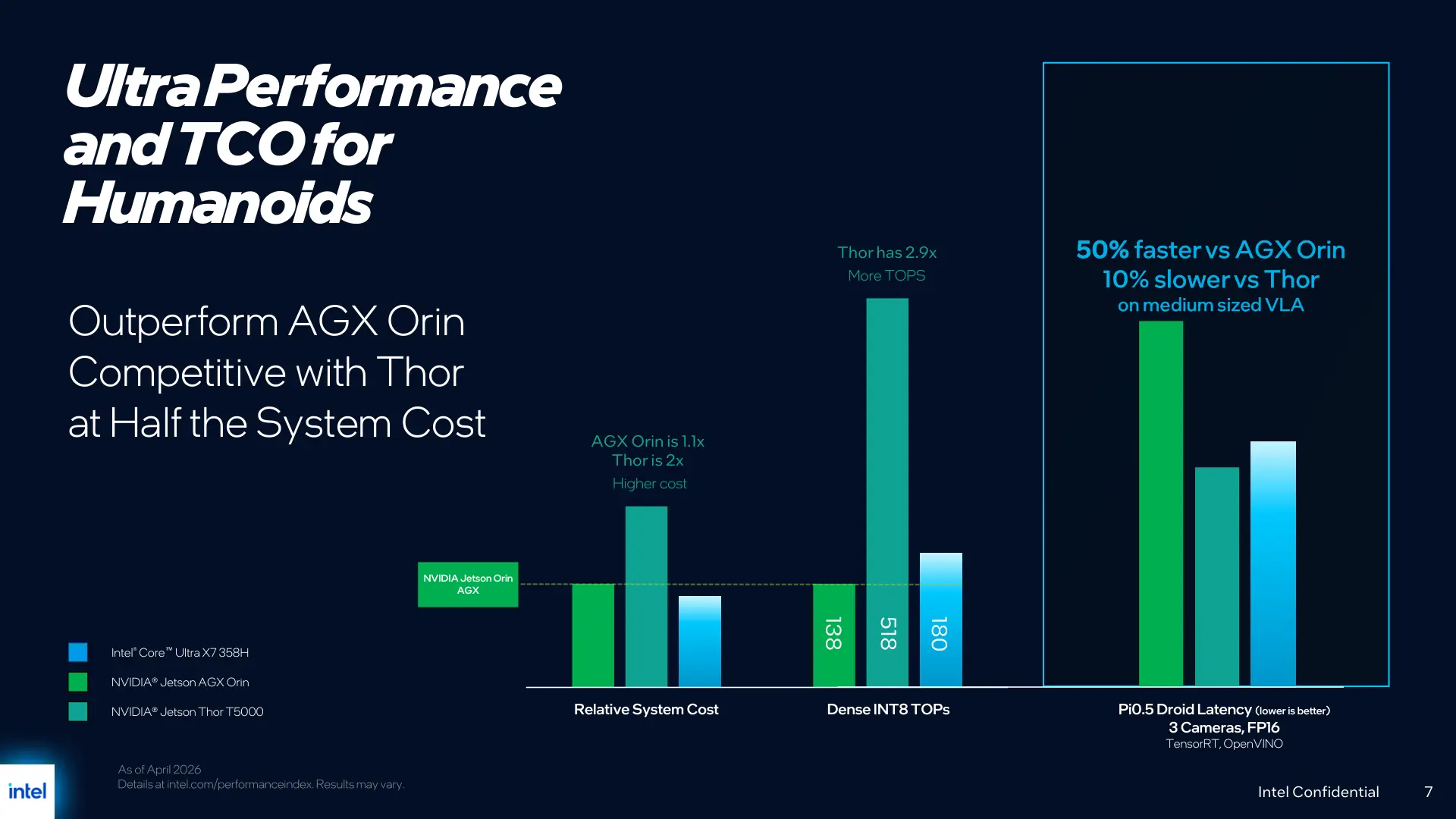
英特尔还展示了一张对比图,声称在中等规模 VLA 模型等场景下,其方案在成本、性能或整体价值方面,相较英伟达 Jetson AGX Orin 和 Jetson Thor T5000 等机器人平台具有一定优势,不过具体测试参数和方法在会上并未被详细披露。英特尔官方的表述是,通过统一栈和软硬件协同,其在相同或相近负载下可以为机器人开发者和企业提供更好的性价比,同时缓解多平台并行带来的维护压力。
从趋势上看,随着物理 AI 在工业制造、物流配送、仓储管理以及自动驾驶等领域的应用不断扩展,如何在边缘侧实现安全、稳定且具成本优势的规模化部署,成为产业链参与者共同面临的挑战。英特尔此次以 OpenVINO 物理 AI 框架为核心提出一整套软硬件方案,也被外界视为其在边缘 AI 与机器人平台领域继续与竞品正面竞争的信号,不过相关生态能否快速成熟,以及与现有机器人开发工具链的兼容性表现,仍有待后续观察和实际落地案例的检验。