并发安全和锁
互斥锁Mutex
有时候在Go代码中可能会存在多个goroutine同时操作一个资源(临界区),这种情况会发生竞态问题(数据竞态)。类比现实生活中的例子有十字路口被各个方向的的汽车竞争;还有火车上的卫生间被车厢里的人竞争。此时我们需要保证这个线程安全的问题的话我们需要使用这个互斥锁来保证这个线程安全的问题,锁再其他语言当中都是有的再这里就不过多解释了。下面举一个列子来演示一下这个go语言当中sync包里面的互斥锁。
package main
import (
"fmt"
"sync"
)
var x int64 //系统默认会初始化为对应的零值
var wg sync.WaitGroup
func Add() {
for i := 0; i < 200; i++ {
x = x + 1
}
wg.Done()
}
func main() {
wg.Add(3)
go Add()
go Add()
go Add()
wg.Wait()
fmt.Println(x)
}
此时这个x是这个临界资源多个执行流都是能够看到的,如果我们不加锁进行保护很有可能造成结果和我们预期的不一样所以我们需要加锁进行保护。
package main
import (
"fmt"
"sync"
)
var x int64 //系统默认会初始化为对应的零值
var wg sync.WaitGroup
var mtx sync.Mutex
func Add() {
defer wg.Done()
mtx.Lock()
for i := 0; i < 200; i++ {
x = x + 1
}
mtx.Unlock()
}
func main() {
wg.Add(3)
go Add()
go Add()
go Add()
wg.Wait()
fmt.Println(x)
}
读写锁
再实际情况当中我们也有可能出现这个读的多但是这个线的少此时如果我们使用这个互斥锁的话效率非常的低下。因此在读多写少的环境中,可以优先使用读写互斥锁(sync.RWMutex),它比互斥锁更加高效。sync 包中的 RWMutex 提供了读写互斥锁的封装。下面我们简单介绍一下这个读写锁。
读写锁分为两种:读锁和写锁。当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
其主要特点是这个读读不互斥,这个读写互斥。下面我们通过一个案例演示一下这个读写锁的使用。再使用之前解释一下go语言当中RWMutex的几个方法
Lock()//加写锁
UnLock()//解锁
RLock()//加读锁
RUnlock()//解锁
下面这段代码是用来验证这个两边都加的是这个写锁验证这个是互斥的
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var locker sync.RWMutex
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("A lock before")
locker.Lock()
fmt.Println("A locked")
time.Sleep(time.Second * 2)
fmt.Println("A:Unlock")
locker.Unlock()
}()
//使用读写锁
go func() {
defer wg.Done()
fmt.Println("B lock before")
locker.Lock()
fmt.Println("B locked")
time.Sleep(time.Second * 2)
fmt.Println("B:Unlock")
locker.Unlock()
}()
wg.Wait()
}
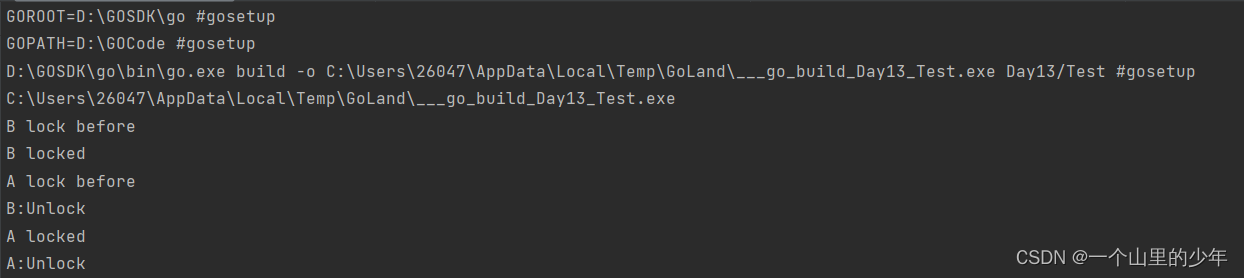
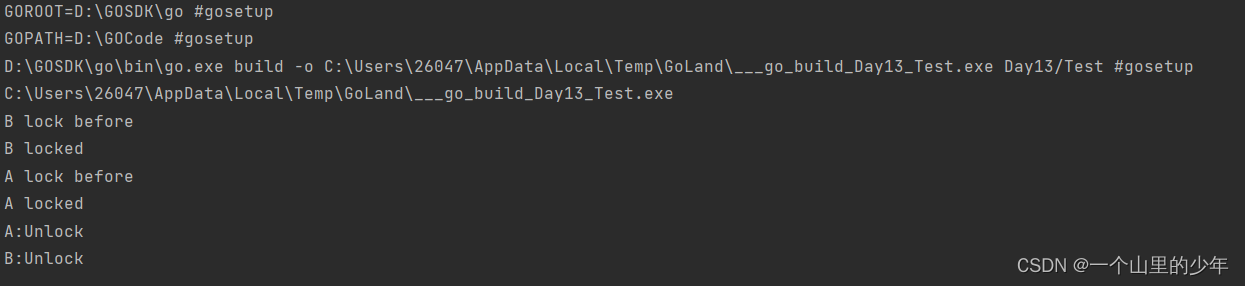
我们发现这个写写是互斥的。下面我们将其改为这个读写进一步验证我们的猜想
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var locker sync.RWMutex
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("A lock before")
locker.Lock()
fmt.Println("A locked")
time.Sleep(time.Second * 2)
fmt.Println("A:Unlock")
locker.Unlock()
}()
//使用读写锁
go func() {
defer wg.Done()
fmt.Println("B lock before")
locker.RLock()
fmt.Println("B locked")
time.Sleep(time.Second * 2)
fmt.Println("B:Unlock")
locker.RUnlock()
}()
wg.Wait()
}
通过运行结果我们可以看出来这个我们发现这个读写也是互斥的。
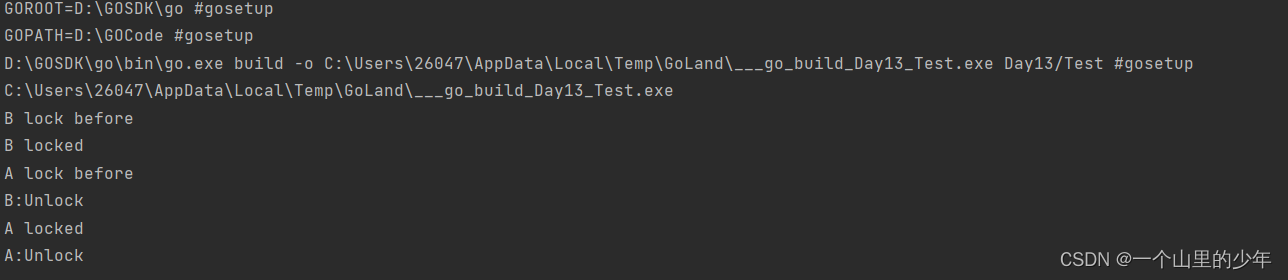
下面我们验证的是这个如果A和B如果同时加的是这个读锁是否会互斥了?
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var locker sync.RWMutex
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("A lock before")
locker.RLock()
fmt.Println("A locked")
time.Sleep(time.Second * 2)
fmt.Println("A:Unlock")
locker.RUnlock()
}()
//使用读写锁
go func() {
defer wg.Done()
fmt.Println("B lock before")
locker.RLock()
fmt.Println("B locked")
time.Sleep(time.Second * 2)
fmt.Println("B:Unlock")
locker.RUnlock()
}()
wg.Wait()
}
对应运行结果
我们发现读读是不互斥的结果和我们上面的猜想是一样的非常的一致。上述我也只演示了这个读写锁的使用。再这里再次强调一下这个需要注意的是读写锁非常适合读多写少的场景,如果读和写的操作差别不大,读写锁的优势就发挥不出来。
信号量&条件变量
再刚刚的代码当中我们提前使用了这个条件变量。再这里我们介绍一下这个信号量的使用
在代码中生硬的使用time.Sleep肯定是不合适的,Go语言中可以使用sync.WaitGroup来实现并发任务的同步。 sync.WaitGroup有以下几个方法:
(wg * WaitGroup) Add(delta int)
(wg *WaitGroup) Done()
(wg *WaitGroup) Wait()
下面解释一下这三个函数的意思是什么?下面一个一个的来解释一下其含义
- 计数器+delta
- 计数器-1
- 阻塞直到计数器变为0
注意这个信号量的本质是一把这个计数器sync.WaitGroup内部维护着一个计数器,计数器的值可以增加和减少。例如当我们启动了N 个并发任务时,就将计数器值增加N。每个任务完成时通过调用Done()方法将计数器减1。通过调用Wait()来等待并发任务执行完,当计数器值为0时,表示所有并发任务已经完成。下面我们再简单的演示一下这个使用吧上面已经使用过几次了非常的简单如果使用过其他的这个信号量的话
var wg sync.WaitGroup
func hello() {
defer wg.Done()
fmt.Println("Hello Goroutine!")
}
func main() {
wg.Add(1)
go hello() // 启动另外一个goroutine去执行hello函数
fmt.Println("main goroutine done!")
wg.Wait()
}
下面我们来看看这个条件变量的使用go语言当中的Cond。其实和其他语言当中的差不多。下面我们通过一段代码看看这个go语言当中的条件变量如何使用
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var locker sync.Mutex
var wg sync.WaitGroup
wg.Add(2)
cond := sync.NewCond(&locker)
go func() {
cond.L.Lock() //注意需要提前获取锁再wait之前
defer cond.L.Unlock()
fmt.Println("Conde wait")
cond.Wait()
fmt.Println("Cond After")
wg.Done()
}()
go func() {
defer wg.Done()
time.Sleep(time.Second * 3)
fmt.Println("notice")
//cond.Broadcast() //唤醒所有再条件变量下等待的
cond.Signal() //唤醒一个
}()
wg.Wait()
fmt.Println("main over")
}
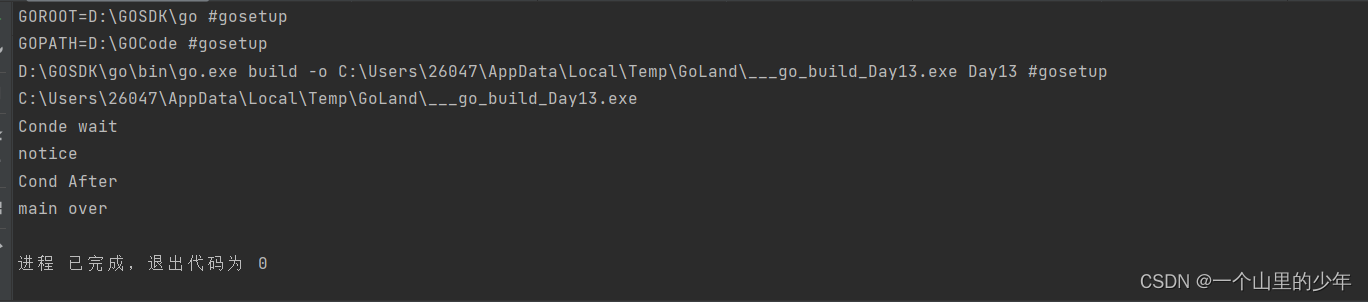
注意再使用条件变量的时候我们必须要先获取锁之后采用使用这个wait。下面我们来看看这个运行结果
单例模式&time包方法
这个单例模式再博主以前的博客当中已经写过了。再这里我们看看go语言当中的单例模式是如何进行书写的。再go语言当中利用这个sync包里面的Once
package main
import "sync"
type Singleton struct {
Name string
age int
}
var once sync.Once
var inst *Singleton
func GetInstance() *Singleton {
once.Do(func() {
inst = &Singleton{
}
})
return inst
}
func main() {
}
在编程的很多场景下我们需要确保某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等。Go语言中的sync包中提供了一个针对只执行一次场景的解决方案–sync.Once。sync.Once只有一个Do方法,其签名如下:
func (o *Once) Do(f func()) {
}
正好这个单例模式就是这样的。其他经典的写法由于这个博主再单例模式的那篇博客当中已经写了再这里就不重复了。
其实这个sync.Once里面的实现其实也是这个双重加锁。下面我们来看看这个他的实现吧
func (o *Once) Do(f func()) {
//判断是否执行过该方法,如果执行过则不执行
if atomic.LoadUint32(&o.done) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock() //进行加锁,再做一次判断,如果没有执行,则进行标志已经扫行并调用该方法
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
下面我们来学习一下这个go语言当中这个 time包里面的两个方法一个是这个After一个是这个Tick
在等待给定的一段时间后,向返回值发送当前时间,返回值是一个单向只读通道.下面我们通过一个小小的demo来展示一下他的功能
func main() {
c := make(chan int, 1)
select {
case m := <-c:
fmt.Println(m)
case d := <-time.After(5 * time.Second):
fmt.Println("time out")
fmt.Println("current Time :", d)
}
fmt.Println("main over")
}
运行发现,在等待五秒钟后,打印
第一个case中,通道c一直处于阻塞状态;第二个case中,在time.After()结束后,从返回值通道中取出一个值赋予了d,该值就是当前时间。
下面我们自己模拟实现一下这个time包里面的After是怎么实现的。其实非常的简单

//time.After的实现
func timeAfter(interval time.Duration) <-chan time.Time {
timeChannel := make(chan time.Time)
go func() {
time.Sleep(interval)
timeChannel <- time.Now()
}()
return timeChannel
}
下面我们再来看看这个time包里面的这个Tick
func tick(d Duration) <-chan Time
tick() 函数接受一个时长 d,然后它 tick() 等待 d 时长,等待时间到后,将等待完成时所处时间点写入到 channel 中并返回这个只读 channel。
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("begin")
select {
case <-time.Tick(2 * time.Second):
fmt.Println("2 second over:", time.Now().Second())
case <-time.After(7 * time.Second):
fmt.Println("5 second over, timeover", time.Now().Second())
return
}
}
上面的示例,在等待 2 秒之后,就会因为读取到了 time.Tick() 的通道数据而终止,因为 select 并未在循环内.
下面我们来看看他的这个简单的实现这个Tick
func timeTick(interval time.Duration) <-chan time.Time {
timeChannel := make(chan time.Time)
go func() {
for {
time.Sleep(interval)
timeChannel <- time.Now()
}
}()
return timeChannel
}
其实都非常的简单看起来很花里呼哨的,其实这个底层还是很简单的。下面我们探讨一下这个go语言当中的这个写循环执行的定时任务,常见的有以下三种实现方式:
首先我们看看第一种实现这个使用time包里面的sleep
for {
time.Sleep(time.Second)
fmt.Println("我在定时执行任务")
}
第二种方法time.Tick函数
t1:=time.Tick(3*time.Second)
for {
select {
case <-t1:
fmt.Println("t1定时器")
}
}
第三种方法是这个
t:=time.NewTicker(time.Second)
for {
select {
case <-t.C:
fmt.Println("t1定时器")
t.Stop()
}
}
其中Tick定时任务,也可以先使用time.Ticker函数获取Ticker结构体,然后进行阻塞监听信息,这种方式可以手动选择停止定时任务,在停止任务时,减少对内存的浪费。
现在我们知道了,Tick,Sleep,包括time.After函数,都使用的timer结构体,都会被放在同一个协程中统一处理,这样看起来使用Tick,Sleep并没有什么区别。
实际上是有区别的,Sleep是使用睡眠完成定时任务,需要被调度唤醒。Tick函数是使用channel阻塞当前协程,完成定时任务的执行。当前并不清楚golang 阻塞和睡眠对资源的消耗会有什么区别,这方面不能给出建议。
但是使用channel阻塞协程完成定时任务比较灵活,可以结合select设置超时时间以及默认执行方法,而且可以设置timer的主动关闭,以及不需要每次都生成一个timer(这方面节省系统内存,垃圾收回也需要时间)。
所以个人建议使用time.Tick完成定时任务。
协程池
本文使⽤Go语⾔实现并发的协程调度池阉割版,本⽂主要介绍协程池的基本设计思路,⽬的为深⼊浅出快速了解协程池⼯作原理,与真实的企业协程池还有很⼤差距,本⽂仅供学习参考。
一.首先我们需要知道何谓并发?go语言是怎么实现并发?
1.
同⼀时刻可以处理多个事务
2.
更加节省时间,效率更⾼
下面我们来看看这个协程池的设计思路
为什么需要协程池?虽然go语⾔在调度Goroutine已经优化的⾮常完成,
并且Goroutine作为轻量级执⾏流程,也不需要CPU调度器的切换,我们⼀般在使⽤的时候,如果想处理⼀个分⽀流程,直接go⼀下即可。但是,
如果⽆休⽌的开辟Goroutine依然会出现⾼频率的调度Groutine,那么依然会浪费很多上下⽂切换的资源,导致做⽆⽤功。所以设计⼀个Goroutine
池限制Goroutine的开辟个数在⼤型并发场景还是必要的。
和这个线程池非常的类似再这里就不过多演示
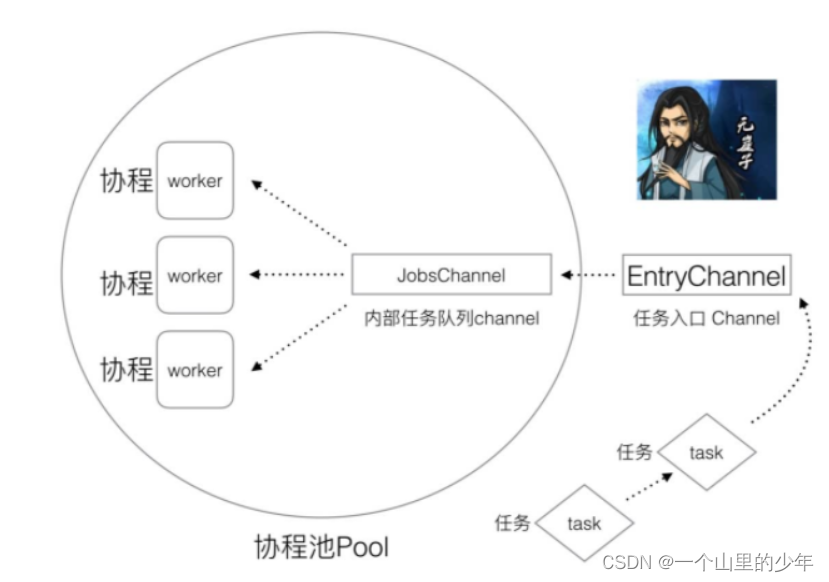
对应代码实现
package main
import (
"fmt"
"time"
)
/*
设计一个协程池
Work和Task通过Channel完成通信
*/
type Task struct {
Run func() error
//回调方法
}
func NewTask(f func() error) *Task {
t := Task{
Run: f}
return &t
}
func (t *Task) Execute() {
t.Run()
}
/*
上面是有关任务的方法
*/
type Pool struct {
//对外Task入口
EntryChannel chan *Task
//管道当中放入这个任务
//内部Task队列,JobChannel
JobsChannel chan *Task
workNum int
}
func (p *Pool) Work(WorkId int) {
//一直往Job管道当中读取任务,并执行任务
for {
task, ok := <-p.JobsChannel
if ok {
task.Execute()
fmt.Printf("协程%d执行让任务 \n", WorkId)
time.Sleep(time.Second)
}
}
}
func (p *Pool) run() {
//根据创建协程池的数目来创建协程
//从EntryChannel当中取任务将取到的任务发送给JobsChannel
for i := 0; i < p.workNum; i++ {
go p.Work(i)
}
for {
task, ok := <-p.EntryChannel
if ok {
p.JobsChannel <- task
}
}
}
// NewPool 创建协程池
func NewPool(num int) *Pool {
p := Pool{
EntryChannel: make(chan *Task),
JobsChannel: make(chan *Task),
workNum: num,
}
return &p
}
func main1() {
t := NewTask(func() error {
fmt.Println(time.Now())
return nil
})
p := NewPool(4)
go func() {
for {
p.EntryChannel <- t
}
}()
//注意这个需要写到后面
p.run()
}
/*
进程和进程之间是独立的好处一个进程死亡消耗内存
线程和线程之间的内存资源大部分是共享的。好处节省资源稳健性不强
协程实际上是更轻量级别的线程
*/