领域驱动设计(Domain-Driven Design,DDD)自Eric Evans提出以来,已成为处理复杂业务系统的核心方法论。它不仅是技术架构,更是一种以业务领域为核心的软件设计哲学。在微服务与分布式系统成为主流的今天,理解DDD为何能超越传统分层架构、如何落地,对构建高内聚、可演进的复杂系统至关重要。
1. 核心理念:DDD为何而生?
DDD源于一个基本洞察:软件的复杂性并不来自技术,而来自业务领域本身。当业务逻辑错综复杂且频繁变化时,传统的以数据表驱动或分层抽象的架构,常导致业务逻辑散落各处(如Service层、数据库存储过程、前端校验),变得难以理解和维护。代码与业务概念逐渐脱节,成为“大泥球”。
DDD的核心应对策略是建立统一的领域模型,作为业务人员与开发团队的共同语言(通用语言),并将此模型作为系统设计的核心基础。所有技术实现(数据库、框架、UI)都应围绕且服从于领域模型,而非相反。
为了让您快速理解DDD与传统架构的根本区别,下表对它们进行了核心对比:
| 维度 | 传统分层架构 (如MVC, 经典三层) | 领域驱动设计 (DDD) | 核心差异解析 |
|---|---|---|---|
| 设计驱动力 | 数据与技术。常以数据库表结构为起点,向上构建CRUD服务。 | 业务与领域。以业务领域的概念、规则、流程为起点,向下映射技术实现。 | DDD是业务驱动,传统架构是数据/技术驱动。 |
| 核心关注点 | 数据的增删改查(CRUD),技术分层的清晰性。 | 领域模型的完整性、业务规则的显式表达、领域逻辑的高内聚。 | DDD追求业务逻辑的纯粹与内聚,传统架构追求技术职责的分离。 |
| 业务逻辑位置 | 分散。可能存在于Service层、数据库触发器/存储过程、甚至前端。 | 高度内聚于领域层的实体、值对象、领域服务中。 | DDD将业务逻辑收拢在领域层,是架构上的“釜底抽薪”。 |
| 与数据库关系 | 强耦合。模型常是数据库表的直接映射(贫血模型)。 | 弱耦合。领域模型反映业务,通过仓储(Repository)模式适配持久化。 | DDD通过仓储模式解耦领域与持久化细节。 |
| 应对复杂性的方式 | 通过更细的技术分层或引入新技术框架。 | 通过限界上下文(Bounded Context) 对庞大领域进行分治,降低认知负荷。 | DDD提供了战略性的业务分解工具。 |
| 适用场景 | 业务逻辑简单、以数据管理为主的内部系统、原型开发。 | 业务逻辑复杂、需要长期演进的商业核心系统。 | DDD在复杂业务系统中价值显著,在简单系统中可能过度设计。 |
2. DDD核心分层架构详解
经典DDD分层架构将系统垂直划分为四个层次,每一层都有其明确的职责和依赖关系,确保领域核心不受技术细节污染。
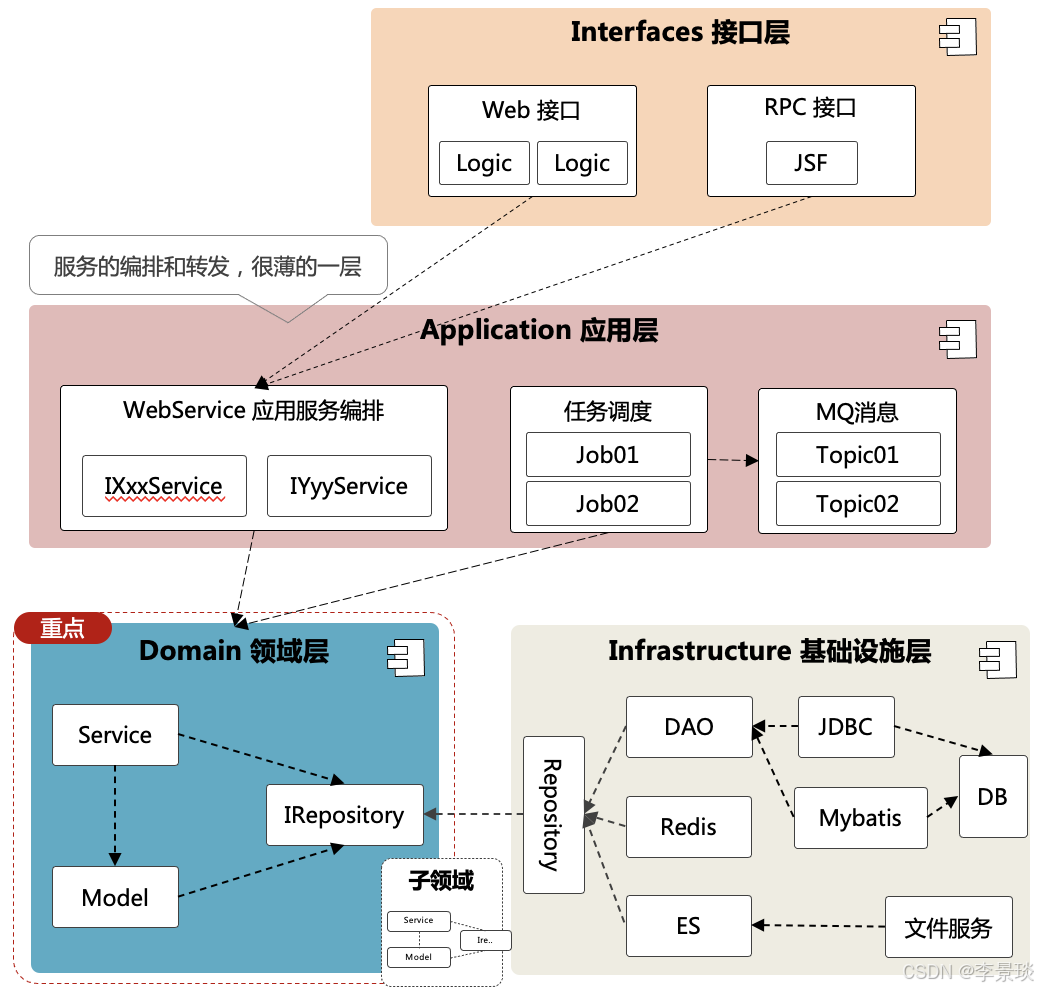
DDD4层架构目录工程结构:
- src
- it 集成测试模块
- java 集成测试代码
- resources 集成测试配置文件
- test 单元测试模块
- java 单元测试代码
- main 业务代码
- java
- interfaces 用户接口层
- facade 提供较粗粒度的调用接口,将用户请求委托给一个或多个应用服务进行处理
- rest REST API
- dubbo
- subscribe mq 事件订阅
注1:统一返回Result
注2:应该捕捉所有异常
- application 应用层
- assembler 实现 DTO 与领域对象之间的相互转换和数据交换
- event 存放事件相关代码,为了事件统一管理,将所有事件发布和订阅统一放到应用层,核心业务逻辑放到领域层
- publish 事件发布
- service 对领域服务或外部应用服务进行封装、编排和组合,对外提供粗粒度服务
- command 操作相关,必须调用领域层
- query