Gemini 3.5 Flash 已通过 Gemini 应用和Google搜索中的 AI 模式向所有用户提供使用,Google称该模型在多项维度上具备可与大型旗舰模型比肩的智能水准,同时保持 Flash 系列一贯的高速度表现。
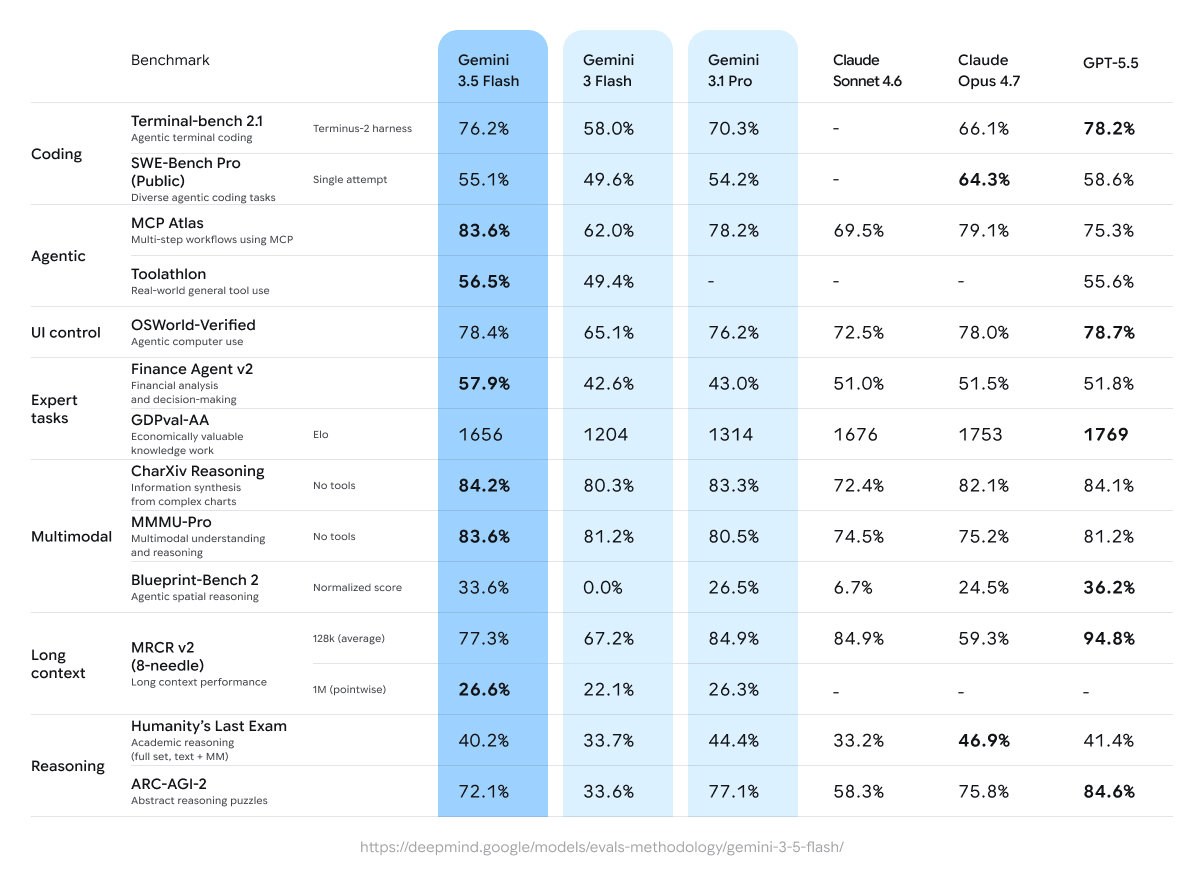
根据介绍,Gemini 3.5 Flash 是目前最强的 Gemini 代理式与代码生成模型,在复杂代码与智能体相关基准测试中甚至超越了 Gemini 3.1 Pro,并在多模态理解方面保持领先,因此也被设定为当前的默认模型。用户可以在日常搜索、应用内对话等场景中直接调用该模型,以获得更快速、更智能的回答和代码支持。
与之同时亮相的 Gemini Omni 则代表了Google在生成式视频方向上的最新尝试,这一新模型可以从任意输入生成视频,用户可以自由组合图片、音频、视频以及文本作为输入,由模型生成基于 Gemini 真实世界知识的高质量视频内容。生成完成后,用户还可以通过自然语言进行多轮对话式编辑,对视频中的细节进行修改和微调。
Gemini Omni 系列的首款模型为 Gemini Omni Flash,它支持对视频进行局部或整体修改,并可在多轮创作过程中持续保留原始场景的叙事连贯性,让用户在不断调整的同时不丢失故事主线。Google表示,该模型在对重力、动能、流体动力学等物理概念上具有更直观的理解能力,从而能够生成更加真实可信的动态场景。
在创作体验上,Gemini Omni 允许用户使用自己的声音和虚拟形象(Avatar)参与视频创作,从而生成具备个人特征的数字化分身。为应对合成内容的溯源与安全问题,所有由该模型生成的视频均会嵌入 SynthID 数字水印,用于标注和识别 AI 生成内容。
在可用性方面,Gemini Omni Flash 今日起面向全球订阅用户开放,订阅Google AI Plus、Pro 和 Ultra 方案的用户可在 Gemini 应用和 Google Flow 中直接使用该模型。同时,Google也正将这一能力免费引入 YouTube Shorts 和 YouTube Create,让更多创作者可以在主流内容平台上体验基于 Gemini 技术的视频生成功能。