理论知识见:强化学习笔记:Actor-critic_UQI-LIUWJ的博客-CSDN博客
由于actor-critic是policy gradient和DQN的结合,所以同时很多部分和policy network,DQN的代码部分很接近
pytorch笔记:policy gradient_UQI-LIUWJ的博客-CSDN博客
pytorch 笔记: DQN(experience replay)_UQI-LIUWJ的博客-CSDN博客
1 导入库 & 超参数
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import time
from torch.distributions import Categorical
GAMMA = 0.95
#奖励折扣因子
LR = 0.01
#学习率
EPISODE = 3000
# 生成多少个episode
STEP = 3000
# 一个episode里面最多多少步
TEST = 10
# 每100步episode后进行测试,测试多少个2 actor 部分
2.1 actor 基本类
class PGNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PGNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 20)
self.fc2 = nn.Linear(20, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
action_scores = self.fc2(x)
return F.softmax(action_scores,dim=1)
#PGNetwork的作用是输入某一时刻的state向量,输出是各个action被采纳的概率
#和policy gradient中的Policy一样2.2 actor 类
2.2.1 __init__
class Actor(object):
def __init__(self, env):
# 初始化
self.state_dim = env.observation_space.shape[0]
#表示某一时刻状态是几个维度组成的
#在推杆小车问题中,这一数值为4
self.action_dim = env.action_space.n
#表示某一时刻动作空间的维度(可以有几个不同的动作)
#在推杆小车问题中,这一数值为2
self.network = PGNetwork(
state_dim=self.state_dim,
action_dim=self.action_dim)
#输入S输出各个动作被采取的概率
self.optimizer = torch.optim.Adam(self.network.parameters(), lr=LR)
2.2.2 选择动作
和policy gradient中的几乎一模一样
def choose_action(self, observation):
# 选择动作,这个动作不是根据Q值来选择,而是使用softmax生成的概率来选
# 在policy gradient和A2C中,不需要epsilon-greedy,因为概率本身就具有随机性
observation = torch.from_numpy(observation).float().unsqueeze(0)
#print(state.shape)
#torch.size([1,4])
#通过unsqueeze操作变成[1,4]维的向量
probs = self.network(observation)
#Policy的返回结果,在状态x下各个action被执行的概率
m = Categorical(probs)
# 生成分布
action = m.sample()
# 从分布中采样(根据各个action的概率)
#print(m.log_prob(action))
# m.log_prob(action)相当于probs.log()[0][action.item()].unsqueeze(0)
#换句话说,就是选出来的这个action的概率,再加上log运算
return action.item()
# 返回一个元素值
'''
所以每一次select_action做的事情是,选择一个合理的action,返回这个action;
'''2.2.3 学习actor 网络
也就是学习如何更好地选择action
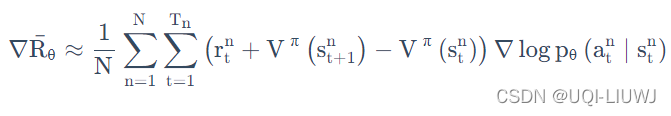
neg_log_prob 在后续的critic中会有计算的方法,相当于
def learn(self, state, action, td_error):
observation = torch.from_numpy(state).float().unsqueeze(0)
softmax_input = self.network(observation)
#各个action被采取的概率
action = torch.LongTensor([action])
neg_log_prob = F.cross_entropy(input=softmax_input, target=action)
# 反向传播(梯度上升)
# 这里需要最大化当前策略的价值
#因此需要最大化neg_log_prob * tf_error,即最小化-neg_log_prob * td_error
loss_a = -neg_log_prob * td_error
self.optimizer.zero_grad()
loss_a.backward()
self.optimizer.step()
#pytorch 老三样3 critic部分
根据actor的采样,用TD的方式计算V(s)
为了方便起见,这里没有使用target network以及experience relay,这两个可以看DQN 的pytorch代码,里面有涉及
3.1 critic 基本类
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 20)
self.fc2 = nn.Linear(20, 1)
# 这个地方和之前略有区别,输出不是动作维度,而是一维
#因为我们这里需要计算的是V(s),而在DQN中,是Q(s,a),所以那里是两维,这里是一维
def forward(self, x):
out = F.relu(self.fc1(x))
out = self.fc2(out)
return out3.2 Critic类
3.2.1 __init__
class Critic(object):
#通过采样数据,学习V(S)
def __init__(self, env):
self.state_dim = env.observation_space.shape[0]
#表示某一时刻状态是几个维度组成的
#在推杆小车问题中,这一数值为4
self.action_dim = env.action_space.n
#表示某一时刻动作空间的维度(可以有几个不同的动作)
#在推杆小车问题中,这一数值为2
self.network = QNetwork(
state_dim=self.state_dim,
action_dim=self.action_dim)
#输入S,输出V(S)
self.optimizer = torch.optim.Adam(self.network.parameters(), lr=LR)
self.loss_func = nn.MSELoss()3.2.2 训练critic 网络
def train_Q_network(self, state, reward, next_state):
#类似于DQN的5.4,不过这里没有用fixed network,experience relay的机制
s, s_ = torch.FloatTensor(state), torch.FloatTensor(next_state)
#当前状态,执行了action之后的状态
v = self.network(s) # v(s)
v_ = self.network(s_) # v(s')
# 反向传播
loss_q = self.loss_func(reward + GAMMA * v_, v)
#TD
##r+γV(S') 和V(S) 之间的差距
self.optimizer.zero_grad()
loss_q.backward()
self.optimizer.step()
#pytorch老三样
with torch.no_grad():
td_error = reward + GAMMA * v_ - v
#表示不把相应的梯度传到actor中(actor和critic是独立训练的)
return td_error4 主函数
def main():
env = gym.make('CartPole-v1')
#创建一个推车杆的gym环境
actor = Actor(env)
critic = Critic(env)
for episode in range(EPISODE):
state = env.reset()
#state表示初始化这一个episode的环境
for step in range(STEP):
action = actor.choose_action(state)
# 根据actor选择action
next_state, reward, done, _ = env.step(action)
#四个返回的内容是state,reward,done(是否重置环境),info
td_error = critic.train_Q_network(
state,
reward,
next_state)
# gradient = grad[r + gamma * V(s_) - V(s)]
#先根据采样的action,当前状态,后续状态,训练critic,以获得更准确的V(s)值
actor.learn(state, action, td_error)
# true_gradient = grad[logPi(a|s) * td_error]
#然后根据前面学到的V(s)值,训练actor,以更好地采样动作
state = next_state
if done:
break
# 每100步测试效果
if episode % 100 == 0:
total_reward = 0
for i in range(TEST):
state = env.reset()
for j in range(STEP):
#env.render()
#渲染环境,如果你是在服务器上跑的,只想出结果,不想看动态推杆过程的话,可以注释掉
action = actor.choose_action(state)
#采样了一个action
state, reward, done, _ = env.step(action)
#四个返回的内容是state,reward,done(是否重置环境),info
total_reward += reward
if done:
break
ave_reward = total_reward/TEST
print('episode: ', episode, 'Evaluation Average Reward:', ave_reward)
if __name__ == '__main__':
time_start = time.time()
main()
time_end = time.time()
print('Total time is ', time_end - time_start, 's')
'''
episode: 0 Evaluation Average Reward: 17.2
episode: 100 Evaluation Average Reward: 10.6
episode: 200 Evaluation Average Reward: 11.4
episode: 300 Evaluation Average Reward: 10.7
episode: 400 Evaluation Average Reward: 9.3
episode: 500 Evaluation Average Reward: 9.5
episode: 600 Evaluation Average Reward: 9.5
episode: 700 Evaluation Average Reward: 9.6
episode: 800 Evaluation Average Reward: 9.9
episode: 900 Evaluation Average Reward: 8.9
episode: 1000 Evaluation Average Reward: 9.3
episode: 1100 Evaluation Average Reward: 9.8
episode: 1200 Evaluation Average Reward: 9.3
episode: 1300 Evaluation Average Reward: 9.0
episode: 1400 Evaluation Average Reward: 9.4
episode: 1500 Evaluation Average Reward: 9.3
episode: 1600 Evaluation Average Reward: 9.1
episode: 1700 Evaluation Average Reward: 9.0
episode: 1800 Evaluation Average Reward: 9.6
episode: 1900 Evaluation Average Reward: 8.8
episode: 2000 Evaluation Average Reward: 9.4
episode: 2100 Evaluation Average Reward: 9.2
episode: 2200 Evaluation Average Reward: 9.4
episode: 2300 Evaluation Average Reward: 9.2
episode: 2400 Evaluation Average Reward: 9.3
episode: 2500 Evaluation Average Reward: 9.5
episode: 2600 Evaluation Average Reward: 9.6
episode: 2700 Evaluation Average Reward: 9.2
episode: 2800 Evaluation Average Reward: 9.1
episode: 2900 Evaluation Average Reward: 9.6
Total time is 41.6014940738678 s
'''