
ultralytics.models.yolo.world这个模块提供了用于训练 YOLO-World 模型的训练器类。YOLO-World 是一种结合视觉和文本特征的多模态目标检测模型。该模块包含两个主要的训练器类:
train.py
train_world.py-
WorldTrainer:用于在闭集数据集上微调 YOLO-World 模型 -
WorldTrainerFromScratch:用于在开集数据集上从头开始训练 YOLO-World 模型
YOLO-World 训练器模块是 Ultralytics 框架中专门用于训练多模态目标检测模型的核心组件。该模块提供了两种训练器,分别支持不同场景下的 YOLO-World 模型训练:
-
WorldTrainer - 用于在闭集数据集上微调预训练的 YOLO-World 模型
-
WorldTrainerFromScratch - 用于在开集数据集上从头开始训练 YOLO-World 模型
这两个训练器都建立在基础目标检测训练器(DetectionTrainer)之上,通过添加文本处理、多模态数据融合和专门的缓存机制,实现了视觉与语言信息的联合训练。模块的核心设计理念是将传统的视觉目标检测与文本语义理解相结合。YOLO-World 模型不是简单地检测预定义类别的物体,而是能够理解任意文本描述并检测对应的物体。这种能力通过以下关键设计实现:
-
文本嵌入生成:将文本类别名称转换为固定维度的向量表示
-
特征融合:在模型内部将图像特征与文本特征进行有效融合
-
动态类别支持:训练时可以根据文本描述动态调整检测类别
整体架构示意如下所示:

训练数据准备流程如下所示:

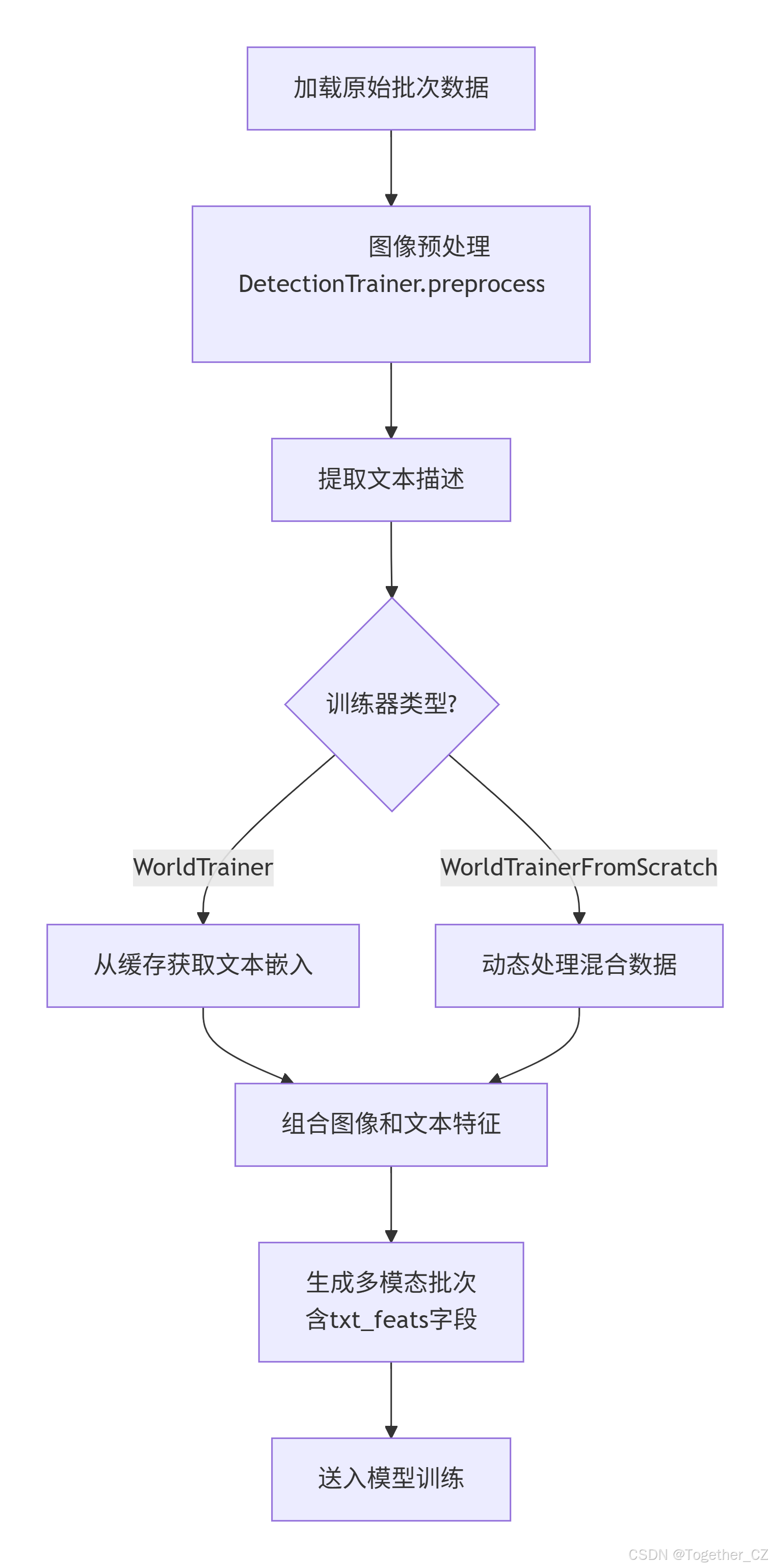
批次数据处理流程如下:
基础概念
1. 文本嵌入(Text Embeddings)
文本嵌入是将文本转换为数值向量的过程,使得计算机可以处理和理解文本。在 YOLO-World 中,文本嵌入用于将类别名称转换为向量,这些向量与图像特征结合,使模型能够理解文本描述并检测对应的物体。
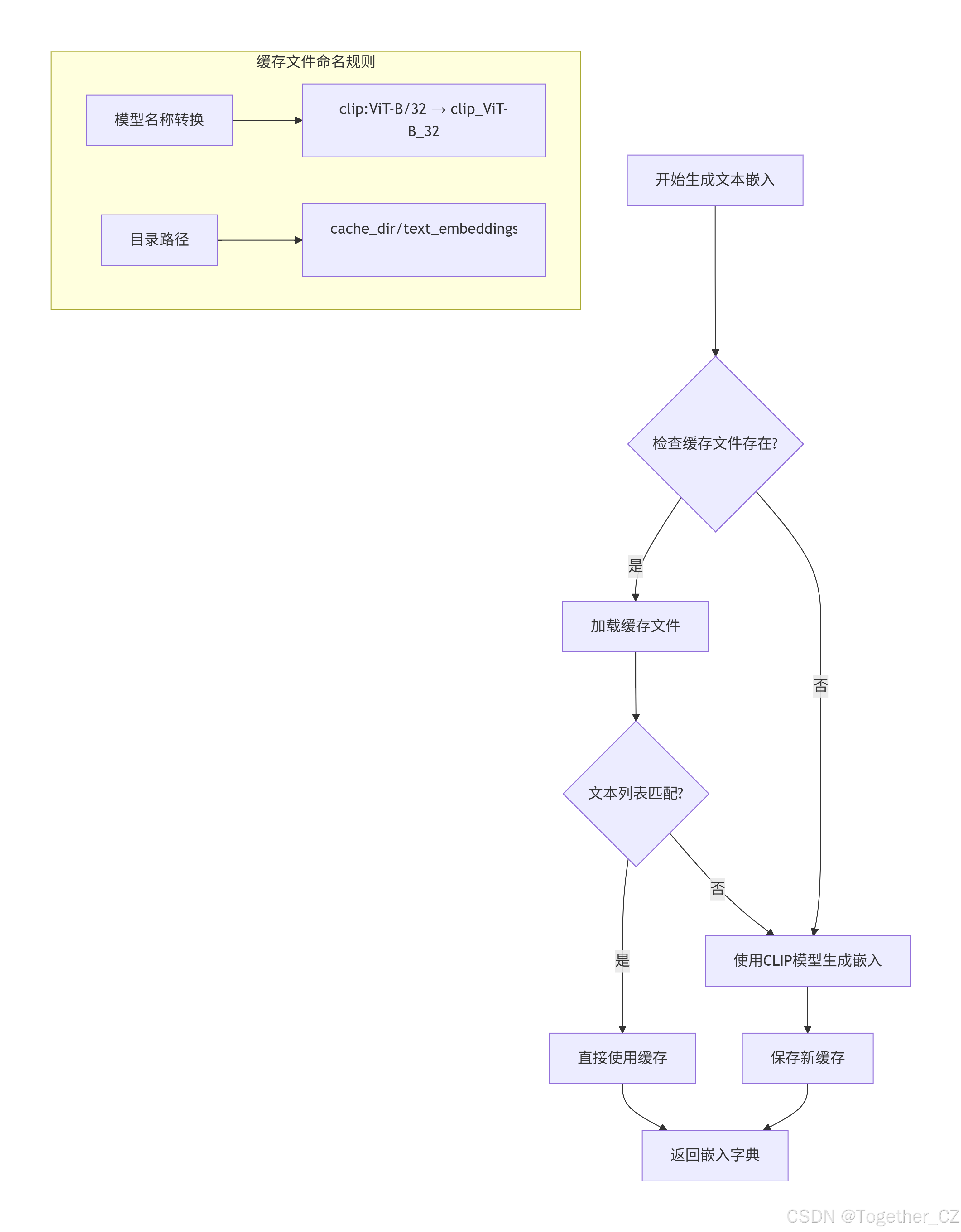
文本嵌入缓存策略如下:
2. 闭集 vs 开集
-
闭集(Closed-set):模型在训练时见过的类别上进行测试。例如,在 COCO 数据集上训练,在 COCO 数据集上测试。
-
开集(Open-set):模型可以在训练时未见过的类别上进行测试。YOLO-World 支持开集检测,因为它可以理解文本描述并检测任意类别的物体。
3. Grounding 数据集
Grounding 数据集包含图像和文本描述的对齐信息,常用于视觉-语言任务。在 YOLO-World 中,grounding 数据用于训练模型理解文本描述与图像中物体的对应关系。
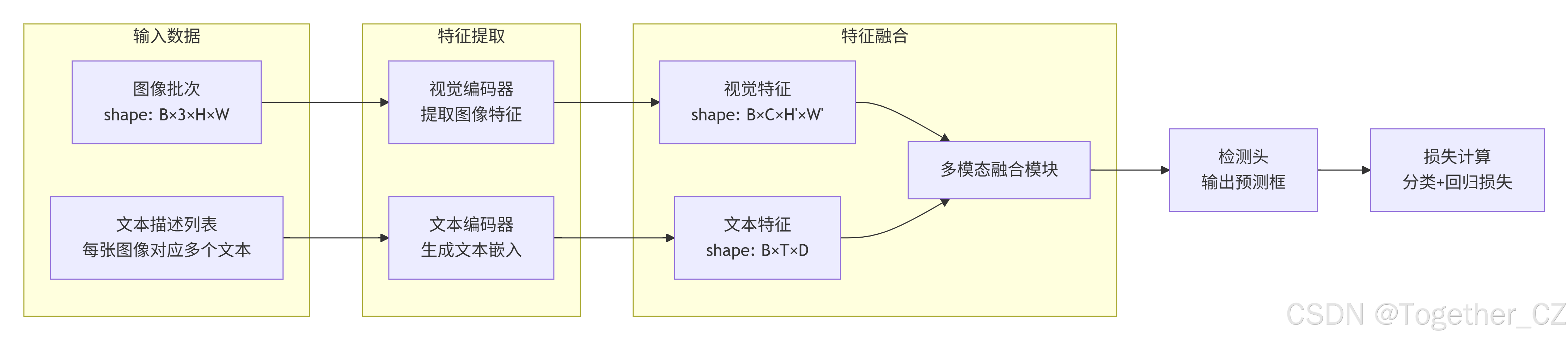
4. 多模态(Multi-modal)
多模态指的是结合多种类型的数据,如图像和文本。YOLO-World 是一个多模态模型,因为它同时处理图像和文本输入。
多模态数据融合示意如下:
5. 缓存机制
代码中使用了缓存机制来存储文本嵌入,这样可以避免每次训练时都重新计算相同的文本嵌入,从而显著提高训练效率。
代码详读
1. on_pretrain_routine_end 函数
这个回调函数在预训练例程结束时被调用,主要用于设置模型的类别名称和文本编码器。它从测试数据集中提取所有类别名称,并设置到模型中,为后续的评估做准备。on_pretrain_routine_end 函数是一个重要的回调函数,它在预训练例程结束时自动执行。其主要功能是从验证数据集中提取类别名称,并将这些名称设置到模型中。这个过程对于 YOLO-World 模型特别重要,因为模型需要知道在评估阶段要关注哪些文本类别。
该函数执行以下步骤:
-
从测试数据集的配置中提取所有类别名称
-
处理名称格式(去掉路径前缀)
-
调用模型的
set_classes方法设置类别 -
禁用 CLIP 模型缓存以节省内存
代码详读如下:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# 从 Python 的未来版本导入注解功能,允许使用更灵活的注解语法
from __future__ import annotations
# 导入 itertools 模块,用于处理迭代器和组合操作
import itertools
# 导入 Path 类,用于处理文件路径
from pathlib import Path
# 导入 Any 类型,用于类型注解中的任意类型
from typing import Any
# 导入 PyTorch 深度学习框架
import torch
# 从 ultralytics 项目中导入相关模块
# 导入构建 YOLO 数据集的函数
from ultralytics.data import build_yolo_dataset
# 导入目标检测训练器基类
from ultralytics.models.yolo.detect import DetectionTrainer
# 导入 WorldModel 模型类
from ultralytics.nn.tasks import WorldModel
# 导入工具类:数据集目录路径、默认配置、日志记录器、进程排名
from ultralytics.utils import DATASETS_DIR, DEFAULT_CFG, LOGGER, RANK
# 导入 PyTorch 工具函数,用于解包模型
from ultralytics.utils.torch_utils import unwrap_model
# 再次导入 build_yolo_dataset,以及 YOLO 拼接数据集类和构建 grounding 数据集的函数
from ultralytics.data import YOLOConcatDataset, build_grounding, build_yolo_dataset
# 导入检查检测数据集的工具函数
from ultralytics.data.utils import check_det_dataset
# 导入 WorldTrainer 类(当前模块的主要类)
from ultralytics.models.yolo.world import WorldTrainer
def on_pretrain_routine_end(trainer) -> None:
"""
在预训练例程结束时设置模型类别和文本编码器
"""
# 检查当前进程是否为 rank -1(单进程)或 rank 0(主进程)
if RANK in {-1, 0}:
# 为评估设置类别名称
# 从测试数据集中提取所有名称,并取第一个斜杠前的部分作为类别名
names = [name.split("/", 1)[0] for name in list(trainer.test_loader.dataset.data["names"].values())]
# 解包模型(如果使用了数据并行或模型并行),然后设置类别名称
# cache_clip_model=False 表示不缓存 CLIP 模型
unwrap_model(trainer.ema.ema).set_classes(names, cache_clip_model=False)
2. WorldTrainer 类
WorldTrainer 类继承自 DetectionTrainer,专门用于在闭集数据集上微调 YOLO-World 模型。它处理文本嵌入的生成和缓存,以加速多模态数据的训练。
微调训练流程如下所示:

代码详读:
class WorldTrainer(DetectionTrainer):
"""
用于在闭集数据集上微调 YOLO-World 模型的训练器类
"""
def __init__(self, cfg=DEFAULT_CFG, overrides: dict[str, Any] | None = None, _callbacks=None):
"""
使用给定的参数初始化 WorldTrainer 对象
"""
# 如果未提供覆盖参数,则初始化为空字典
if overrides is None:
overrides = {}
# 断言检查:确保不使用模型编译(compile=False)
# YOLO-World 训练需要禁用模型编译
assert not overrides.get("compile"), f"Training with 'model={overrides['model']}' requires 'compile=False'"
# 调用父类 DetectionTrainer 的初始化方法
super().__init__(cfg, overrides, _callbacks)
# 初始化文本嵌入缓存为 None
self.text_embeddings = None
def get_model(self, cfg=None, weights: str | None = None, verbose: bool = True) -> WorldModel:
"""
返回使用指定配置和权重初始化的 WorldModel
"""
# 注意:这里的 `nc` 是单张图像中不同文本样本的最大数量,而不是实际的类别数量 `nc`
# 注意:按照官方配置,目前将 nc 硬编码为 80
model = WorldModel(
# 如果 cfg 是字典类型,则使用其中的 yaml_file,否则直接使用 cfg
cfg["yaml_file"] if isinstance(cfg, dict) else cfg,
# 使用数据配置中的通道数
ch=self.data["channels"],
# 使用数据配置中的类别数,但不超过 80
nc=min(self.data["nc"], 80),
# 仅在单进程训练时(RANK == -1)显示模型信息
verbose=verbose and RANK == -1,
)
# 如果提供了权重文件路径,则加载预训练权重
if weights:
model.load(weights)
# 添加回调函数:在预训练例程结束时调用 on_pretrain_routine_end 函数
self.add_callback("on_pretrain_routine_end", on_pretretrain_routine_end)
# 返回初始化好的模型
return model
def build_dataset(self, img_path: str, mode: str = "train", batch: int | None = None):
"""
为训练或验证构建 YOLO 数据集
"""
# 计算最大步幅(stride),用于调整图像大小和锚框
# 如果模型存在,获取其最大步幅,否则使用 32
gs = max(int(unwrap_model(self.model).stride.max() if self.model else 0), 32)
# 构建 YOLO 数据集
dataset = build_yolo_dataset(
self.args, # 训练参数
img_path, # 图像路径
batch, # 批大小
self.data, # 数据配置
mode=mode, # 模式:train 或 val
# 验证模式下使用矩形训练(rect=True),训练模式下不使用
rect=mode == "val",
stride=gs, # 步幅
# 训练模式下启用多模态(处理文本数据)
multi_modal=mode == "train"
)
# 如果是训练模式,设置文本嵌入缓存以加速训练
if mode == "train":
# 将数据集放入列表中传递给 set_text_embeddings 方法
self.set_text_embeddings([dataset], batch)
# 返回构建的数据集
return dataset
def set_text_embeddings(self, datasets: list[Any], batch: int | None) -> None:
"""
为数据集设置文本嵌入以加速训练,通过缓存类别名称
"""
# 初始化文本嵌入字典
text_embeddings = {}
# 遍历所有数据集
for dataset in datasets:
# 检查数据集是否有 'category_names' 属性
if not hasattr(dataset, "category_names"):
# 如果没有该属性,跳过此数据集
continue
# 生成当前数据集的文本嵌入并更新到字典中
# 使用数据集的图像路径的父目录作为缓存目录
text_embeddings.update(
self.generate_text_embeddings(
list(dataset.category_names), # 类别名称列表
batch, # 批大小
cache_dir=Path(dataset.img_path).parent # 缓存目录
)
)
# 将生成的文本嵌入保存到训练器实例中
self.text_embeddings = text_embeddings
def generate_text_embeddings(self, texts: list[str], batch: int, cache_dir: Path) -> dict[str, torch.Tensor]:
"""
为文本样本列表生成文本嵌入
"""
# 指定使用的 CLIP 模型
model = "clip:ViT-B/32"
# 构建缓存文件路径:将模型名称中的特殊字符替换为下划线
cache_path = cache_dir / f"text_embeddings_{model.replace(':', '_').replace('/', '_')}.pt"
# 检查缓存文件是否存在
if cache_path.exists():
# 如果存在,从缓存加载
LOGGER.info(f"从 '{cache_path}' 读取已存在的缓存")
# 加载缓存的文本映射
txt_map = torch.load(cache_path, map_location=self.device)
# 检查缓存的文本与当前文本是否完全匹配(排序后比较)
if sorted(txt_map.keys()) == sorted(texts):
# 如果匹配,直接返回缓存的结果
return txt_map
# 如果缓存不存在或不匹配,生成新的文本嵌入
LOGGER.info(f"将文本嵌入缓存到 '{cache_path}'")
# 确保模型已初始化
assert self.model is not None
# 获取文本嵌入:解包模型并调用 get_text_pe 方法
txt_feats = unwrap_model(self.model).get_text_pe(texts, batch, cache_clip_model=False)
# 将文本和对应的嵌入组合成字典
# squeeze(0) 移除批次维度,因为每个文本只有一个嵌入
txt_map = dict(zip(texts, txt_feats.squeeze(0)))
# 将文本嵌入字典保存到缓存文件
torch.save(txt_map, cache_path)
# 返回文本嵌入字典
return txt_map
def preprocess_batch(self, batch: dict[str, Any]) -> dict[str, Any]:
"""
为 YOLO-World 训练预处理一批图像和文本数据
"""
# 首先调用父类的预处理方法处理图像数据
batch = DetectionTrainer.preprocess_batch(self, batch)
# 添加文本特征
# 使用 itertools.chain 将 batch["texts"] 中的所有列表连接成一个平面列表
texts = list(itertools.chain(*batch["texts"]))
# 从文本嵌入缓存中获取每个文本对应的嵌入
# 将每个文本的嵌入放入一个列表中,然后堆叠成张量
txt_feats = torch.stack([self.text_embeddings[text] for text in texts]).to(
# 将张量移动到指定设备(GPU 或 CPU)
self.device,
# 如果设备是 CUDA(GPU),使用非阻塞传输以加速
non_blocking=self.device.type == "cuda"
)
# 将文本嵌入重塑为合适的形状
# 形状为:[批次大小, 文本数量, 嵌入维度]
batch["txt_feats"] = txt_feats.reshape(len(batch["texts"]), -1, txt_feats.shape[-1])
# 返回包含图像和文本特征的批次数据
return batch
使用实例如下:
from ultralytics.models.yolo.world import WorldTrainer
# 设置训练参数
args = dict(model="yolov8s-world.pt", data="coco8.yaml", epochs=3)
# 创建训练器
trainer = WorldTrainer(overrides=args)
# 开始训练
trainer.train()3. WorldTrainerFromScratch 类
WorldTrainerFromScratch 类继承自 WorldTrainer,专门用于在开集数据集上从头开始训练 YOLO-World 模型。它支持混合数据集,包括目标检测数据集和 grounding 数据集。
完整训练流程如下所示:
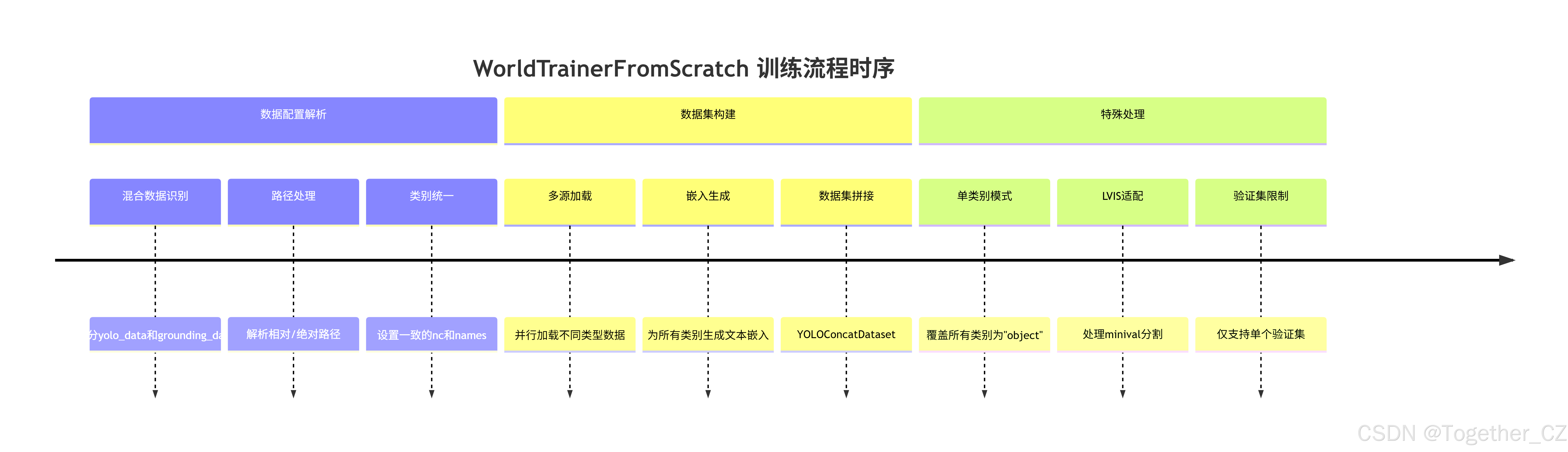
代码详读:
class WorldTrainerFromScratch(WorldTrainer):
"""
用于在开集数据集上从头开始训练世界模型的类
"""
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
"""
初始化 WorldTrainerFromScratch 对象
"""
# 如果未提供覆盖参数,则初始化为空字典
if overrides is None:
overrides = {}
# 调用父类 WorldTrainer 的初始化方法
super().__init__(cfg, overrides, _callbacks)
def build_dataset(self, img_path, mode="train", batch=None):
"""
为训练或验证构建 YOLO 数据集(支持混合数据集)
"""
# 计算最大步幅(stride)
gs = max(int(unwrap_model(self.model).stride.max() if self.model else 0), 32)
# 如果不是训练模式,直接构建标准的 YOLO 数据集
if mode != "train":
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=False, stride=gs)
# 训练模式:处理混合数据集
datasets = [
# 对于字符串类型的路径,构建标准 YOLO 数据集
build_yolo_dataset(self.args, im_path, batch, self.training_data[im_path], stride=gs, multi_modal=True)
if isinstance(im_path, str)
# 对于字典类型的路径(grounding 数据),构建 grounding 数据集
else build_grounding(
# 从验证集中获取 `nc` 作为文本样本的最大数量,以保持训练一致性
self.args, # 训练参数
im_path["img_path"], # 图像路径
im_path["json_file"], # JSON 标注文件路径
batch, # 批大小
stride=gs, # 步幅
max_samples=self.data["nc"], # 最大样本数(从验证集获取)
)
# 遍历 img_path 中的所有路径
for im_path in img_path
]
# 设置文本嵌入缓存以加速训练
self.set_text_embeddings(datasets, batch)
# 如果只有一个数据集,直接返回该数据集
# 如果有多个数据集,使用 YOLOConcatDataset 将它们连接起来
return YOLOConcatDataset(datasets) if len(datasets) > 1 else datasets[0]
def get_dataset(self):
"""
从数据字典中获取训练和验证路径
"""
# 初始化最终数据字典
final_data = {}
# 获取数据配置
data_yaml = self.args.data
# 检查训练和验证数据集是否存在
assert data_yaml.get("train", False), "未找到训练数据集"
assert data_yaml.get("val", False), "未找到验证数据集"
# 处理 YOLO 检测数据集
# 遍历 train 和 val,检查每个数据集
data = {k: [check_det_dataset(d) for d in v.get("yolo_data", [])] for k, v in data_yaml.items()}
# 验证:目前只支持在 1 个数据集上进行验证
assert len(data["val"]) == 1, f"目前只支持在 1 个数据集上进行验证,但得到了 {len(data['val'])} 个"
# 根据数据集类型确定验证分割
# 如果是 LVIS 数据集,使用 "minival",否则使用 "val"
val_split = "minival" if "lvis" in data["val"][0]["val"] else "val"
# 处理 LVIS 数据集的 minival 路径
for d in data["val"]:
# 如果 minival 字段不存在(对于 LVIS 数据集)
if d.get("minival") is None:
continue
# 构建完整的 minival 路径
d["minival"] = str(d["path"] / d["minival"])
# 处理训练和验证数据
for s in {"train", "val"}:
# 获取标准 YOLO 数据集的路径
# 训练时使用 "train" 分割,验证时使用 val_split 确定的分割
final_data[s] = [d["train" if s == "train" else val_split] for d in data[s]]
# 保存 grounding 数据(如果存在)
grounding_data = data_yaml[s].get("grounding_data")
if grounding_data is None:
continue
# 确保 grounding_data 是列表形式
grounding_data = grounding_data if isinstance(grounding_data, list) else [grounding_data]
# 处理每个 grounding 数据集
for g in grounding_data:
# 验证 grounding 数据应该是字典格式
assert isinstance(g, dict), f"Grounding 数据应以字典格式提供,但得到了 {type(g)}"
# 检查并处理 grounding 数据的路径
for k in {"img_path", "json_file"}:
path = Path(g[k])
# 如果路径不存在且不是绝对路径
if not path.exists() and not path.is_absolute():
# 使用相对于 DATASETS_DIR 的路径
g[k] = str((DATASETS_DIR / g[k]).resolve())
# 将 grounding 数据添加到最终数据中
final_data[s] += grounding_data
# 只使用第一个验证数据集(因为目前只支持一个验证集)
data["val"] = data["val"][0]
final_data["val"] = final_data["val"][0]
# 注意:为了使训练正常工作,设置 `nc` 和 `names`
# 使用验证数据集的类别数和名称
final_data["nc"] = data["val"]["nc"]
final_data["names"] = data["val"]["names"]
# 注意:添加 LVIS 路径
final_data["path"] = data["val"]["path"]
final_data["channels"] = data["val"]["channels"]
# 将最终数据保存到实例属性中
self.data = final_data
# 如果启用单类别训练,覆盖类别名称
if self.args.single_cls:
LOGGER.info("使用单类别覆盖类别名称")
self.data["names"] = {0: "object"} # 所有类别都视为 "object"
self.data["nc"] = 1 # 类别数设置为 1
# 为每个训练数据集创建训练数据映射
self.training_data = {}
for d in data["train"]:
# 如果启用单类别训练,也更新训练数据的类别信息
if self.args.single_cls:
d["names"] = {0: "object"}
d["nc"] = 1
# 将训练路径映射到对应的数据配置
self.training_data[d["train"]] = d
# 返回最终数据
return final_data
def plot_training_labels(self):
"""
跳过 YOLO-World 训练的标签绘图
"""
# 空方法,不执行任何操作
pass
def final_eval(self):
"""
为 YOLO-World 模型执行最终评估和验证
"""
# 获取验证数据集配置
val = self.args.data["val"]["yolo_data"][0]
# 设置验证器的参数
self.validator.args.data = val # 验证数据集
# 根据数据集类型设置分割类型
self.validator.args.split = "minival" if isinstance(val, str) and "lvis" in val else "val"
# 调用父类的 final_eval 方法执行最终评估
return super().final_eval()使用实例如下:
from ultralytics import YOLOWorld
# 准备数据配置
data = dict(
train=dict(
yolo_data=["Objects365.yaml"], # 标准目标检测数据集
grounding_data=[ # grounding 数据集
dict(
img_path="flickr30k/images",
json_file="flickr30k/final_flickr_separateGT_train.json",
),
dict(
img_path="GQA/images",
json_file="GQA/final_mixed_train_no_coco.json",
),
],
),
val=dict(yolo_data=["lvis.yaml"]), # 验证数据集
)
# 创建模型
model = YOLOWorld("yolov8s-worldv2.yaml")
# 使用 WorldTrainerFromScratch 进行训练
model.train(data=data, trainer=WorldTrainerFromScratch)两种训练模式对比详情如下:
| 特性 | WorldTrainer | WorldTrainerFromScratch |
|---|---|---|
| 适用场景 | 闭集微调 | 开集从头训练 |
| 数据支持 | 标准检测数据集 | 混合数据集(检测+grounding) |
| 类别处理 | 固定类别 | 动态类别 |
| 缓存策略 | 强依赖缓存 | 动态生成+缓存 |
| 验证设置 | 标准验证 | 支持LVIS minival |
| 单类别模式 | 支持 | 支持且更复杂 |
完整计算执行流程如下:
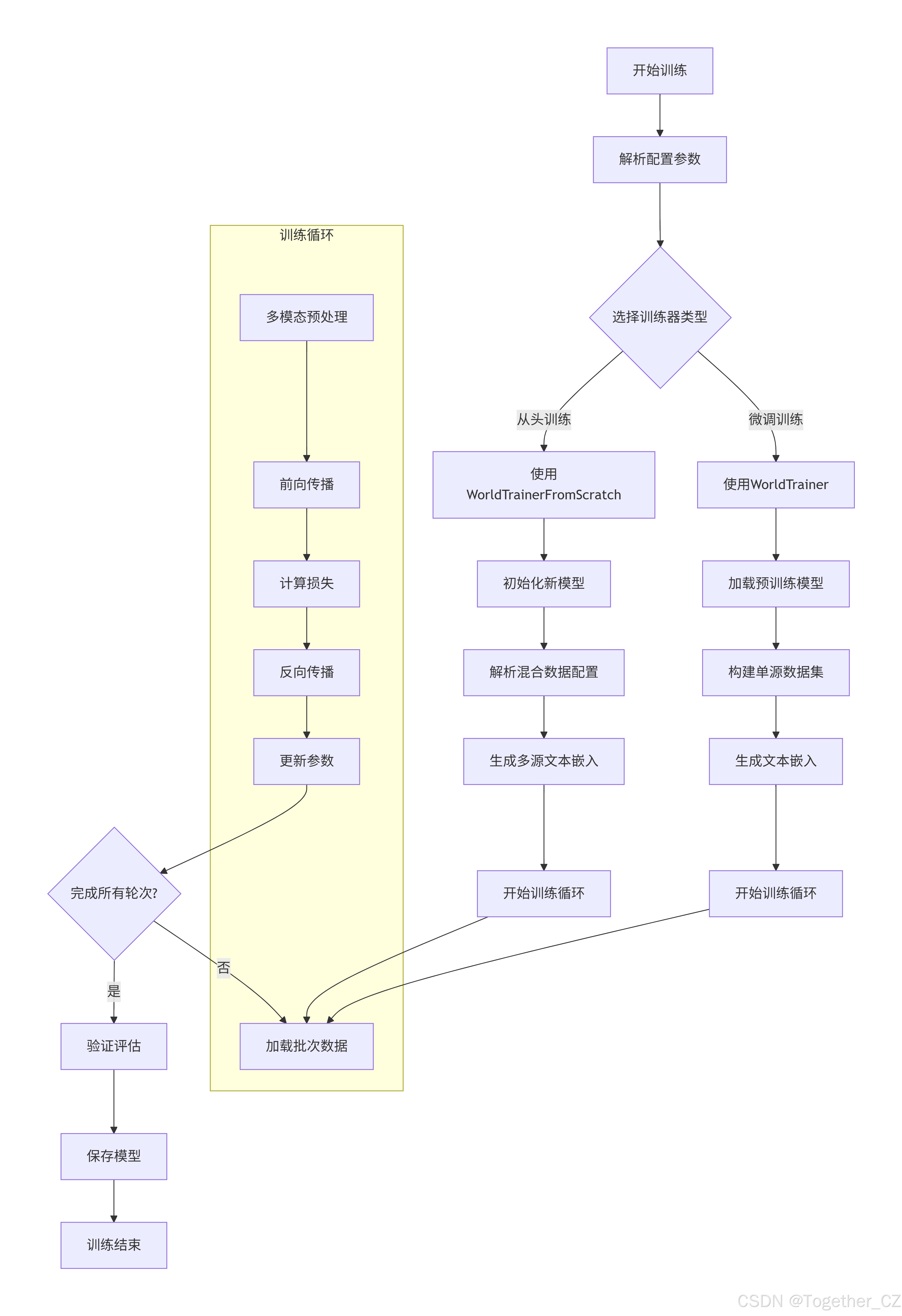
WorldTrainer 适用场景
-
闭集目标检测:在已知类别集合上微调模型
-
资源有限环境:可以利用预训练权重快速收敛
-
标准数据集:COCO、VOC 等标准格式的数据集
-
快速原型开发:需要快速验证模型性能的场景
WorldTrainerFromScratch 适用场景
-
开集目标检测:需要检测训练时未见过的类别
-
多源数据训练:同时使用多种类型的数据集
-
自定义类别:有特定领域或应用场景的类别需求
-
研究开发:需要探索新的多模态学习方法